Резервирование маршрутизаторов
Каждый, кто администрирует сеть, знает, что выход из строя основного шлюза, это ЧП. Но редко задумываются, что стандартное решение с двумя маршрутизаторами само по себе не панацея. Настоящая магия скрывается не в железе, а в том, как устройства договариваются, кто из них в данный момент «настоящий» шлюз для всей сети, используя общий, не привязанный к конкретному устройству адрес. https://seberd.ru/1869
Уязвимость шлюза по умолчанию
Шлюз по умолчанию, это точка выхода трафика из локальной сети. Если в этой роли выступает единственный маршрутизатор, он становится единой точкой отказа. Его отказ приводит к полной потере связи с внешними сетями и интернетом для всех внутренних узлов. В условиях требований к непрерывности бизнес-процессов и регуляторных норм, подобная архитектура неприемлема.

Архитектура резервирования: больше чем два устройства
Установка второго, резервного маршрутизатора — необходимый, но недостаточный шаг. Ключевой вопрос: как конечные устройства (компьютеры, серверы, камеры) поймут, на какой маршрутизатор теперь отправлять трафик? Вручную менять настройки шлюза на каждом устройстве — нереалистичный сценарий при аварии.
Решение лежит в абстракции. Вместо того чтобы указывать устройствам физический адрес одного из маршрутизаторов, им задаётся общий виртуальный IP-адрес (Virtual IP, VIP). Этот адрес не принадлежит ни одному устройству изначально. Задача протокола резервирования — сделать так, чтобы один из маршрутизаторов в любой момент времени «отвечал» за этот виртуальный адрес и обрабатывал направленный на него трафик.
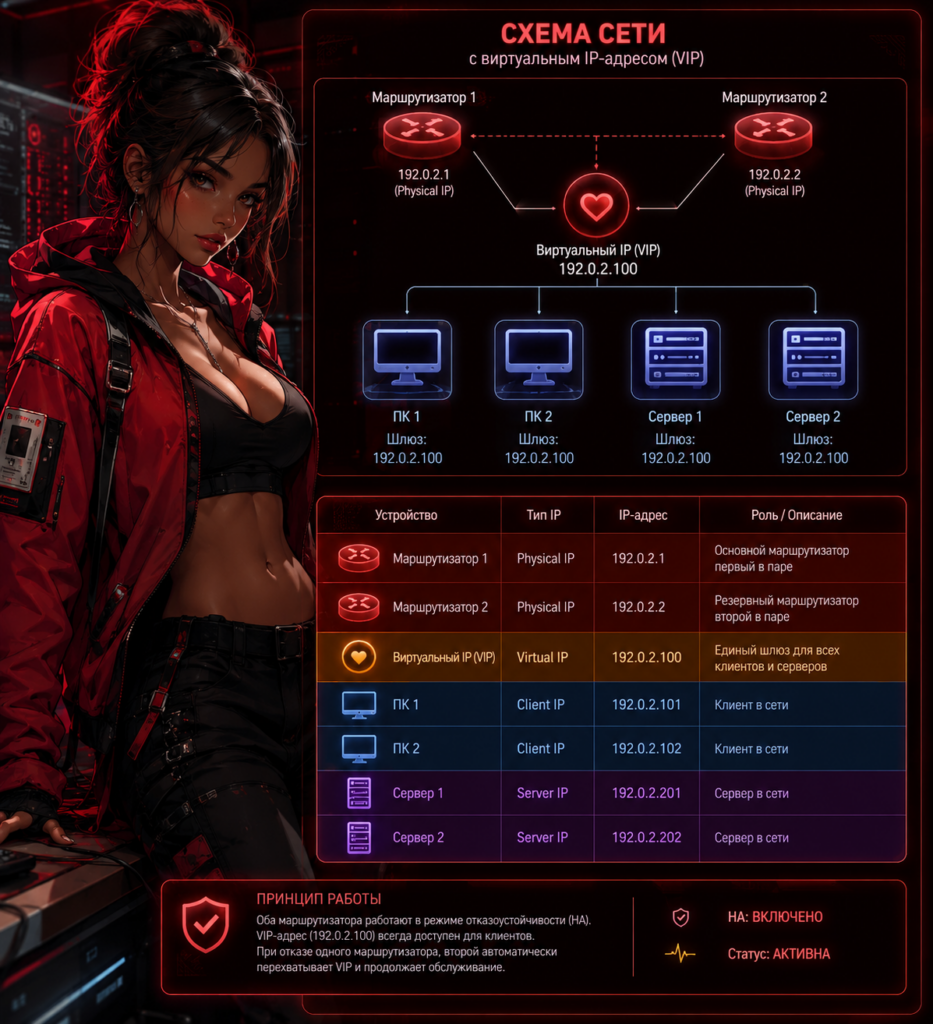
Механика работы протокола резервирования
Два или более маршрутизатора, участвующие в схеме, образуют группу. Используя свои реальные физические IP-адреса, они обмениваются служебными сообщениями (heartbeat) по внутреннему каналу (часто это одна и та же VLAN). Эти сообщения выполняют две функции:
- Держат группу в синхронизированном состоянии.
- Позволяют каждому участнику понимать, жив ли текущий активный маршрутизатор.
На основе заранее заданных приоритетов или конфигурации выбирается активный (Active) маршрутизатор. Именно он начинает «владеть» виртуальным IP-адресом и MAC-адресом, обрабатывая весь трафик шлюза. Остальные устройства в группе переходят в состояние резервных (Standby) и только слушают heartbeat.
Процесс перехвата управления (Failover)
Рассмотрим отказ активного устройства:
- Резервные маршрутизаторы перестают получать от него служебные сообщения.
- После истечения заданного таймаута они признают активного участника недоступным.
- Маршрутизатор с наивысшим приоритетом среди оставшихся (или согласно другому алгоритму выбора) немедленно берёт на себя роль активного.
- Он начинает отвечать на ARP-запросы для виртуального IP-адреса и обрабатывать входящий трафик.
Для конечных устройств в сети шлюз не изменился, это всё тот же виртуальный IP-адрес. Смена физического устройства, обрабатывающего их пакеты, происходит прозрачно, без изменения их конфигурации. Восстановление связи занимает секунды, что часто укладывается в таймауты TCP-сессий, позволяя многим приложениям продолжить работу без разрыва соединения.
First-Hop Redundancy (FHRP): суть концепции
Описанный механизм имеет общее название — резервирование первого прыжка (First-Hop Redundancy). «Первый прыжок», это первое сетевое устройство (маршрутизатор или L3-коммутатор), на которое попадает пакет, покидая свою локальную подсеть. Отказоустойчивость именно этого, критически важного «прыжка» и обеспечивают протоколы FHRP.
Сравнение протоколов резервирования
На практике используются несколько протоколов, реализующих одну идею с разными особенностями.
Выбор протокола зависит от состава оборудования, требований к нагрузке и нормативной базы. Например, в инфраструктуре, подпадающей под действие требований по информационной безопасности, предпочтение может быть отдано стандартизированному VRRP для упрощения аудита и обеспечения совместимости.
За пределами базовой конфигурации
Базовая настройка FHRP решает проблему отказа устройства, но не канала связи. Активный маршрутизатор может быть исправен, но его интерфейс, смотрящий во внешнюю сеть (uplink), — нет. Для защиты от такого сценария используется отслеживание интерфейсов (interface tracking). Если протокол резервирования отслеживает состояние внешнего интерфейса и видит его падение, он может в принудительном порядке понизить свой приоритет, заставив другого участника группы стать активным, у которого оба канала в порядке.
грамотно спроектированное резервирование первого прыжка учитывает не только жизнь самого маршрутизатора, но и доступность всех критичных для его работы путей.