
Всем привет, сегодня мы будем решать вот такую задачу
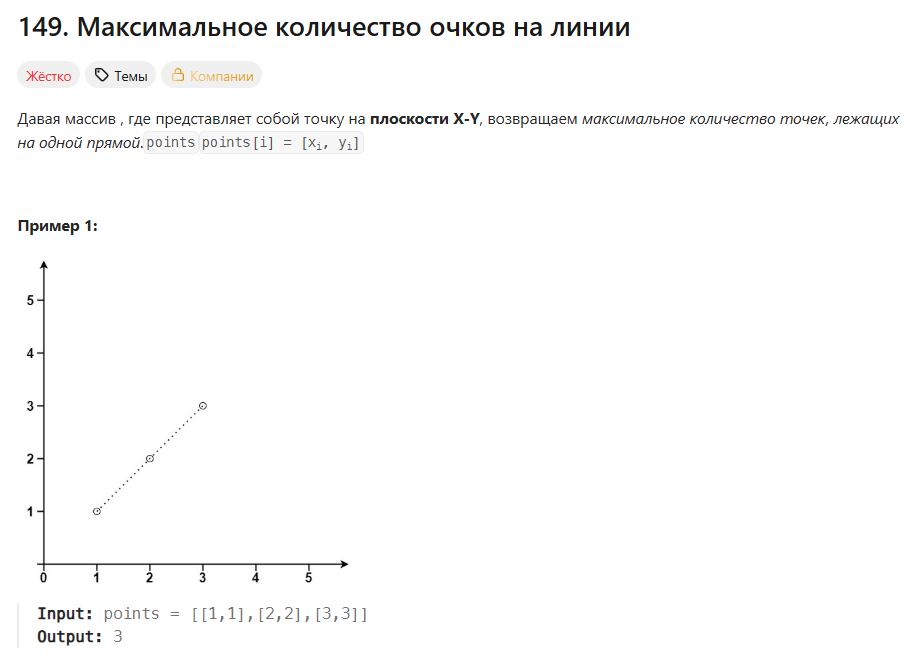
Нам даётся массив с точками, которые для удобства можно нарисовать на графике. Между этими точками можно провести прямые линии.
Нам нужно найти прямую линию, которая может соединить больше всего таких точек, а потом вывести их количество.
Нам придётся придумать способ, который будет правильно вычислять количество точек и делать это быстро.
Сегодня у нас задача уровня "Hard", мне кажется, задачи такого уровня в своём блоге я ещё не решал.
Из всех, кто решал эту задачу, справилось только 30.8% разработчиков.
Для тех, кто не знал, процент решаемости это не показатель сложности задачи. Это не процент от всех программистов. Здесь учитываются именно те программисты, которые увидели условия задачи, плашку "hard", и после этого начали её решать. Это процент от тех, кто вообще за неё взялся.
Так что 30.8% это серьёзно.
Я не знаю точно, смогу ли я решить вообще эту задачу и довести её до конца. А оптимизировать её будет ещё сложнее, наверное. Думаю, там есть эффективные математические методы, о которых я не знаю. Но я просто попытаюсь решить её, опираясь на свои знания.
Давайте попробуем.
Приступаем к обдумыванию задачи
Для обдумывания возьмём второй пример, там точек больше. Проведу между точками линии, для примера
У каждой линии есть своя формула. Например, у линии с 4-мя точками, формула такая: y = 5 - x.
Допустим, точка на X = 1 имеет Y = 4 (5 - 1)
Точка на X = 2 имеет Y = 3 (5 - 2)
Я предлагаю при помощи цикла проходиться по каждой паре точек и для них находить эту самую функцию
А потом создать ещё цикл, который будет проходиться по всем точкам и сравнивать, подходят ли они под эту формулу или нет
Нам нужно найти самое большое число точек, которые подходят под одну формулу. Это значит, что все они на одной линии. Их число мы должны вывести по задаче.
Вроде бы способ достаточно простой с виду. Но как это будет реализовано на практике? Как высчитывать эти формулы? Столкнётся ли такой способ с трудностями в оптимизации? Это нам предстоит выяснить.
Начинаем решать задачу
Давайте начнём.
Так, нужно настроиться... Сегодня мы решаем задачу на хардах (hard).
Так. Запишем длину нашего массива в переменную и сделаем двойной цикл, который будет проходиться по каждой паре точек. Добавляем проверку "i != j", чтобы не сравнивать точку саму с собой.
Думаем...
Для примера я нарисовал вам две точки и подписал их координаты. Чтобы найти формулу линии, нам нужно узнать, насколько сильно координата точки на линии изменяется по y, при прибавлении x на 1.
Сначала нам надо найти разницу X-ов этих двух точек. Из X одной точки вычитаем X другой точки. На примере это будет 3.
Потом находим разницу Y-ов. Вычитаем из Y одной точки Y другой точки. На примере это будет 2.
А потом это поделить. В нашем примере получилась дробь 2/3. Это коэффициент, который надо будет умножать на X, чтобы куда-то двигаться.
Но это ещё не всё. Если проверить такую формулу на X = 1, получится 2/3, а у нас в той точке Y = 1.
Тоже самое и для X = 4. Y = 2.333, а у нас там Y = 3.
Нам нужно прибавить какое-то число, чтобы получившиеся значения дошли до реальных Y.
Чтобы узнать какое, умножаем X на нашу дробь. А потом это вычитаем из реального Y.
При X = 4 получилось 8/3, а реальный Y = 3. Вычитаем из одного другое
3 - 8/3 = 1/3. Получаем 1/3, то есть 0,333.
Теперь объединяем две части и получаем формулу.
Получилась формула "y = (2/3)x + 1/3"
Проверим на x = 4
y = (2/3) * 4 + (1/3) = 8/3 + 1/3 = 3. Верно.
Вот так и считаются формулы для прямых. Поэтому и задача уровня "hard", так как не все программисты владеют геометрией. Хотя я геометрию в школе любил 😀. Или это алгебра. В общем, я любил и то, и то, особенно графики.
Ребят, если для вас это сложно, вы не видели ещё параболу и синусоиду 😀
Попробуйте ка тут высчитать формулы 😃.
У нас обыкновенные линейные функции.
Вернёмся в наш код и постараемся реализовать это на деле.
В общем, делаем всё, что мы делали на схеме. Чтобы вы не запутались, уточню: points - массив с массивами
points[i] - массив из двух координат [x, y]
points[i][0] - x выбранной точки
points[i][1] - y выбранной точки
Я выведу все получившиеся формулы в консоль для проверки
В первом примере от задачи формула для выделенной линии y = x
Во втором примере y = 5 - x
В консоль я выведу формулы в таком виде: сначала часть с X, а точнее число от туда, а потом выведу второе число. Наши формулы должны быть выведены так:
1) 1, 0 (то есть 1x + 0)
2) -1, 5 (то есть -x + 5, или же 5 - x)
Первую формулу он посчитал правильно, часть с иксом "1x", а с числом "+ 0". Вместе это выглядит как "1x + 0", или сокращённо просто "x".
Для второго примера всё иначе. Если что, он вывел все возможные коэффициенты для формул.
Меня напрягает бесконечность (Infinity). Так быть не должно.
В этом случае сравнивались две точки, которые находятся на одном, x. То есть вертикальная линия. Поэтому и получается бесконечность.
Расстояние между 1 и 1 это 0, а если мы поделим это на разницу Y, получится (4 - 1) / 0. На ноль нельзя делить, бесконечность получится.
Выглядит это так, и если подумать, в таком случае мы не сможем рассчитать по этому способу линии. Нельзя придумать такую функцию, чтобы для x = 1, y был одновременно 1 и 4.
Но наш способ можно дополнить, мы можем придумать второй способ, который будет искать вертикальные линии отдельно. Он будет искать переменные с одинаковыми X и одинаковыми Y.
Проверка для таких точек будет проходить здесь, а мы вернёмся к нашим графикам
Точка (1, 1) сравнивается с точкой (3, 2) и получается "y = 0.5x + 0.5"
Если подставить эти точки, получается правильно.
Но нас интересуют 4 точки большой линии.
Да, всё верно. "-1 5" появляются (таким образом я вывожу формулы, типа y = 5 - x)
Сделаем массив, где будем хранить эти формулы.
Сделаем код, чтобы массив хранил только уникальные формулы. Будет проверка, по которой в массив будут добавляться только те формулы, которых нет.
В массив мы будем записывать формулы в виде строк "5x+1". Можно по компактнее, "5+1". Мы записываем в виде строк, чтобы с ними могла работать функция .includes(), для проверки наличия их в массиве.
В виде массива с числами [5, 1] так сделать не получится, эта функция так не умеет.
Надо что-то делать с вертикальными линиями, у которых только один X, но разные Y. Пусть записываются в отдельный массив, я назову его "mass_line_x", туда я буду записывать только x.
И да, я пришёл к выводу, что точки на одной линии с одинаковыми Y быть могут, только с одинаковыми X не могут. Если у линии везде один Y, то его формула будет просто "y = 3" или "y = 2", так тоже можно.
Придётся поменять условия и оставить только равенство X. В новый массив мы будем добавлять координату X, где находится такая точка.
Вот вам ещё раз картинка с вертикальной линией.
Теперь все формулы записаны в вот таком виде:
Вертикальные линии: [1, 4, 10] (массив mass_line_x)
Остальные линии: ["1+5", "2+4", "-1+6"] (массив formula_mass)
Сделаем цикл, который проходится по массиву "mass_line_x" с координатой x вертикальных прямых, который считает количество точек. Сколько точек с координатой X, как в массиве, столько и точек на этой вертикальной линии.
А это код для подсчёта точек в обычных прямых. Сначала он разделяет строку типа "10+4" на массив ["10", "4"]. Потом он с этими числами проходится по всем точкам, эти "10", "4" переводит в int и создаёт формулу.
Если значение по формуле совпало с Y точки, то эта точка относится к линии и "count" для этой формулы прибавляется. А там уже ищется максимум.
Кстати, очень важно сделать округление, когда мы получаем ответ от формул типа "(5/3)x + 2". JavaScript плохо округляет, и маленькие незначительные хвостики, по типу 2.3334 могут не быть равны 2.3333. (54 строчка кода).
Ух, запускаем...
Да, заработало!!
А теперь самое страшное... Большая выборка данных
Проверяем на больших данных
Код прошёл 23 кейса и завалился на графике с одной точкой
У одной точки тоже может быть линия.
Сделаем обычную проверку и идём дальше.
Так, а здесь что не так?
На графике это выглядит так, две линии, и на одной из них пять точек.
Почему у нас шесть?
Возможно, виноват Math.round(), линии близко, а он их сильно округляет. Он вообще убирает точки. Например, из числа 123.444, он сделает 124.
Нам понадобится ".toFixed()". Он способен округлять числа до нескольких знаков, после запятой. Но работает он странно, после округления выводит вместо числа строку, и нам придётся ещё в число обратно преобразовывать.
Да!! А вот теперь настало время больших умов!!! 😃. Настало время оптимизации.
Приступаем к оптимизации
В этом коде есть много чего, что можно оптимизировать.
Например, в конце можно один раз получить переменные коэффициентов, сразу вытащить их из массива и преобразовать в числа, а не делать это каждый раз в формулах.
В нашем коде несколько раз просчитываются points[i][0], нужно создать отдельные переменные.
ix, iy - координаты для точки i
jx, jy - координаты для точки j
Также у нас в массив постоянно добавляются элементы. Если вы изучали С, то знаете, чтобы изменить размер массива, нужно его пересоздать. Получается, когда мы добавляем в массив элементы, JavaScript приходится каждый раз его пересоздавать, выделять больше места в памяти для нового массива и тратить на это время.
Здесь можно сделать то же самое, просто создаём большой массив, длиной в n, заполняем его нулями, а потом храним там, что хотим.
Это можно сделать при помощи "new Array(n)", а потом ".fill(0)". Если мы просто сделаем массив "[]" и будем добавлять нули через "mass.push(0)", это будет такой же динамический массив, который будет пересоздаваться.
Эта функция оптимизирована, с помощью неё можно сделать нормальный статический массив.
А нет, лучше заполнить их null, так как в "mass_line_x" могут быть нули.
Создаём массивы длины n, заполняем их нулями, а также создаём переменные индексы для работы с такими массивами. Мы же должны ориентироваться, какой элемент массива мы должны заполнять, по последнему элементу ориентироваться больше нельзя.
Здесь тоже меняем всё, по индексам загружаем данные в массив, не забываем увеличивать индексы на 1.
В последних циклах добавляем проверку на этот самый null, если он есть, данные закончились
Переменные "distance_x" и "distance_y" можно удалить, так как они используются всего один раз, а вычисления из них сразу подставить в "formula_one".
Кстати, очень важно удалить все "console.log()", которые я использовал для проверки, потому что они тоже тормозят код.
У нас используются строки и записи формул типа "5x+4", потому что в таком виде их можно быстро найти в массиве через includes. А в виде чисел это сделать не получится, так как массив [1, 2] через него найти нельзя будет, с массивами функция ".includes()" не работает. Но мы можем написать функцию, которая будет просматривать массив и искать [1, 2] сама.
Вот
Меняем здесь с ".includes()" на "include_coord()".
И здесь меняем. Вот, как стало компактно. Теперь наши формулы записываются не в виде "5+5" (по-нашему старому стилю это "5x + 5"), а в виде [5, 5]. Это будет быстрее. Мы убрали строки и заменили их массивами с числами.
Но код по-прежнему не дотягивает по оптимизации, мы не можем завершить задачу.
Я попробовал с помощью сообщений в консоль найти проблемное место в коде. Я разбил код на части и начал выводить сообщения в зависимости от того, на каком этапе выполнения сейчас код.
Наш код застрял на массиве, где мы точки собираем и выводим формулы. Сообщение "Массивы заполнены" не было выведено.
Наш код застревает на 53-ей итерации из 300.
Я пришёл к выводам, что координаты для точки i не нужно объявлять каждую итерацию цикла с j, этого достаточно сделать в цикле с i. Это лишние действия.
В конце каждой итерации цикла по i, я вывожу в консоль "i" и "n". Это способ ориентироваться, насколько мы близки к оптимизации кода. Чем больше итераций успело завершиться, тем код оптимизированней.
А что, если я начну отключать куски кода, чтобы смотреть, как та или иная часть скажется на оптимизации?
Нет, если мы отключим эту часть, мы и не дойдём до кейса с большим количеством чисел. Нужно сделать проверку.
Кейс с большим количеством чисел имеет n = 300. Вот и будем при такой n отключать этот кусок кода
Чтоо??? Я отключил жизненно важный участок кода, как такое возможно!?!? То есть, если отключить забивание формул для огромного кейса, всё так просто решится???
Странно...
Слушайте, а ведь по этой панели можно смотреть время выполнения кода и понимать, насколько сильно мы приблизились к оптимизации. Он не будет учитывать наш кейс с 300 точками, но он всё равно считает время выполнения из других кейсов.
Я попробовал вернуть динамические массивы [ ], которые дополняются в процессе, почему-то код начал выполняться быстрее.
Так, я проверил и понял, когда у нас остановился код, в массиве было 14780 элементов, их было не 300. Это много... Я протупил, когда задал статическому массиву размер n.
Я вот думаю, а давайте посмотрим элементы массива. Давайте попробуем это как-то визуализировать. Может на схеме мы можем увидеть что-то интересное.
Я написал у себя на компе вот такой код для визуализации этих данных
Выглядит это так.
Ну, ничего такого, за что можно было бы зацепиться, я не вижу. Я надеялся, там будет огромная вертикальная линия и какой-то простой, но большой случай. А здесь очень много точек.
Я понял, что происходит с нашим массивом.
1. Сначала у нас есть массив с null, который имеет размер в n элементов.
2. Потом мы заполняем его массивами, которые занимают больше места, чем null, или какое-либо число. Память выделена под null в массиве, а теперь эта ячейка должна по размеру стать больше, так как теперь туда записываются данные типа [1, 2]. Тоже вычислительные мощности тратятся.
3. Потом мы доходим до границы массива, массив заканчивается, а наши формулы нет. После окончания 300 элементов массива, JavaScript их добавляет дополнительно и увеличивает размер массивы. Мы вернулись к тому же динамическому массиву, от которого ушли.
Вот так вот. Мы не особо то и далеко ушли от статических массивов, наш динамический массив вернулся. У нас элементов в кейсе с большими значениями не "n = 300", а около 10000. Конечно, будет зависать. Мы сделали полу-динамический двумерный массив.
Давайте попытаемся рассчитать максимальную длину массива
Тут не просто рассчитать, так как у цикла с j количество итераций постоянно уменьшаются. А давайте просто будет n на n? 300 на 300 = 90000, не так уж и много.
Давайте не будем считать, какое максимальное число формул будет, а просто попробуем сделать размер массива n на n и посмотреть, что же будет с производительностью.
Так, мы замедлились...
Возможно, нам нужно другое решение. А если вообще отказаться от использования двумерных массивов, и использовать одномерный? Где две переменные стоят парами, а эти пары мы будет определять по индексу?
Это будет не двумерный массив, а одномерный. По одномерному массиву коду будет перемещаться легче. Но данные должны быть связаны друг с другом, путь первым коэффициентом будет нечётное число, а вторым чётное.
Я что-то подобное реализовывал в предыдущих статьях.
Предлагаю временно вернуться к динамическим массивам, так как мы не знаем точно, сколько нам нужно будет значений.
Делаем так, меняем функцию "include_coord()", теперь у неё будет три аргумента.
Снова добавляем данные в массив через обычный push().
Нам нужно ещё будет переписать функцию "include_coord()" внутри.
Отбросим все проверки на null. У нас теперь три аргумента, мы передаём два коэффициента вместе. Мы будем искать места, где нужные коэффициенты стоят в паре.
Рассказываю, как это работает. Наш массив разбивается на пары. Количество пар это длина массива, поделённая на два. Мы проходимся по всем этим парам и выбираем оттуда первое и второе число.
Чтобы получить первое число, используем i * 2.
Чтобы получить второе, к этому i * 2 прибавляем 1.
Вот так и работает моя задумка. Метод придумал я сам, нигде не смотрел, честно!!
Так, теперь переписываем этот участок кода. Проверка точек на совпадение с формулами. Теперь не надо делить строку "3+5" на 3 и 5, можно просто получить числа из массива.
Ого, мы очень сильно продвинулись
Оказывается хранение данных по парам в одномерном массиве намного эффективнее, чем хранение массивов из двух данных в двумерном массиве.
То есть [1, 2, 3, 4, 5, 6] эффективнее, чем [[1, 2], [3, 4], [5, 6]].
Но помните, это всё работает, потому что мы кейс с 300 точками проскакиваем, а так делать нельзя. Нам нужно, чтобы наш код все примеры обрабатывал, его нужно достаточно разогнать.
Мы устранили проблему с записью формул, теперь наш код делает это быстрее.
Так, я узнал, что цикл "for ... in" предназначен для объектов, а для массивов нет. С массивами он будет тормозить, поэтому надо обычный цикл использовать. Нужно заменить его на "for(j = 0; j < n; j++)"
Я попробовал вывести через консоль количество формул в массиве, их слишком много, 44131.
Слушайте, а я вот тут думаю. А может ли быть такое, что одинаковые формулы с разными хвостиками из за своих отличий попадают в массив?
Например, какая-нибудь (y = 2.11111x + 2.11111) и (y = 2.111112x + 2.111112).
Мы всё равно потом округляем ответы, но из за хвостиков у коэффициентов может получиться много разных формул в массиве и это дополнительная нагрузка.
Когда мы делим разницу Y на разницу X, это мы округляем до 7 знаков после запятой.
И уже получается совершенно другой результат. Нам нужно проверить не 41 тысячу формул, а всего 117. Но ответ получается не правильный.
Я попробовал поиграться с округлениями, поставить значения 6 и 3, и мы уже продвинулись до 37 кейса
Здесь нам нужно по лучше округлить ответы, а то до -1, 1 и 3 не дотягивают (-1.0003, 0.9997, 2.9997)
Попробуем округлить ответ до 2.
И да, мы на предпоследнем кейсе!!!
У нас есть нулевая точка, а также две точки, которые находятся друг от друга очень далеко.
А здесь у нас наоборот, проблемы с точностью. Первая и третья точка находятся на одной линии, а вторая нулевая точка рядом с ней, но не на ней.
Из за коэффициента -0.001, который почти 0, у нас и возникает такая проблема. Хотя нет, проблема в ответе, который округляется до двух знаков. Этого мало, чтобы заметить, что 0 отклоняется на 0.001.
Я попробовал округлить ответ до 3 знаков, после запятой, и получилось это
Почему точки другие, а кейс также 41?
Я попробовал в конце кода, прямо перед "return" вывести в консоль ответ (Я его синим выделил). Он вывелся, но код всё равно завершился тем, что время вышло.
Я не знаю, как такое может быть, если код досчитывает результат до конца. Возможно, примеры вместе рассчитываться не успевают. А у нас предпоследний кейс, надо поднажать.
Попробуем ещё. Попробуем вынести объявление переменных через "let" за пределы цикла. Мы один раз выделим место для данных для coef1, coef2, и будем с этим местом для данных работать, а не объявлять и выделять каждую итерацию заново.
Ну и "let" от "i", "j" из циклов тоже вынесем.
До меня дошло, что же здесь происходит, как это можно оптимизировать.
Наш динамический массив обновляется дважды. Мы сначала одну переменную в него добавляем, и он пересоздаётся, а потом другую. Я узнал, что можно эти элементы записать через запятую, и массив обновится только один раз. Он добавит в себя сразу две переменные за одно обновление.
Кстати, забыл тут переписать. Конструкция "for ... in" эффективна для объектов, для циклов быстрее будет обычный "for". (Это циклы для вертикальных линий)
Нам надо ещё немного сжать наш код, чтобы он доработал до конца 42 кейсов.
Так, в интернете я нашёл способ для быстрого округления чисел
Работает он так:
1 ) Нам надо округлить число до какого-то количества знаков, после запятой, например 3. Нам нужно передвинуть эту точку вправо на такое количество цифр. Для этого нам надо умножить число на 10 в степени 3, то есть 1000.
2) После этого мы округляем через Math.round(). Функция округляет без точек, упрощённо. Но даже так, она помогает нам быстро посчитать.
3) После этого обратно делим на то же число, то есть 1000. Получаем нужное значение.
Применяем
Даа!! О чудо!! Эта жесть, которую я писал несколько часов подряд, заработала!!!
В общей сложности, на эту статью и задачу я потратил более 10 часов... Я решал задачу, перебирал множество разных методов, всё это записывал в статью, в решении задачи ошибался, потом статью переписывал и убирал свои ошибки, чтобы удобно было читать. Я очень много думал, писал код, редактировал статью и рисовал для неё разные схемы. Так что знайте, чего стоит мой труд 😃.
Так, ну всё, я написал этот большой код, сейчас я вам покажу его полностью, а потом мы его протестируем на каких-нибудь интересных примерах
Тестируем на интересных примерах
Тестовый пример 1.
В случае с такими линиями, код выводит 4. Он прав.
Тестовый пример 2
Код вывел 5. Хорошо.
Тестовый пример 3
В этом примере он вывел 4, и правильно. Это линия с самым большим количеством точек.
Тестовый пример 4
Вот, очень хорошо. Код прекрасно работает!!
Ну а вы не забывайте подписываться на канал и ставить лайки 😃. Я эту статью 8-10 часов делал, приблизительно, вы чего!! Я до самой ночи засиделся уже.
Ладно, подписывайтесь на канал и ставьте лайки 😄😃