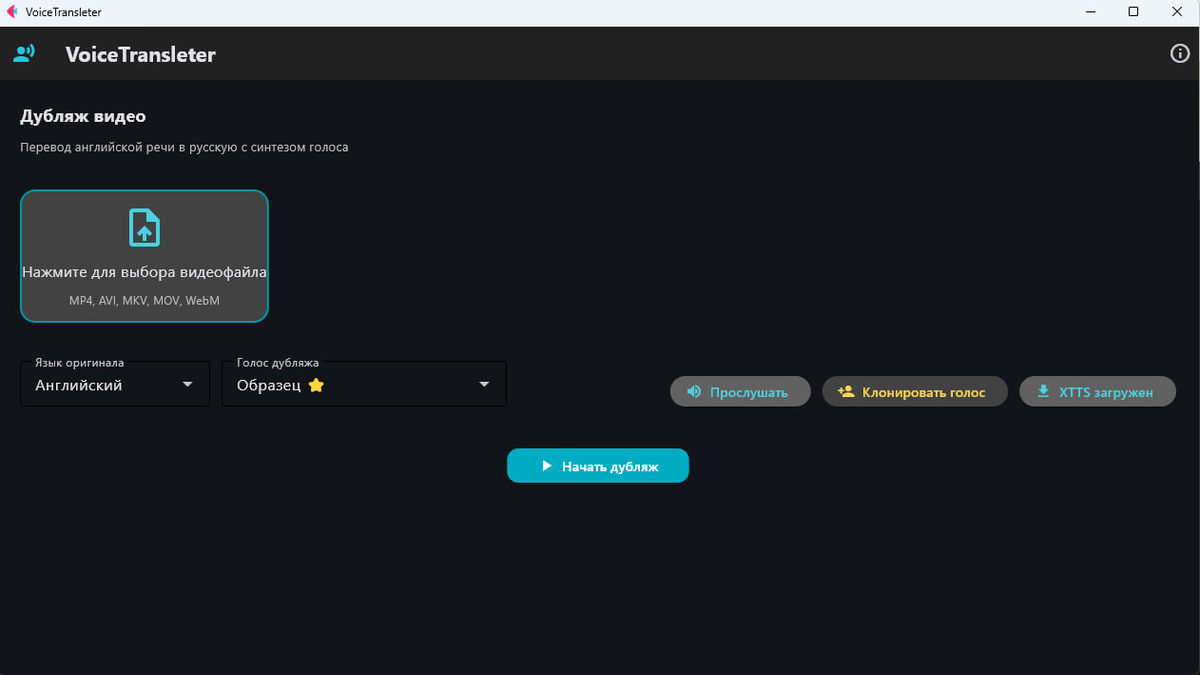
Дубляж видео с переводом английской речи в русскую с синтезом голоса.
Разработчик: Андраник Алавердян (AndranikFutureLabs)
Поддержка: @AndranikFutureLabs
Сайт: https://andranik-future-labs.ru
GitHub: https://github.com/AndranikFutureLabs/VoiceTransleterУстановка
Требования
Python 3.10+
FFmpeg (в PATH или в папке ffmpeg/)
8+ ГБ ОЗУ (рекомендуется 16 ГБ для XTTS)
Инструкция
Клонирование репозитория:
git clone https://github.com/AndranikFutureLabs/VoiceTransleter.git
cd VoiceTransleter
Создание виртуального окружения (рекомендуется):
python -m venv venv
# Windows:
venv\Scripts\activate
# Linux/Mac:
# source venv/bin/activate
Установка зависимостей:
pip install -r requirements.txt
Установка FFmpeg:
Скачайте FFmpeg с https://ffmpeg.org/download.html и поместите ffmpeg.exe, ffprobe.exe в папку ffmpeg/ в корне проекта, либо добавьте в системную переменную PATH.Подготовка образца голоса для дубляжа (для XTTS):
Поместите аудиообразец голоса в папку voices/ с именем Образец.wav (поддерживаются также .mp3, .m4a, .ogg).Пример:C:\VoiceTransleter\voices\Образец.wav
Рекомендации по образцу:Формат: WAV (предпочтительно) или MP3
Длительность: 5–15 секунд
Чистая речь без фонового шума
Запуск:
python main.py
Использование
Запустите программу: python main.py
Нажмите на область загрузки и выберите видеофайл (MP4, AVI, MKV, MOV, WebM)
Выберите язык оригинала (по умолчанию Английский)
Выберите голос дубляжа:Silero — встроенные голоса, работают без загрузки
XTTS — качественный синтез, требуется загрузка модели (~1.87 ГБ) и образец голоса
Нажмите «Начать дубляж»
Дождитесь завершения обработки (прогресс отображается в логе)
После завершения откроется карточка с результатом — можно открыть видео или папку
Результаты
После обработки в папке output/ создаются:*_dubbed.mp4 — готовое видео с дубляжом
*_source.txt — исходный текст с таймингами
*_source_plain.txt — исходный текст без таймингов
*_translation.txt — перевод с таймингами
*_translation_plain.txt — перевод без таймингов
*_source_translit.txt — транслитерация оригинала (En→Ru) с таймингами
*_source_translit_plain.txt — транслитерация оригинала без таймингов
*_translation_translit.txt — транслитерация перевода (Ru→La) с таймингами
*_translation_translit_plain.txt — транслитерация перевода без таймингов
Клонирование голоса
Нажмите «Клонировать голос»
Выберите аудиообразец (3–10 секунд, чистый голос)
Введите название голоса
Нажмите «Клонировать»
Структура проекта
VoiceTransleter/
├── main.py # Графический интерфейс
├── config.py # Конфигурация
├── requirements.txt # Зависимости
├── ffmpeg/ # FFmpeg (скачать отдельно)
├── voice_transleter/ # Основной модуль
│ ├── pipeline.py # Пайплайн обработки
│ ├── audio_extractor.py # Извлечение аудио
│ ├── transcription.py # Транскрибация (Whisper)
│ ├── translator.py # Перевод
│ ├── tts.py # Синтез речи (Silero / XTTS)
│ ├── video_renderer.py # Сборка видео
│ └── voice_cloner.py # Клонирование голоса
├── voices/ # Образцы голосов
├── models/ # Скачанные модели
├── temp/ # Временные файлы
└── output/ # Результаты
Технологии
Whisper (faster-whisper) — распознавание речи
Google Translate / LibreTranslate — перевод
Silero TTS / XTTS v2 — синтез речи
FFmpeg — обработка аудио/видео
Flet — графический интерфейс