
Компания OpenAI разработала ИИ-бенчмарк LifeSciBench, условия работы которого максимально приближены к реальной научной работе. Как оказалось, такой сценарий применения нейросетей до сих пор был сильно переоценён разработчиками последних.
Тестирование проводилось в метрике pass rate — когда задача считается решённой только при выполнении 70% рубрики. При этом бенчмарк заставляет ИИ работать в условиях неопределённости и требует анализировать «грязные» данные, как это обычно делают учёные в реальности.
Специальный тест содержит 750 вопросов, составленных разработчиками совместно с докторами наук из сферы биотехнологии и фармацевтики. Больше половины задач требуют работать не только с текстом промпта, но и с приложенными файлами, включая графики, таблицы и последовательности. Всё это позволяет сделать оценку более объективной по сравнению с метрикой Score (когда учитываются только отдельные ответы в выбранных категориях).
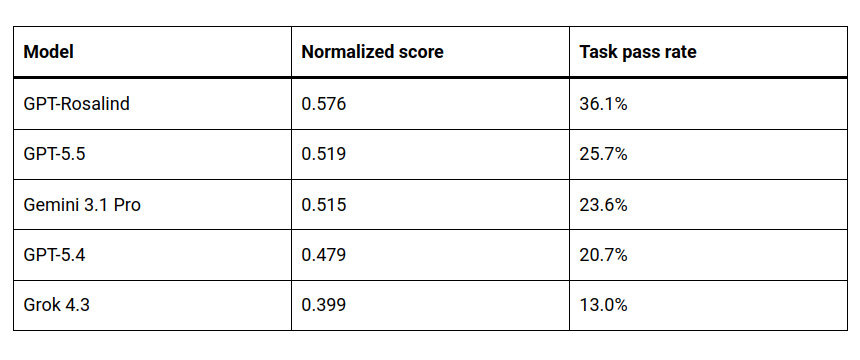
Согласно полученным данным, даже флагманская модель GPT-Rosalind в реальности выполнила лишь 36,1% поставленных задач. Лучшие результаты она продемонстрировала при изложении выводов, а хуже всего — когда требовалось выйти за пределы исходного текста задания.
Впрочем, это не худший результат в общем зачёте: например, модель GPT-5.5 набрала лишь 25,7%, Gemini 3.1 Pro — 23,6%, а Grok 4.3 — 13%. Claude от Anthropic по какой-то причине в тестировании не участвовала.
Для чистоты эксперимента бенчмарк прошёл независимую экспертизу, в рамках которой на вопросы ответили 453 рецензента, не участвовавших в составлении задач, 97% из них с докторской степенью. Уровень согласия экспертов превысил 96% в каждой категории: реалистичность, научная логика, обоснованность и общая полезность.