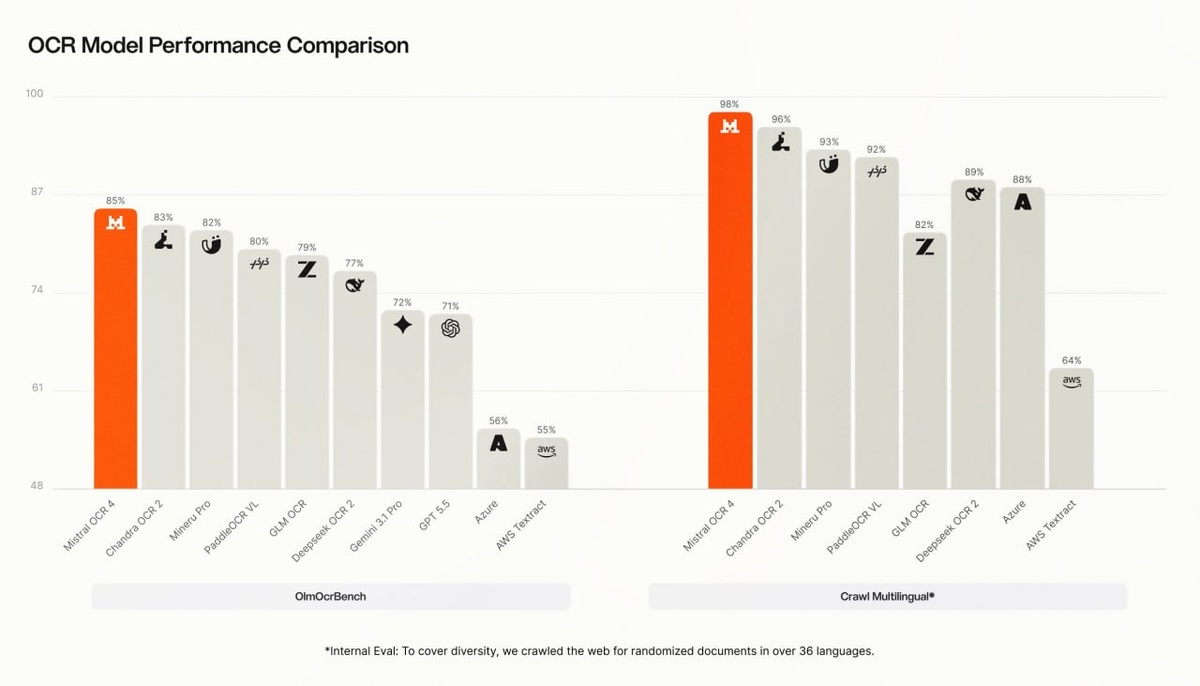
Mistral выпустил OCR 4, программу, которая читает документы и сразу понимает их устройство
Если коротко, OCR это технология, которая достает текст из картинок и сканов. Раньше она просто считывала буквы подряд и часто ломала таблицы и верстку. OCR 4 работает иначе. Он видит, где заголовок, где таблица, где формула, и помнит, в каком месте страницы что находится.
Зачем это нужно на простом примере. Загружаете PDF договора и спрашиваете что нибудь по тексту. Модель не только отвечает, но и подсвечивает место в оригинале, откуда взяла данные. Заодно сама помечает, где она уверена в распознавании, а где стоит перепроверить.
Поддерживает 170 языков, в том числе редкие вроде хинди, японского и грузинского, где другие сервисы часто ошибаются.
Можно поставить на свои сервера, документы не уходят наружу. Это важно для медицины, финансов и госструктур.
Цена 4 доллара за 1000 страниц. Если можно подождать, выходит 2 доллара. Принимает PDF, Word, PowerPoint и OpenDocument.