DiffusionGemma
Гугл дипмайнд выпустили экспериментальную открытую модель, которая генерирует блоки текста одновременно с помощью диффузии, вместо генерации по токену
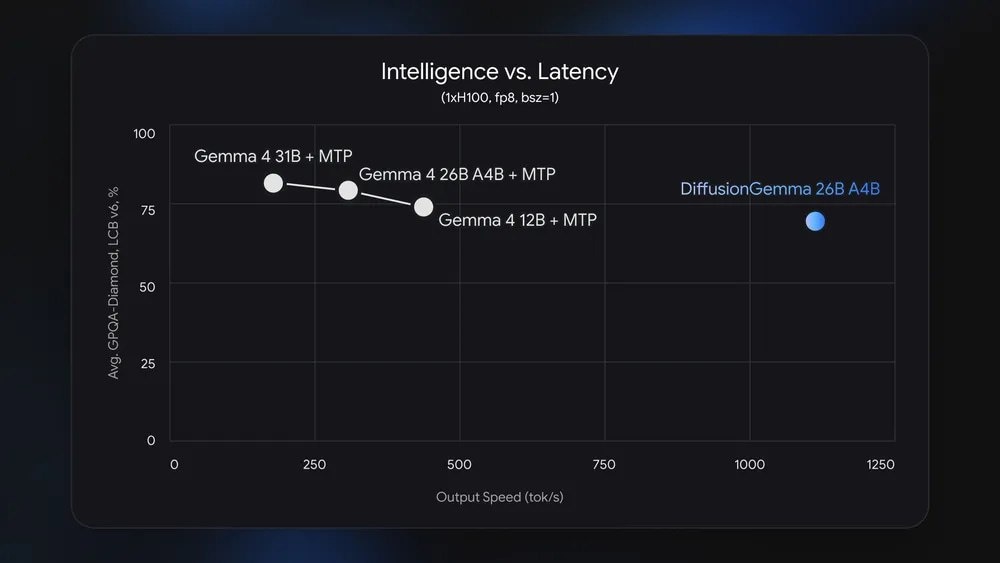
Результат: до 1000+ токенов/сек на NVIDIA H100 и 700+ токенов/сек на RTX 5090
LLM работают как печатные машинки, буква за буквой генерируют, токен за токеном, а диффужион гемма сразу выдает 256-токенный блок текста за один проход, а потом итеративно его уточняет, такой же принцип как генерация картинок из шума
Модель построена на архитектуре Gemma 4 26B A4B с новой диффузионной головой, унаследованной от исследований Gemini Diffusion
🔘Технические характеристики
25.2B параметров (активные 3.8B), контекст до 256К токенов, canvas (блок генерации) 256 токенов, поддерживает тексты и картинки, обучена на 2025
🔘Скорость
Модель смещает узкое место с пропускной способности памяти на вычисления поэтому даёт до 4× ускорения на выделенных GPU
🔘Помещается в 18 GB VRAM
Благодаря MoE с 3.8B активных параметров и квантизации модель влезает в RTX 4090/5090.
🔘Самокоррекция
Модель итеративно дорабатывает собственный вывод, исправляя ошибки в реальном времени.
🔘NVFP4-оптимизация
Совместно с NVIDIA сделана поддержка 4-битного floating-point на Hopper/Blackwell почти без потерь точности
vLLM (с интеграцией от Red Hat)
MLX для Apple Silicon
Unsloth для файнтюна
Hackable Diffusion модульный JAX-тулбокс от Google