
Синхронизация: spinlock и sleeping-mutex
В статьях про прерывания и планировщик постоянно всплывала одна фраза: "возьми не ту блокировку, и система зависнет". Теперь речь о самих блокировках. Как только к одним и тем же данным обращается больше одной нити исполнения, а это происходит уже с прерываниями на одном ядре, тем более на двух - нужна защита. У меня (на самом деле не только у меня, это общеизвестные механизмы) два сорта блокировок, и разница между ними на удивление весомая.
Проблема - одновременный доступ
Хватит крошечного примера. Два потока увеличивают один счётчик:
count++; // выглядит атомарным, но это не так
выполняется так
tmp = count; tmp = tmp + 1; count = tmp;
Если два ядра выполнят это вперемешку, оба прочитают старое значение, оба прибавят единицу, оба запишут одно и то же новое, и один инкремент потеряется. Такие "состояния гонки" (race condition) коварны, потому что всплывают лишь иногда, в зависимости от тайминга. Место, где они случаются, "критический участок", должно быть монопольным - внутри всегда только один поток.
Два сорта блокировок
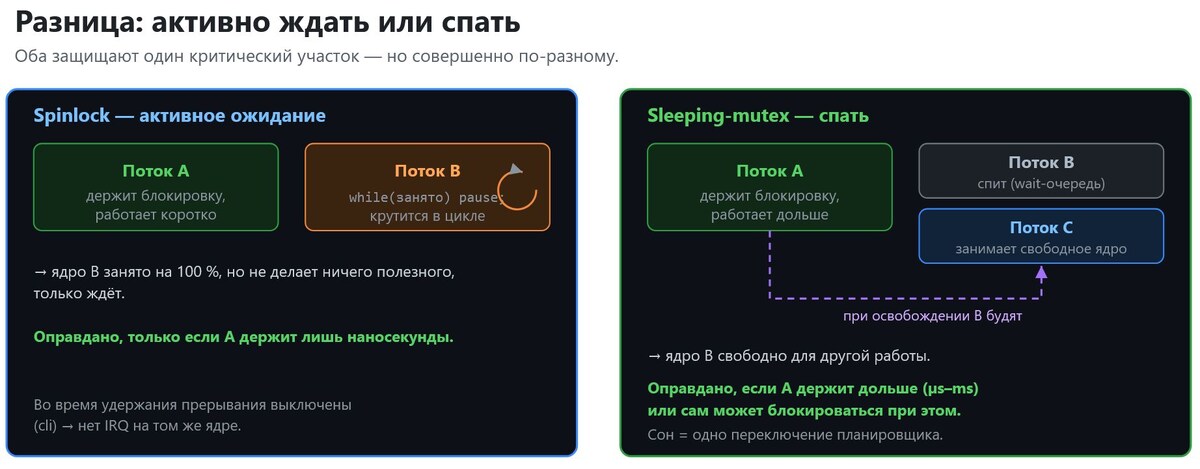
Разница в том, что делает ждущий поток.
Spinlock заставляет его ждать активно. Кто не получил блокировку, крутится в цикле и спрашивает снова и снова, пока она не освободится:
void spinlock_acquire(Spinlock* lock) {
// ... прерывания выключены (cli) ...
while (atomic_exchange(&lock->lock, 1) != 0) // занято? спрашиваем дальше
asm volatile("pause"); // ядро крутится активно
}
Sleeping-mutex заставляет его спать. Кто не получил блокировку, отдаёт CPU и ложится в очередь ожидания wait, пока его не разбудят:
bool mutex_get(Mutex* mutex, bool wait) {
if (atomic_exchange(&mutex->lock, 1) == 0) // свободно -> сразу (fast path)
return true;
// занято -> в wait-очередь, СПАТЬ (отдаёт CPU другому потоку):
wait_queue_block_with_timeout(&mutex->waiters, &mutex->guard, TIMEOUT);
}
Spinlock жжёт процессорное время в ожидании, зато экономит дорогой крюк через планировщик. Mutex освобождает CPU, но платит за это переключением контекста. Что лучше, целиком зависит от того, как долго держится (должна держаться) блокировка.
Когда что?
Правило большого пальца - spinlock уместен, когда блокировка держится совсем коротко, меньше примерно сотни инструкций, а в двух ситуациях он даже обязателен. Во-первых, в контексте прерывания, ведь обработчик прерывания не может уложить себя спать, он не запланированная задача, которую планировщик потом снова разбудит. Во-вторых, когда ты уже держишь другой spinlock.
Sleeping-mutex уместен, когда блокировка держится дольше, микро- до миллисекунд, или когда держатель при этом сам может блокироваться, например потому что ждёт памяти или диска, и ты не в контексте прерывания.
Отсюда следуют два железных запрета, и за каждый я заплатил зависшей загрузкой:
- Никогда мьютекс в обработчике прерывания. Обработчик не может спать, попытка останавливает CPU навсегда.
- Никогда мьютекс, пока держишь spinlock. Spinlock выключил прерывания, сон уже не вернётся.
Как мы их строим на практике
Spinlock в основе, это единственное атомарное "обменяй и проверь" в цикле, ты видел это выше. В нём остаются три тонкости. Пока spinlock держится, прерывания выключены, иначе IRQ на том же ядре мог бы запросить ту же блокировку и сам себя запереть. Он Spinlock рекурсивный, тот же поток может взять его второй раз. И он выровнен по кэш-линии (aligned(64)), чтобы две независимые блокировки не лежали в одной кэш-линии и не тормозили друг друга.
У mutex есть быстрый и медленный путь. Если он свободен, атомарное "сравнение-и-обмен" захватывает его сразу, без всякого крюка через планировщик. Если занят, включается медленный путь в wait-очередь, спать, разбудят позже, при нужде через межпроцессорное прерывание спящему ядру. Так что под мьютексом сидит wait-очередь как строительный блок, а в ней снова сидит маленький spinlock, который лишь совсем коротко защищает список ждущих потоков.
Где мы их используем
На практике распределение довольно ясное. Spinlock'и сидят везде, где речь лишь о наносекундах или где в игре прерывание: очередь готовых каждого CPU в планировщике, внутренняя блокировка связного списка, буфер клавиатуры, сами обработчики прерываний и маленький "guard" внутри каждого мьютекса.
Мьютексы защищают всё, что дольше и может спать: куча (при вызове kmalloc), аллокатор физической памяти, список процессов, глобальная блокировка накопителя при чтении с диска. Тут как раз хорошо, что ждущий освобождает CPU, потому что ожидание может затянуться.
Третья опасность - deadlock
Даже с правильными блокировками подстерегает ещё ловушка. Поток A держит lock 1 и хочет lock 2, поток B держит lock 2 и хочет lock 1, и вот оба ждут друг друга вечно. Это deadlock - ни падения, ни сообщения, система просто встаёт.
Решение, это фиксированный порядок. Кому нужно несколько блокировок, берёт их всегда в одном и том же, заранее заданном порядке. Тогда круг не сможет замкнуться, потому что никто никогда не держит "более высокую" блокировку и не хочет "более низкую". У меня эта иерархия записана, для памяти, например - сначала мьютекс адресного пространства, затем мьютекс физической памяти, затем мьютекс кучи, последней, per-CPU temp-блокировка. А детектор deadlock'ов бьёт тревогу, если кто-то нарушает порядок, лучше громкое сообщение, чем тихий стоп.
И снова честная часть
Почти каждый из моих самых упрямых SMP-багов в основе был ошибкой синхронизации: мьютекс, случайно взятый под удержанием spinlock, printf посреди обработчика прерывания, захотевший блокировку, которая как раз удерживается, блокировка в неверном порядке. Правила этой части звучат педантично, и именно таковы они и есть, каждое, это урок от конкретной загрузки, которая не прошла. На одном ядре система прощает много мелких грехов, потому что многое и так идёт последовательно. На двух ядрах она карает любое нарушение правил немедленно, и потому эта часть ядра была самой поучительной из всех.
◀ Предыдущая статья Содержание Следующая статья ▶
*Система не стоит на месте, поэтому в дальнейшем тексты могут не совпадать с реальным положением.