
Все вокруг говорят «AI-агент», но большинство имеют в виду совсем другое. Это не наезд, просто так сложилось: слово стало маркетинговым и прилипло к любому чат-боту с кнопками. В этой статье разберём, как на самом деле устроена иерархия AI-систем: от базовой языковой модели до агента, который принимает решения сам.
Что вы узнаете:
- Что такое LLM и как она генерирует текст по одному токену
- Зачем нужны векторы и при чём тут «король минус мужчина»
- Что такое контекстное окно нейросети и почему все его расширяют
- Чем AI-workflow отличается от агента, и когда это реально важно
- И главное: почему 90% того, что называют агентами, агентами не является
Что такое LLM: предсказание следующего слова, и ничего больше
LLM (Large Language Model, большая языковая модель) - это не база данных с готовыми ответами. Это статистическая машина, которая на каждом шаге предсказывает один следующий токен.
Токен - это не буква и не всегда целое слово. Грубо говоря, это кусок текста: «авто», «матиза», «ция» могут быть тремя отдельными токенами (хотя для большинства пользователей это не важно - важно понимать, что текст режется). ChatGPT, Claude, Gemini - все они работают по одной схеме: берут весь предыдущий контекст, смотрят, что вероятнее всего идёт дальше, и добавляют один токен. Потом ещё один. И так по кругу.
Звучит примитивно, правда? Казалось бы, просто угадывалка слов - на деле из этого вырастает способность писать код, объяснять концепции и вести сложные диалоги. Секрет в том, что «угадывание» происходит не на уровне символов, а на уровне смысла.
Вот где в игру входят векторы.
Токены, векторы и семантика: почему «король минус мужчина равно королева»
Каждый токен кодируется вектором - набором чисел, который описывает его смысл. Близкие по значению слова оказываются близко друг к другу в этом математическом пространстве.
Классический пример: вектор слова «король» минус вектор «мужчина» плюс вектор «женщина» - и получаем вектор, максимально близкий к «королева». Модель не заучила этот факт, она его вывела из структуры языка.
Именно поэтому LLM понимает синонимы, подтекст и контекст. Она не ищет совпадения строк, как grep в терминале. Она работает со смыслом.
Кстати, если тема интересна - в Telegram-канале пишу о подобном регулярно: инструменты, лайфхаки, конкретные сценарии использования нейросетей в жизни и бизнесе. Там проще задать вопрос и не ждать следующей статьи.
Что такое контекстное окно нейросети: оперативная память модели
Контекстное окно - это то, сколько информации модель держит «в голове» за один раз. Весь разговор, системный промпт, загруженные документы - всё это занимает токены внутри окна.
Если диалог выходит за пределы окна, модель буквально забывает начало разговора. Ну, то есть не «забывает» в человеческом смысле - её просто физически не подают в контекст: это архитектурное ограничение, а не баг.
Поэтому все крупные компании гонятся за расширением контекста: у Claude сейчас 200K токенов, у некоторых моделей уже миллион. Но есть подводный камень: 10 итераций агента легко съедают 50-100 тысяч токенов суммарно. Это влияет на стоимость запуска, о чём в демо на YouTube обычно умалчивают.
Как модель обучается: Reinforcement Learning за 3 предложения
Модель сначала обучается на огромных объёмах текста - это предобучение. Потом её дообучают через Reinforcement Learning (обучение с подкреплением): люди-оценщики ставят оценки ответам, модель учится получать более высокие оценки.
Грубо говоря: хороший ответ - получаешь «плюс», плохой - «минус». Миллионы таких итераций и формируют то, что мы воспринимаем как «умность» модели.
Это объясняет, почему модели хороши в том, что люди считали хорошим при обучении - и почему они могут уверенно галлюцинировать там, где оценщики не заметили ошибки.
AI Workflow: LLM с инструментами, но по жёсткому маршруту
Workflow (или AI Pipeline) - это когда LLM получает доступ к инструментам: Google Календарь, таблицы, браузер, CRM. Но цепочка шагов задана заранее.
Пример: «Когда у меня встреча с Ариной?» Модель идёт в Google Календарь, находит событие, возвращает ответ. Шаги зафиксированы: запрос - поиск в календаре - ответ. Если что-то пошло не так - workflow встаёт.
На одном проекте мы строили похожую цепочку в n8n: входящее сообщение - классификация - ответ из базы или передача оператору. Работает стабильно именно потому, что каждый шаг прописан. Вернее даже не «стабильно», а «предсказуемо» - это важнее.
По данным Anthropic, большинство рабочих задач не требует настоящего агента. Workflow дешевле, надёжнее и проще в отладке. Правило практика: начинать всегда с workflow, агент - только если задачу нельзя разложить на шаги заранее.
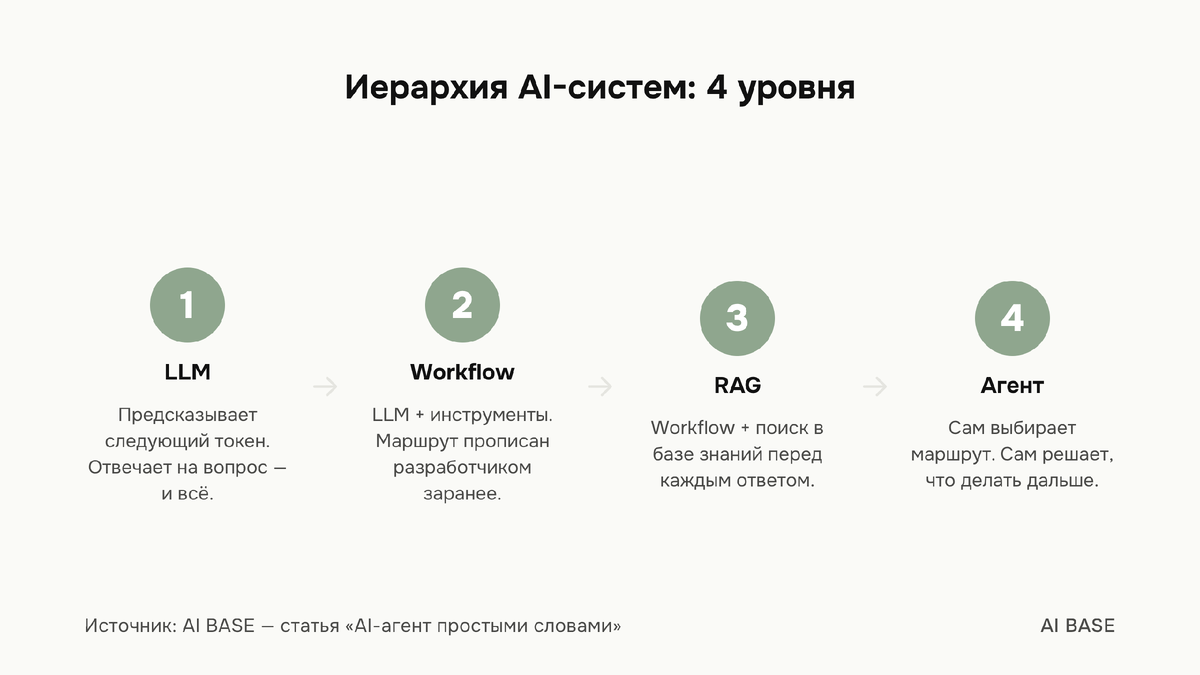
RAG: как модель работает с вашей базой знаний
RAG (Retrieval Augmented Generation) - это паттерн, при котором модель не пытается вспомнить ответ из обучения, а идёт за ним в базу знаний.
Схема простая: пришёл запрос - система ищет релевантный документ в базе - вставляет его в контекст - модель генерирует ответ на основе этого документа.
Пример: пользователь спрашивает про стиральную машину Bosch 2480. Модель без RAG начнёт фантазировать. Модель с RAG лезет в базу поддержки, находит нужную статью и отвечает точно по ней.
RAG - это не «обученная на ваших данных модель». Это поиск плюс генерация. Разница принципиальная: данные не «зашиты» в веса, они подтягиваются при каждом запросе. Значит, базу можно обновить в любой момент без переобучения модели.
AI-агент: когда система сама выбирает маршрут
Вот мы и добрались до главного. AI-агент - это система, где LLM сама решает, какие шаги предпринять для достижения цели. Цикл: выбрать следующее действие - выполнить - посмотреть на результат - решить, что дальше.
Workflow идёт по заданному маршруту. Агент выбирает маршрут сам.
Пример: «Найди топ-10 конкурентов в нише кроссовок». Workflow с такой задачей не справится без жёсткой прописанной логики. Агент оценил задачу, решил не лопатить весь интернет вручную, нашёл готовую подборку - и вернул результат. Он на лету выбрал инструмент и адаптировался.
Это и есть принципиальная разница. Не «умный чат-бот» и не «автоматизация с кнопками». Агент самостоятельно принимает решения о том, как выполнить задачу.
Где это ломается: 4 ошибки, которые встречаются чаще всего
Называют агентом любой чат-бот с кнопками. Если у бота есть кнопка «да/нет» и он по ней идёт в базу - это не агент. Это workflow без кода.
Запускают агента без лимитов на API. Главный риск: агент с доступом к платному API и без ограничений может потратить неожиданные деньги за один запуск. «Никогда не оставляйте модель открытой, предоставленной самой себе» - это не преувеличение. При подключении к любому API лимиты на количество действий - обязательно.
Путают RAG с дообучением. «Мы обучили модель на наших данных» - в большинстве случаев это RAG, а не fine-tuning. Разные вещи с разными ограничениями.
Используют агента там, где нужен workflow. Если задача повторяется и шаги известны - workflow предсказуемее и дешевле. Агент нужен только для нештатных ситуаций, где заранее не знаешь, что произойдёт.
Когда стоит разобраться в этом глубже
Понимание разницы между LLM, workflow и агентом - это не теория ради теории. Это то, что позволяет оценить, когда вам предлагают реальный инструмент, а когда продают маркетинговую обёртку с ChatGPT внутри.
Следующий шаг - попробовать собрать workflow руками. n8n позволяет сделать это бесплатно и без кода. Дальше будет видно, нужен ли вам агент или хватит цепочки шагов. Пара бесплатных опций - в самом конце статьи.
Если хочется не просто читать про AI, а реально его применять, у меня есть несколько мест, где это можно делать вместе.
Начать стоит с Telegram-канала. Это наш основной ресурс, где разбираем новые инструменты, кейсы автоматизации и приёмы, которые можно применить уже завтра.
Если зайдёт, залетайте в AI BASE. Это закрытое сообщество, где я делюсь личными наработками по автоматизации, вайб-кодингу и нейросетям.
А если хочется прямо сейчас сесть и попробовать руками, есть два бесплатных курса с нуля: по n8n для автоматизации без кода и по Claude Code для разработки в связке с AI.
FAQ
Чем AI-агент отличается от чат-бота?
Чат-бот отвечает на сообщение - один вход, один выход. Агент получает задачу и сам решает, какие шаги предпринять: найти информацию, вызвать инструмент, оценить результат, повторить. Это цикл, а не одиночный ответ.
Как ограничить AI-агента при работе с API?
Ставить лимиты на количество вызовов (например, не более 20 шагов за сессию), ограничивать бюджет через настройки API-ключа, логировать все действия и добавлять проверку человека для необратимых операций. Без этого агент с доступом к платному сервису - это открытый кран.
RAG база знаний как работает технически?
Документы из базы превращаются в векторы и хранятся в векторной базе данных. При запросе система ищет ближайшие по смыслу фрагменты, вставляет их в контекст модели - и та генерирует ответ. Данные не «зашиты» в модель, они подтягиваются динамически.
Что такое Reinforcement Learning простыми словами?
Модель пробует разные ответы, люди-оценщики ставят оценки. За хорошие ответы - «плюс», за плохие - «минус». Через миллионы итераций модель учится чаще давать ответы, которые оцениваются высоко.