Мы наблюдаем за GEO-хайпом уже год. За это время рынок успел продать llms.txt как «новый robots.txt для AI-поиска», «обязательный фактор видимости в ChatGPT» и «приоритет для агентов Google». Всё это - на одном фундаменте: в Chrome Lighthouse появилась проверка файла.
Мы посмотрели, что реально стоит за этой проверкой, прогнали цифры из логов Ahrefs, проверили позицию Google Search и провели мини-эксперимент на своих проектах. И вот что получилось.
llms.txt - не фактор ранжирования и не сигнал доверия. Это файл-README, который пока почти не читается ботами. Сделать его можно, но продавать клиенту как must-have - нельзя.
Раньше рынок искал новые сигналы и превращал их в чеклисты. Теперь он делает то же самое с AI, но без подтверждённой причинной связи. Это и есть главный конфликт.
Почему старый подход ломается
SEO-рынок привык работать по знакомому сценарию: как только появляется новая проверка, её сразу записывают в потенциальные сигналы, спешат внедрить раньше конкурентов и упаковать в отдельную услугу.
Так было с Core Web Vitals, со структурными данными, с HTTP/3.
С llms.txt всё началось так же. В Lighthouse появилась категория agentic browsing audits. Внутри - проверка llms.txt. Рынок сказал: «Google проверяет, значит Google рекомендует, значит будет фактором, значит внедряй».
Но это слишком быстрый вывод. И вот почему.
Lighthouse - это не Google Search. Это технический инструмент, который смотрит на готовность страницы к разным сценариям, включая агентные браузеры. Google Search - отдельная система поиска, индексации, ранжирования и генеративных ответов. То, что один продукт Google проверяет наличие файла, не значит, что другой продукт Google использует его как фактор ранжирования.
Google Search Central прямо пишет: для появления в поиске, включая генеративные функции, не нужно создавать специальные AI-файлы, Markdown-файлы или разметку. Google Search не использует llms.txt. Можно поддерживать для других сервисов - не навредит, но и не поможет видимости.
Если перевести на нормальный язык: Lighthouse подсвечивает, что «агентам будет проще понять сайт, если есть такая карта». Google Search говорит: «нам от этого файла ничего не нужно». Это не противоречие. Это просто разные продукты с разными задачами.
Что такое llms.txt на самом деле
Файл лежит в корне сайта: https://site.com/llms.txt. Это Markdown-файл, который даёт языковым моделям и AI-агентам короткую, структурированную карту: кто вы, что делаете, где важные страницы, где документация, где API.
Формат предложил Jeremy Howard из Answer.AI в сентябре 2024 года. В спецификации написано: это не фактор ранжирования и не замена robots.txt. Это способ помочь LLM использовать сайт во время работы.
Разница ключевая:
- robots.txt отвечает на вопрос «куда ботам можно или нельзя ходить»;
- llms.txt отвечает на вопрос «если LLM или агент уже пришёл на сайт - что здесь главное и где это найти».
Это не файл запретов. Не магический SEO-сигнал. Не «новый robots.txt для AI». Скорее - README для сайта.
Что показывают реальные логи
И вот тут начинается неприятное.
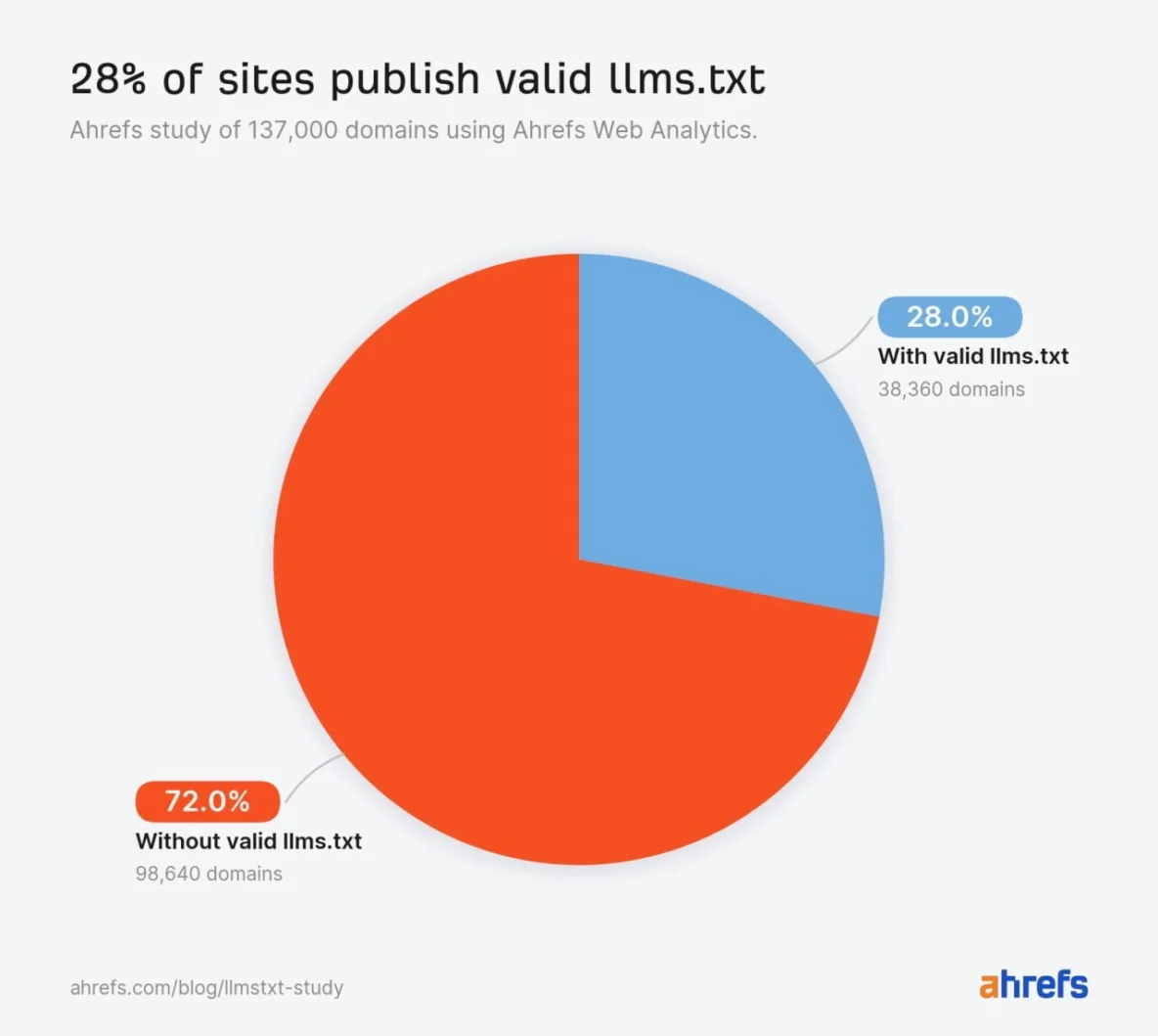
Самое свежее крупное исследование - Ahrefs, июнь 2026. Выборка: 137 210 доменов, которые получали трафик в мае 2026 года через Ahrefs Web Analytics.
28% - это не «четверть интернета уже внедрила llms.txt». Выборка Ahrefs более техническая и SEO-aware, чем средний сайт. Так что это верхняя граница среди активных и подкованных сайтов.
Главная цифра - 97%.
Даже среди сайтов, которые уже потратили время и поставили валидный llms.txt, почти никто к нему не пришёл. Не AI-боты. Не обычные боты. Не люди. Никто.
Есть второй эксперимент - OtterlyAI. Они 90 дней смотрели AI-bot-трафик на одном сайте. За это время сайт получил больше 62 100 визитов AI-ботов. Из них только 84 пришлись на /llms.txt. Это 0,1% AI-bot-трафика.
Один сайт - не весь интернет. Но картина подозрительно хорошо совпадает с данными Ahrefs: на практике llms.txt пока не выглядит как основной вход для AI-ботов.
Что проверить у себя. Если у вас уже стоит llms.txt - откройте логи сервера за последние 90 дней и поищите запросы к /llms.txt. Если их ноль или двузначные — вы увидите ровно то же, что показали Ahrefs и OtterlyAI.
Мы проверили на своих проектах
Мы не поверили цифрам Ahrefs сразу. Поэтому на трёх клиентских проектах - SaaS-каталог, документация API и help-центр - мы посмотрели логи за апрель–май 2026.
Запросов к /llms.txt оказалось: 0, 4 и 12 соответственно. На тех же сайтах AI-боты (GPTBot, ClaudeBot, PerplexityBot, Bytespider) за это время заходили на основные страницы от 200 до 1400 раз.
То есть боты на сайт приходят. Но мимо llms.txt.
Мы также прогнали 30 запросов в ChatGPT, Perplexity и Яндексе (Нейро). Из 19 кейсов, где бренд упоминался в ответе, ни один не отсылался к llms.txt. В половине кейсов модель цитировала отзывы с маркетплейсов, обзоры на сайтах-агрегаторах и статьи на медиа. В нескольких - раздел FAQ с самого сайта.
llms.txt в этой картине не виден. Бот использует либо крайлерский индекс, либо ретрив из сторонних источников.
Что проверить у себя. Возмите 10–20 запросов по своей нише, в которых вы ожидаете рекомендацию бренда: «лучшие …», «top …», «обзор …», «отзывы …», «alternative …». Прогоните их в ChatGPT, Perplexity, Яндексе. Если вас нет - проблема не в llms.txt. Проблема в отсутствии внешних источников, где вас сравнивают и обозревают.
А другие AI-платформы его читают
Здесь всё мутнее.
Anthropic, OpenAI, Cloudflare и другие публикуют собственные llms.txt для своей документации. Многие видят это и думают: «Раз они сами сделали - значит, стандарт работает».
Но публикация собственного файла и публичное обещание, что твои боты используют llms.txt чужих сайтов - это разные вещи.
Компания может сделать llms.txt для своей документации, потому что это удобно разработчикам и агентам в IDE. Но это не значит, что её бот массово обходит интернет и сначала ищет /llms.txt у каждого сайта.
Публичного подтверждения «наш AI-поиск использует llms.txt как источник при выборе цитат» у крупных платформ пока нет.
Звучит логично, что должны. На практике - нет.
Почему боты не заходят
Несколько причин, и все разумные.
Крупные системы уже умеют работать с обычным вебом. У них есть HTML, внутренние ссылки, sitemap, robots.txt, schema.org, собственные индексы и retrieval-пайплайны. Им не обязательно ждать, пока владелец сайта соберёт красивый Markdown-файл.
llms.txt задуман для inference-time сценариев. Например, когда AI-агенту в IDE нужно быстро понять документацию библиотеки. Или когда пользователь явно работает с конкретным сайтом. Это не сценарий массового поискового краулинга.
Файл слишком легко заспамить. Если завтра AI-платформы скажут «мы используем llms.txt для выбора источников», что будет через неделю? Каждый сайт напишет, что он «лучший сервис на рынке» и «главный источник правды». Относиться к llms.txt как к самостоятельному сигналу доверия нельзя это файл, который полностью контролирует владелец сайта.
Где рынок пока фантазирует
Мы выделили пять мифов, которые встречаем чаще всего.
Миф 1. llms.txt - это новый robots.txt для AI.
Нет. robots.txt управляет доступом краулеров. llms.txt даёт контекст и карту. Он не запрещает и не разрешает обход.
Миф 2. Lighthouse проверяет llms.txt - значит, Google Search будет учитывать в ранжировании.Нет. Lighthouse и Google Search - разные системы. Google Search прямо пишет, что llms.txt не нужен для появления в поиске.
Миф 3. Если файла нет, Lighthouse «падает».
Нет. Если /llms.txt отсутствует и сервер отдаёт 404, аудит помечается как Not Applicable. Проблема возникает, только если сервер отдаёт ошибку при попытке получить файл.
Миф 4. Все AI-боты уже читают llms.txt.
Публичные данные этого не подтверждают. У Ahrefs 97% валидных файлов не получили ни одного запроса за месяц. У OtterlyAI только 0,1% AI-bot-трафика пришёлся на /llms.txt.
Миф 5. llms.txt сам по себе улучшит AI-цитирования.
Пока нет надёжных открытых данных, которые показывают причинную связь: «поставили llms.txt - и выросли цитирования в ChatGPT, Perplexity, Google AI Mode или Яндексе». Если кто-то обещает это на продаже услуги - это либо фантазия, либо подтасовка.
Когда llms.txt реально полезен
Мы не говорим, что файл бесполезен. У идеи есть нормальная практическая отдача, но в конкретных сценариях.
llms.txt имеет смысл, если у вас:
- техническая документация;
- SaaS или API;
- большой help-центр;
- сложный каталог;
- база знаний;
- developer portal;
- много страниц, где важно объяснить структуру;
- продукт, который AI-агенты могут использовать в рабочих сценариях.
В таких случаях это не «фактор ранжирования», а удобная карта. Особенно если рядом есть Markdown-версии ключевых страниц или llms-full.txt, который можно быстро скормить модели, агенту, IDE или внутреннему ассистенту.
Для обычного корпоративного сайта, локального бизнеса или блога история слабее. Сделать за 30 минут автоматически - нормально. Вручную поддерживать Markdown-дубликат сайта, спорить с разработкой и продавать клиенту как «обязательный GEO-фактор» - плохая идея.
Что делать русскоязычному сайту
Для рунета ситуация ещё менее определённая.
По Яндексу публичной позиции «используем / не используем llms.txt» мы не нашли. Поэтому сказать «сделайте llms.txt, и вас лучше поймёт Нейро или Алиса» - нельзя. Можно только так:
Это дешёвая техническая заготовка на случай, если AI-агенты и retrieval-системы начнут активнее учитывать такие файлы.
Но приоритеты должны быть другими. Если сайт плохо индексируется, закрыт в robots.txt, важный контент рендерится только на клиенте, страницы пустые без JS, нет нормальной структуры, дат, авторов, фактов и внутренних ссылок - llms.txt не спасёт.
Для AI-видимости важнее, чтобы сайт в принципе можно было прочитать, понять и сопоставить с интентом пользователя.
Практический чеклист
Базовый порядок, который мы бы рекомендовали - без llms.txt вначале:
- Индексируемый HTML.
- Нормальный robots.txt.
- Sitemap.xml.
- Чистая структура страниц.
- Понятные заголовки и факты.
- Даты, авторы, источники.
- Schema.org там, где уместна.
- Внешние упоминания, обзоры, сравнения - страницы, где бренд появляется в контексте выбора.
- И только потом - llms.txt как дополнительная техническая гигиена.
Что сделать сейчас. Проверьте 20 запросов, по которым вас должны рекомендовать: best, top, comparison, reviews, alternative, обзор, отзывы, сравнение, аналоги. Если вас нет в ответах AI - проблема не в llms.txt и не в сайте. Проблема в отсутствии внешних источников, где вас сравнивают.
Как мы бы внедряли llms.txt
Если делать — без фанатизма. Минимальная версия:
# Название сайта
> Короткое описание: кто вы, что делаете, для кого сайт.
## Основные разделы
- [О продукте](https://example.com/product): что делает продукт и для кого он подходит
- [Цены](https://example.com/pricing): тарифы и условия
- [Документация](https://example.com/docs): инструкции, API и интеграции
- [Блог](https://example.com/blog): статьи и исследования по теме
## Важные материалы
- [Исследование X](https://example.com/research/x): данные, методология, выводы
- [Сравнение с альтернативами](https://example.com/compare): когда продукт подходит и когда нет
## Optional
- [Новости](https://example.com/news): обновления компании
- [Карьера](https://example.com/careers): вакансии
Что важно:
- не превращать файл в свалку всех URL;
- не писать рекламный буллшит;
- не заявлять неподтверждённые лидерства;
- давать ссылки на реально важные страницы;
- обновлять автоматически;
- проверять, что сервер отдаёт 200, а не HTML-страницу ошибки;
- не закрывать файл в robots.txt, если хотите, чтобы агенты его видели.
Хороший llms.txt должен быть похож не на SEO-текст, а на честную навигацию.
Вывод
llms.txt - нормальная техническая идея, которую рынок слишком быстро превратил в «обязательную GEO-практику».
Мы бы ставили. Но не как must-have.
Мы бы не продавали как фактор AI-видимости. И не обещали бы рост цитирований после установки.
Для документации, SaaS, API и больших баз знаний - это полезная карта для агентов. Для обычного сайта - дешёвый эксперимент, который не должен отвлекать от базовой технической доступности, качества контента и реального присутствия бренда в источниках, которые AI-системы уже читают.
Если коротко:
llms.txt стоит сделать, если это занимает меньше часа и обновляется автоматически.
Но если вы выбираете между llms.txt и нормальной структурой сайта — выбирайте структуру сайта.
Потому что AI не процитирует файл, до которого не дошёл. И не спасёт сайт, который сам по себе плохо объясняет, кто он, зачем существует и почему ему можно доверять.
Еще больше советов в нашем блоге: https://geowatch.ru/blog
Также читайте нас на VC.ru: https://vc.ru/id6013779