Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии Появились уровни thinking effort (включая Max) можно балансировать между скоростью/стоимостью и качеством. По агентскому кодингу GLM-5.2 зашел между Claude Opus 4.7 и 4.8 при сопоставимом расходе токенов Управление KV-кэшем, оптимизация ядер и CPU-планировщика преимущество по throughput растёт по мере увеличения контекста В пиковые часы 14:00–18:00 (UTC+8) GLM-5.2 расходует 3× квоту, в офф-пик — 2× (до конца сентября — акция 1×) Попробовать GLM Coding Plan в claude code включайте режим GLM-5.2[1m] для миллионного контекста HugginFace Github
GLM-5.2
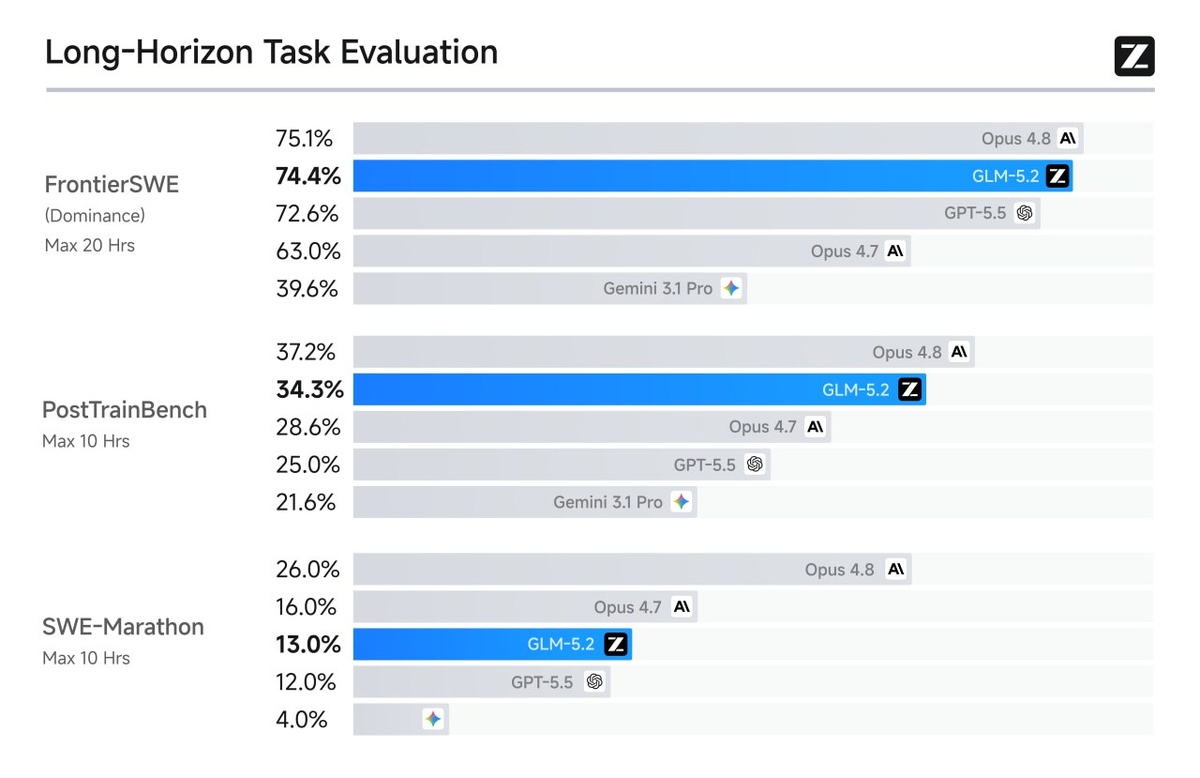
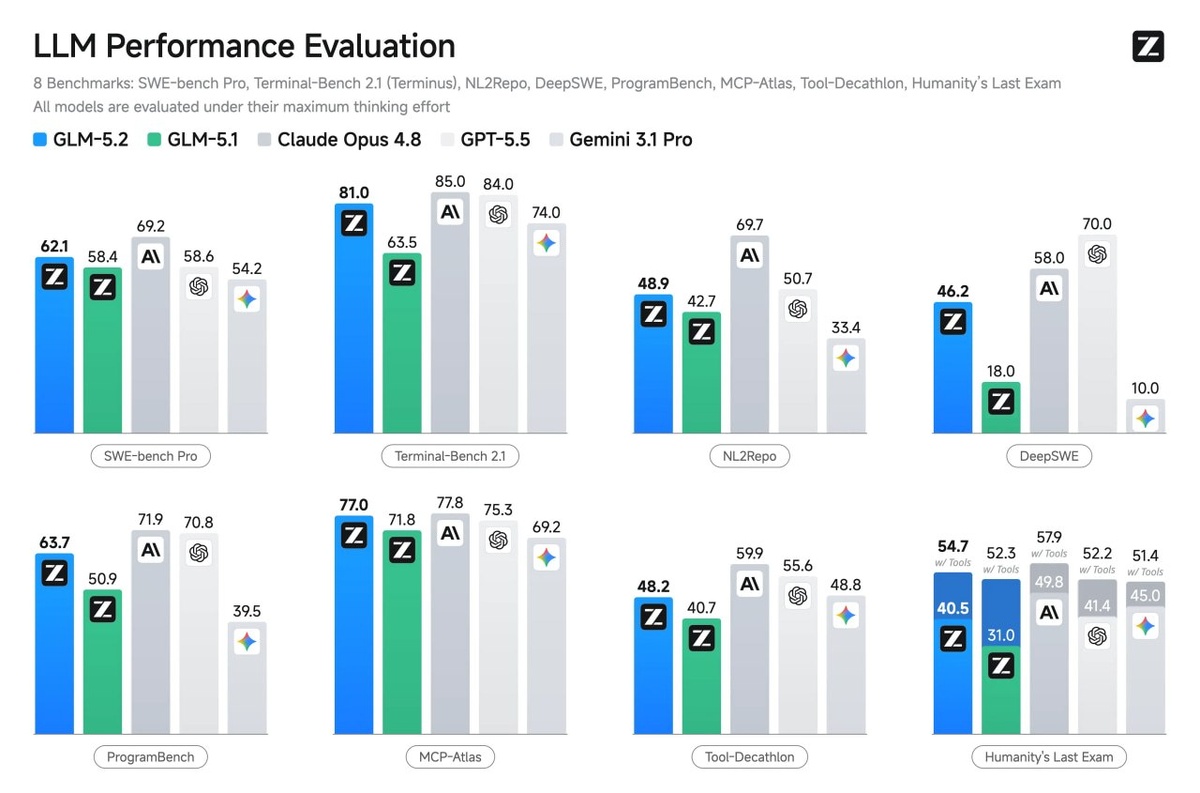
Обновка подъехала, китайский опенсорс кодер, долгие сессии кодинга, авто ресерч и тд. подобрался к Claude Opus 4.8 в плотную
Контекст 1М токенов, тренировали модель специально под длинноконтекстные кодинг сценарии
Появились уровни thinking effort (включая Max) можно балансировать между скоростью/стоимостью и качеством. По агентскому кодингу GLM-5.2 зашел между Claude Opus 4.7 и 4.8 при сопоставимом расходе токенов
Управление KV-кэшем, оптимизация ядер и CPU-планировщика преимущество по throughput растёт по мере увеличения контекста
В пиковые часы 14:00–18:00 (UTC+8) GLM-5.2 расходует 3× квоту, в офф-пик — 2× (до конца сентября — акция 1×)
GLM Coding Plan в claude code включайте режим GLM-5.2[1m] для миллионного контекста