Как я разработала программу, которая распознаёт заявки клиентов, сопоставляет товары с базой 1С и сокращает обработку заказа из 100 позиций с 30 минут до 2 минут.
Осенью 2025 года мне прилетела задача от импортёра инструментов — Инструментально-подшипниковой компании (ИПК). Нужно было сделать программу, которая номенклатуру из заявок клиентов переводила бы в формат компании, чтобы её можно было сразу вставить в 1С.
Дело в том, что клиенты этой компании присылали заявки в самом разнообразном виде. Например:
Сверла ф5 - 1, ф10 - 3...
И стандартное сопоставление номенклатуры в 1С это распознать не могло. Функционал номенклатуры поставщиков в этом случае тоже не работал, потому что клиент просто копировал позиции из какой-нибудь тендерной заявки и присылал это в ИПК.
Разумеется, указание позиций было, мягко говоря, разнообразным.
Так как заявок было очень много, а позиций в них обычно 20+, то у ИПК заявки забивали 8 офис-менеджеров, чтобы не тратить ценный ресурс менеджеров по продажам. Руководство, конечно, хотело всё это дело автоматизировать.
При этом у всех было понимание, что сопоставлять позиции стандартными средствами вряд ли получится. Слишком уж по-разному они указываются.
Но когда на арену вышли нейросети... Тут начались мысли, что они действительно могут помочь избавить компанию от этой рутины.
С чего всё началось
Мне об этой идее — разработать программу для сопоставления номенклатуры — рассказали просто в дружеской беседе. Я покивала, но ничего особо предложить не могла.
Я знаю Битрикс, 1С, но разработать с нуля программу с AI... Это были не мои компетенции на тот момент.
Но моя экспериментаторская натура взяла верх, и я на шару написала Claude техническое задание на эту программу и спросила, как бы он её реализовал.
Изначально AI я не упоминала. Мне просто было интересно, а как вообще такие задачи решают.
Claude предложил написать несложное приложение на Python с несколькими библиотеками для нечеткого сопоставления слов, типа FuzzyWuzzy, и накоплением базы сопоставлений.
Я обрадовалась, захлопала в ладоши и попросила написать мне такое приложеньице.
И он написал.
Оно даже было рабочим в какой-то степени. Хотя я бы сказала, что в нём стоило надеяться только на накопление базы ручных сопоставлений: когда база наберётся приличная, позиции вдруг начнут сопоставляться лучше.
Я решила, что это лишь первый шаг, и пошла дальше.
К этому моменту я уже договорилась с клиентом: если мне удастся сделать реально рабочее приложение, мне его оплатят.
Для самой меня это был вызов. До этого я с нейросетями делала только сайты и писала на языках, которые сама знаю. А тут Python и Claude Code как мой верный друг и программист.
Хотя последний часто не мог разрулить все проблемы, и мне приходилось лезть в код самой. Особенно это касалось визуала. Но эту-то часть я и без Claude знала ;-)
В целом я продумывала архитектуру, а Claude писал код. Для себя я поняла, что это мой идеальный мир. Мне гораздо интереснее придумать, как что должно работать, чем писать код руками.
Появился Matcher
Но вернёмся к Matcher. Так Claude назвал мою программу, и это название прижилось.
Сначала я поняла, что мне нужен многопользовательский режим и веб-версия, которая легко развернётся на любом сервере. Поэтому дальше я шла в связке с Docker.
Появился backend на Python, frontend на React и база данных PostgreSQL.
Уже красиво. Офис-менеджеры все смогут работать.
За маленьким но: программа всё так же сопоставляла 1%.
Первая попытка с нейросетями
Дальше решили прикрутить нейросети.
Разворачивать нейросеть для сопоставления у себя было невыгодно. Поэтому выбор пал на облачные решения.
Так как клиент в России, то сначала выбирали из YandexGPT и GigaChat. Я решила попробовать YandexGPT. Вроде как-то посерьёзнее.
Первая идея — кидать сразу всю номенклатуру нейросети для выбора подходящего варианта — была отвергнута.
У клиента около 8 тысяч позиций. Это уйма токенов, плюс огромное количество времени на каждый запрос.
Надо было действовать как-то иначе.
Claude опять подсказал, что нашу задачу сопоставления традиционно решают с помощью Embeddings. Это когда слова переводят в числовые векторы, по схожести которых идёт дальнейшее сопоставление.
Ну ок.
В Yandex Cloud зарегистрировалась. Embeddings получила. Попробовали сопоставить...
Ну 1% превратился, может, в 5%.
Отдельное приключение — распознавание заявки
Плюс была большая проблема с расшифровкой текста заказа.
Он мог быть написан вообще как угодно: таблица, текст, обобщающее слово, а дальше перечисление диаметров и моделей.
Короче, одна расшифровка заказа была отдельным приключением.
Поэтому я решила отправлять текст заказа на расшифровку в YandexGPT.
Он худо-бедно, с большим количеством косяков стал расшифровывать. Каждый косяк фиксировался и добавлялся в промпт.
Становилось лучше, но не намного.
Так как Embeddings работали плохо, то после Embeddings я решила отправлять получившийся топ-10 позиций в YandexGPT для выбора наилучшего варианта.
Стало получше. Теперь, может, 10% сопоставлялось.
Но из-за получения Embeddings на каждую позицию заказа это всё равно было невероятно долго. Для номенклатуры заказчика я сразу при загрузке получала Embeddings и сохраняла их в базе данных, но позиции из заказа всё равно приходилось обрабатывать отдельно.
Заказ на 50 позиций сопоставлялся минут 10, что было совершенно неприемлемо.
Ещё я заметила, что в топ-10 кандидатов попадали товары из других категорий. То есть в кандидаты для сверла спокойно мог попасть метчик. А правильное сверло — не попасть.
Ведь кандидаты оценивались только по семантическому сходству. Категории товаров Embeddings не интересовали.
Плюсом ко всему у меня были большие вопросы к YandexGPT, который в аналогичных ситуациях сопоставлял по-разному. А часто не сопоставлял даже самые очевидные варианты.
В итоге я решила, что мне нужна категоризация и GPT от OpenAI.
Переход на GPT
С ChatGPT всё было легко. VPN и иностранная карта позволили купить токены, и вместо YandexGPT заработал GPT.
Стало значительно лучше.
Косяков, конечно, тоже было достаточно, но где-то 30% позиций начали сопоставляться.
После этого я взялась за категоризацию.
Категоризация, которая сначала не взлетела
Первая идея была простой: в файле номенклатуры из 1С клиента категории уже были. Надо было их лишь загрузить в программу и научить её распределять позиции клиента по нужным категориям.
Казалось бы, чего тут сложного?
Но нет. Трудности были.
Во-первых, я пыталась программно выделить общие слова или корни слов из категории или из её названия. Но оказалось, что в категории часть товаров могла иметь одно обозначение, а другая часть — нет.
Например, в части сверл была прописана марка стали, а в других нет. Но в названии категории марка стали присутствовала.
Главной сложностью стала категория «Прочее», где лежала 1000 позиций, которые клиент решил не категоризировать.
И я понимала, что для правильности сопоставления мне самой придётся их по определённым ключевым словам разбить на группы.
В итоге, убив кучу времени на категоризацию таким образом, я решила от неё отказаться и найти что-то иное.
Фильтры вместо категорий
Уже к этому моменту я придумала фильтрацию.
Фильтры позволяли отсекать позиции, не имеющие критической характеристики. Например: марка стали, левый, длинный, конический хвостовик и другая инструментальная специфика.
Не думала, что жизнь меня заставит разбираться в инструментах, ан нет.
И наоборот — фильтры позволяли убирать позиции с критической характеристикой, если в заказе клиента её не было.
Тогда я подумала, что категории — это по сути те же фильтры.
Если у нас сверла, так давайте фильтровать по сверлам. Оставляем лишь то, что содержит «сверл». То же самое с метчиками, плашками и так далее.
Итого у меня вышло 42 варианта категорий.
Дальше я поняла, что эта схема реально рабочая.
Начало сопоставляться более 50% позиций.
Осталось довести фильтрацию и промпты до идеала и можно сдавать.
Легко сказать, но трудно сделать :-)
Что появилось в финальной версии
В итоге после нескольких месяцев работы появились:
- исключения;
- обогащение характеристиками;
- паттерны для фильтрации по артикулам;
- настройка фильтрации через пользовательский интерфейс;
- доработанные промпты;
- более удобный интерфейс;
- возможность отправить позиции на повторное сопоставление;
- переход на более современную модель GPT;
- возвращение Embeddings в общую схему сопоставления.
В итоге у меня получилась такая модель работы:
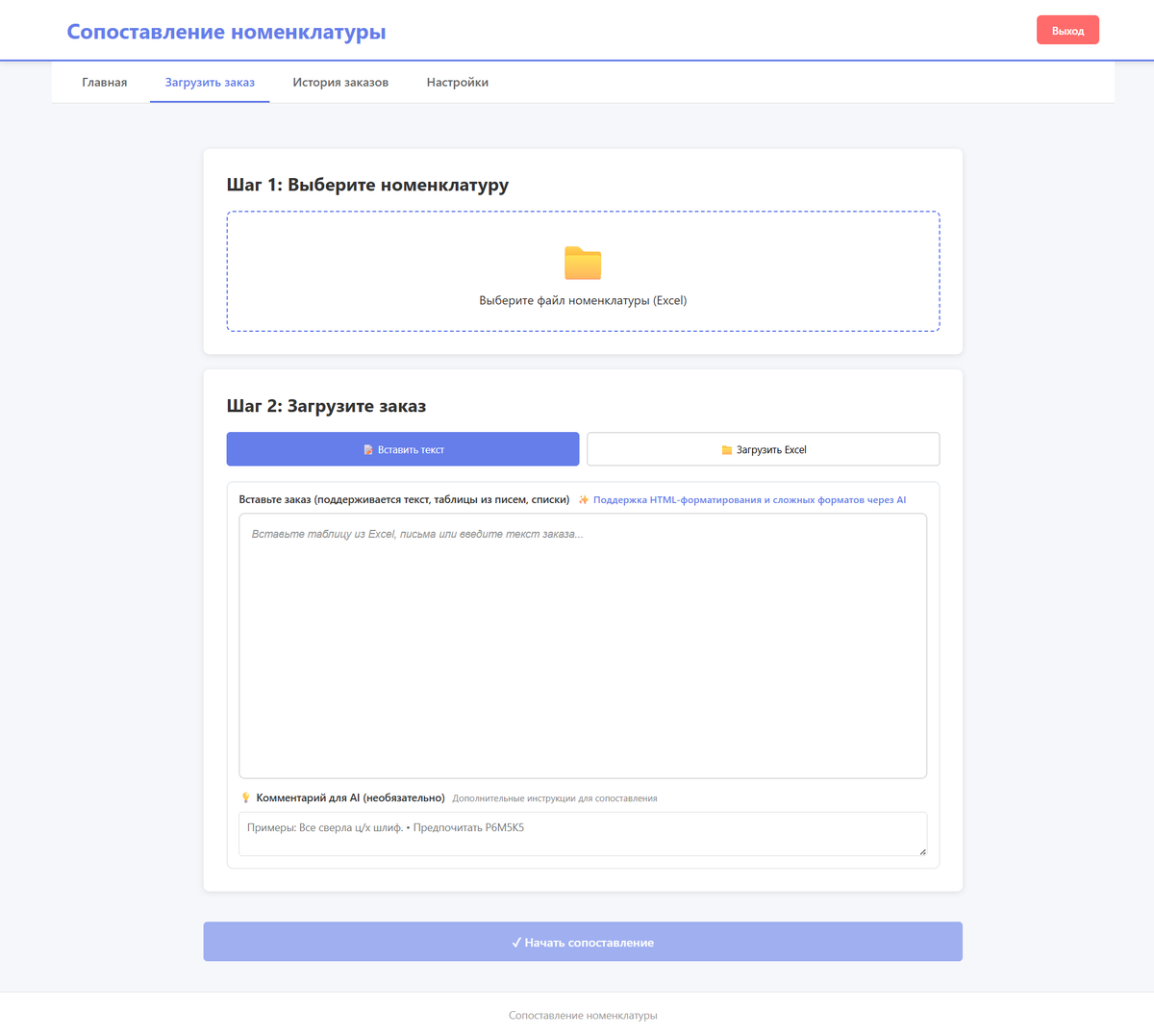
- Пользователь вставляет текст заказа.
- GPT распознаёт заказ и разбивает его на позиции.
- Фильтры оставляют самое нужное.
- Если осталось более 30 позиций, подключаются Embeddings.
- Топ-10 после Embeddings отправляется в GPT для выбора лучшего варианта.
- Если осталось меньше 30 позиций, все кандидаты сразу отправляются в GPT.
- Если у позиции высокий уровень соответствия по Embeddings, она уже была подтверждена вручную или точно повторяет позицию номенклатуры клиента, программа сопоставляет её автоматически.
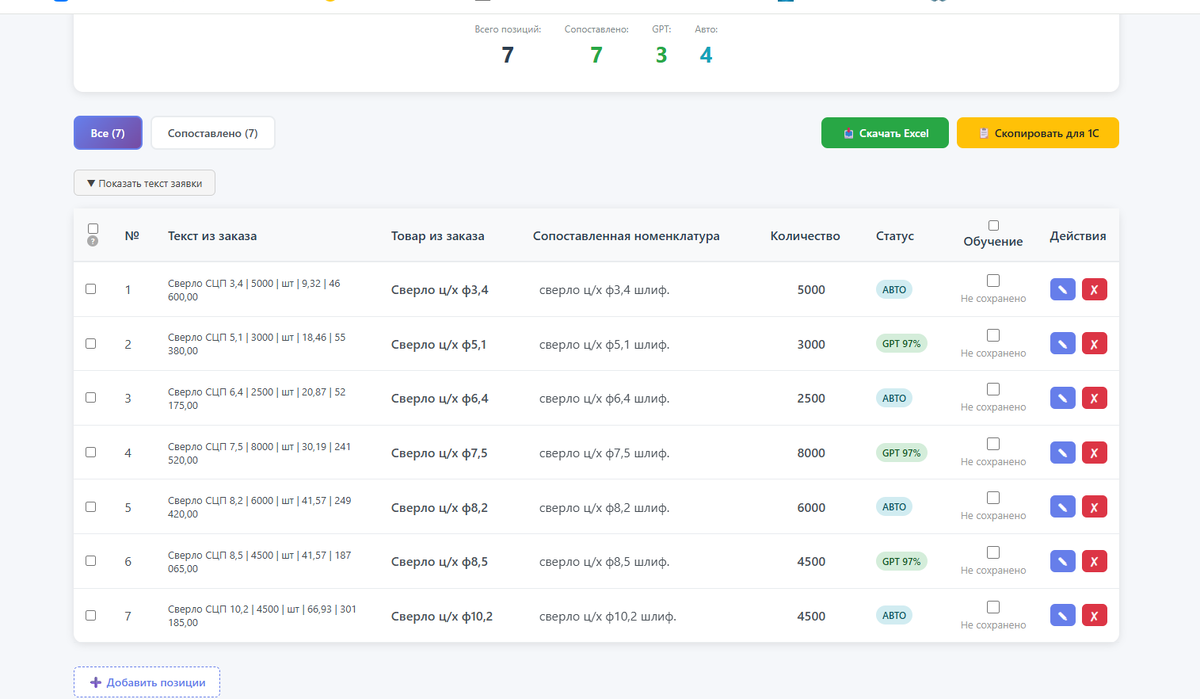
После сопоставления все позиции одной кнопкой копируются для вставки в заказ 1С.
Ведётся история сопоставления, а позиции, сопоставленные вручную, копятся для дальнейшего использования в системе.
Как это работает у клиента
Клиенту я разместила программу на немецком сервере, чтобы спокойно отправлять запросы в GPT.
Офис-менеджеры заходят по доменному имени, авторизуются и сопоставляют позиции.
Все настройки визуально может править администратор.
Программа всё так же крутится в Docker, что позволяет примерно за час развернуть её на любом сервере.
А фильтры, вынесенные в админку и хранящиеся в базе данных, позволяют легче настроить программу под другую компанию.
Результат внедрения
За программу мне в итоге заплатили.
Теперь она сопоставляет более 90% позиций, иногда и под 100%.
Раньше офис-менеджер тратил около 30 минут на обработку заказа из 100 позиций.
Теперь такой заказ обрабатывается примерно за 2 минуты.
То есть программа экономит около 28 минут на каждом заказе из 100 позиций.
А у офис-менеджеров освободилось много времени для других задач. Сокращать их не стали, решили использовать для другой деятельности.
А я рада, что всё получилось.
Кому может быть полезна такая программа
Изначально Matcher создавался как программа для автоматического сопоставления номенклатуры с базой 1С.
Но на практике такая задача встречается во многих компаниях:
- у поставщиков инструментов;
- у дистрибьюторов оборудования;
- у оптовых компаний;
- у производственных предприятий;
- у компаний, которые получают заявки в свободной форме;
- у организаций, где менеджеры вручную ищут товары в базе 1С.
Если ваши сотрудники ежедневно вручную сопоставляют товары клиентов с номенклатурой 1С, такую задачу можно автоматизировать.
Система распознаёт текст заявки, выполняет интеллектуальное сопоставление номенклатуры и подготавливает данные для вставки в 1С.
Особенно хорошо решение подходит компаниям, которые получают заявки в свободной форме: из писем, Excel-файлов, тендерных документов или просто списком в сообщении.
Если вам нужна похожая программа
Если кому-то тоже нужна похожая программа для сопоставления номенклатуры — обращайтесь.
Потребуется минимальная доработка под вашу деятельность и разворачивание программы на ваших серверах.
Главное — настроить фильтрацию и промпты под вашу номенклатуру. Это я смогу сделать совместно с вашим специалистом.
Актуальную стоимость стоимость программы вы можете узнать здесь.
Обращайтесь, буду рада сотрудничеству!
Об услуге Автоматизация с помощью AI