Давно хотел проверить одну штуку: может ли современный full-stack coding agent не просто «сверстать todo-лист», а пройти полный путь — изучить референс, извлечь требования, написать тесты, реализовать клиент и сервер, добавить local-first поведение, синхронизацию.
Все это за одну итерацию, только по требованиям.

Сразу дам ссылки на проект:
Демо: https://custom-pet-sthh55xpf-g28xyz-fkg4.onreza.app/
Код: https://github.com/G28XYZ/custom-pet/tree/pi-dev-clone-service
Референс: https://g28xyz.github.io/rvm-toolkit/examples/todo-list/
Указатель
pi - это терминальный ИИ-агент для программирования, ссылка - https://pi.dev/
pi tools - mcp-adapter, ponytail
local-first - это подход в разработке программного обеспечения, при котором основная копия данных приложения хранится на устройстве пользователя, а не на удалённом сервере.
deepseek-v4-pro - нейросеть которая использовалась в качетсве модели в pi
Что я дал агенту на вход
Дал ссылку на референс — простой todo-лист на rvm-toolkit. И инструкцию в AGENTS.md с жёсткими требованиями: работать через TDD, сначала изучить референс и извлечь требования, написать failing tests, потом реализовать production-код, довести тесты до зелёного состояния, проверить приложение через Playwright. Никаких «это оставим на потом» в списке обязательных пунктов.
Какие требования были зашиты в задачу
Архитектуру я тоже задал явно: не просто frontend-клон, а separate client-server приложение. Структура монорепозитория:
- apps/client — React + TypeScript + Vite
- apps/server — Node.js API + TypeScript с Express
- packages/shared — общие типы
База — PostgreSQL. Главная архитектурная идея — local-first: клиент сначала сохраняет данные локально в IndexedDB, основные действия работают без постоянной зависимости от сети, сервер используется для синхронизации и persistence.
Деплой — через Onreza, ресурс просто нашёлся на просторах интернета, есть бесплатные лимиты для деплоя. Деплой не был заложен для агента, это быстро сделалось вручную.
Что получилось в итоге
Агент справился со всеми обязательными пунктами за одну итерацию. Что реализовано:
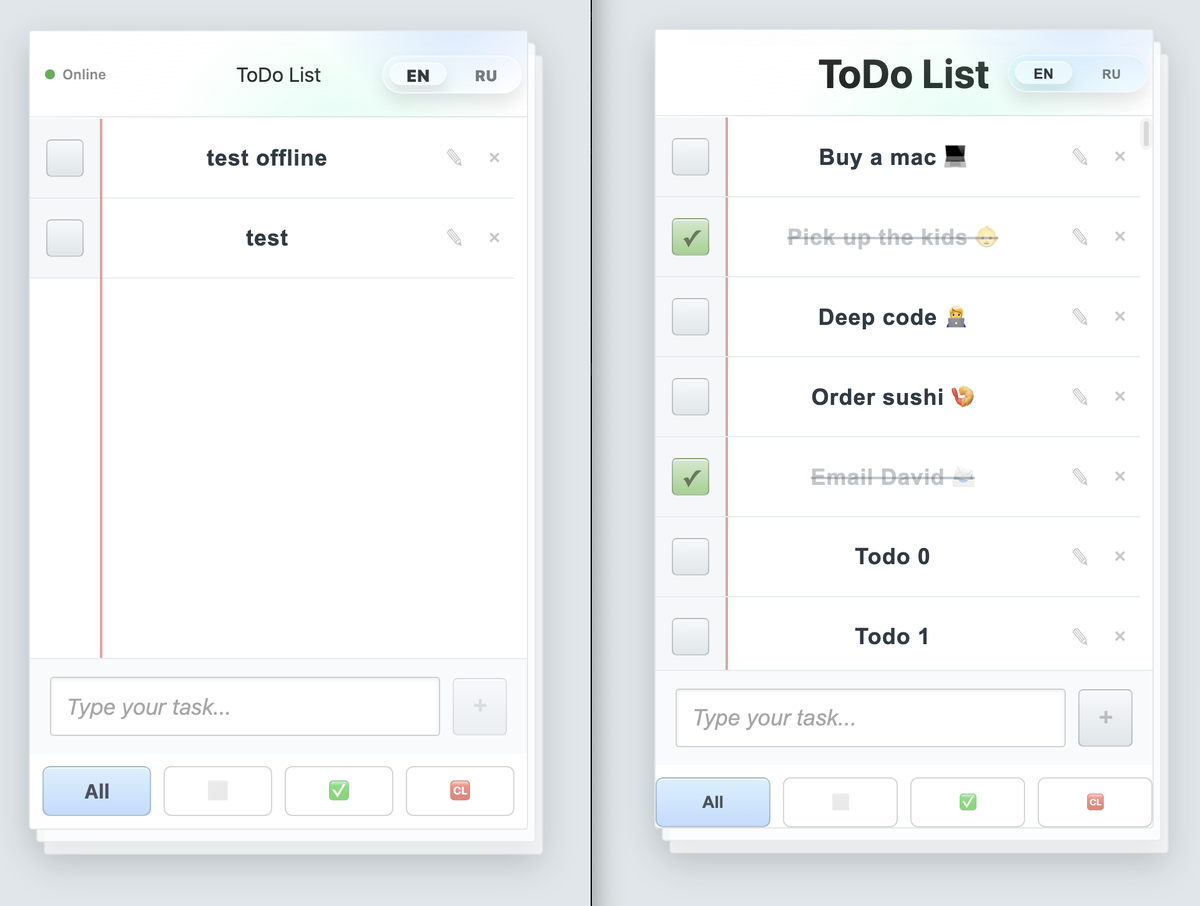
- Полный CRUD задач: добавление, редактирование, отметка выполненной, удаление
- Фильтры all / active / completed, clear completed
- Сохранение между перезагрузками страницы
- Переключение языка EN/RU
- Индикатор синхронизации: online, offline, syncing, error
- Доступные aria-labels и Playwright-селекторы для e2e-тестов
Backend: Express API с эндпоинтами:
- GET /api/todos
- POST /api/todos
- PATCH /api/todos/:id
- DELETE /api/todos/:id
- POST /api/todos/sync
- DELETE /api/todos/completed
- GET /api/health
Почему local-first оказался важной частью результата
Добавил просто изюминку, чтобы было интересней понаблюдать за агентом 😁
Это не просто «сохраняем в localStorage». Клиент использует библиотеку idb для работы с IndexedDB. При ошибке API локальные изменения не теряются. Удаления сохраняются отдельно в deletedIds и отправляются при следующей синхронизации.
Сервер нужен для persistence, но не блокирует работу приложения. В коде это выглядит так: клиент сначала пишет локально, потом пытается синхронизироваться, и если API недоступен — данные остаются на месте.
Это эксперимент и прототип, а не финальный production-продукт. Я бы не рекомендовал брать такой код и сразу деплоить в прод без ревью. Но как демонстрация возможностей — уже интересно.
Как агент соблюдал TDD
В этой итерации получилось так: агент не пошёл по пути «сначала код, потом тесты». Он действительно сначала написал server tests через Vitest + Supertest, проверил CRUD, фильтры, edge cases вроде пустой задачи. Потом e2e через Playwright: проверил persistence, local-first поведение, переключение языка. И только убедившись, что тесты падают — перешёл к реализации. TDD здесь был не формальностью, а реальным рабочим циклом.
Что удивило
Первое — агент сам разобрался в структуре референса. Открыл его через MCP Playwright, изучил UI, тексты, кнопки, фильтры и состояния. Не потребовалось расписывать требования вручную.
Второе — local-first синхронизация получилась не примитивной. Отдельная очередь deletedIds, отложенная отправка при восстановлении сети — это то, что обычно требует ручного проектирования. Агент сделал это сам, следуя общему architectural constraint из задачи.
Что пока остаётся спорным
Ручная проверка всё равно нужна. Агент может пропустить edge case, который не покрыт тестами. Может выбрать неоптимальную структуру для конкретного деплой-окружения.
Агент полезен, но инженерный контроль всё равно нужен: требования, проверка тестов, архитектурные решения. Полностью отдать проект агенту без присмотра я бы пока не рискнул. Но как инструмент для быстрого прототипирования и проверки гипотез — отлично.
Вывод
Где такие агенты уже полезны: быстрое прототипирование, клонирование типовых сервисов, генерация boilerplate с тестами, проверка гипотез.
Где всё ещё нужен инженерный контроль: финальная архитектура, безопасность, деплой-специфичные настройки, нестандартные интеграции и всё, что требует контекста, которого нет в референсе.
Я бы не называл это финальным продуктом, но как прототип и эксперимент получилось интересно. В планах — попробовать на более сложных сценариях.
Ссылки 🔗 Демо · Код · Референс