Забудьте о бесконечных промптах и попытках объяснить нейросети архитектуру вашего проекта. Представьте AI-ассистента, который с полуслова понимает ваши внутренние библиотеки, знает специфические паттерны, которые вы используете, и пишет код в точном соответствии с вашим код-стайлом.

Звучит как магия? На самом деле, это стандартный процесс файн-тюнинга (дообучения) открытой LLM на вашем репозитории. Сегодня мы разберем, как превратить ваш GitHub-архив в персональную модель, используя метод LoRA. Мы не будем тратить тысячи долларов на серверы — всё можно сделать бесплатно в Google Colab за один вечер.
Почему обычные промпты не работают с вашим кодом?
Контекстное окно даже самых современных моделей ограничено. Если вы загрузите в чат весь свой проект на 100 000 строк, модель либо «забудет» начало, либо начнет галлюцинировать.
Решение — дообучение (Fine-Tuning). Мы берем базовую модель (например, Qwen2.5-Coder или Llama 3) и «впечатываем» в её веса знания именно о вашем коде.
Шаг 1. Подготовка данных: превращаем код в датасет
Нейросети не учатся просто по факту чтения кода, как люди. Им нужен формат «Вопрос — Ответ» (Instruction Tuning). Нам нужно пройтись по вашим файлам и создать JSONL-файл, где каждая функция или класс будет отвечать на какой-то запрос.
Напишем простой Python-скрипт, который соберет .py
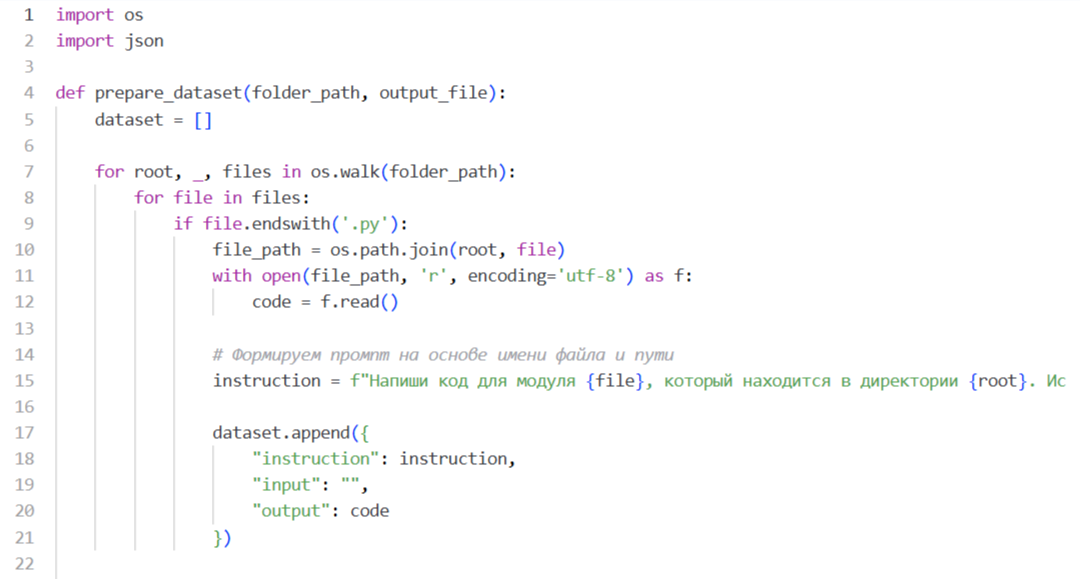
Лайфхак: Если у вас есть документация или комментарии к сложным функциям, обязательно включите их в instruction. Чем больше контекста «зачем этот код нужен», тем умнее будет модель.
Шаг 2. Магия LoRA: обучаем быстро и без сгорания видеокарты
Полное обучение модели на миллиарды параметров требует дата-центра. Но мы используем LoRA (Low-Rank Adaptation). Этот метод «замораживает» веса базовой модели и дообучает лишь крошечные надстройки (адаптеры).
Это снижает требования к видеопамяти (VRAM) в 3-4 раза. Модель на 7-8 миллиардов параметров спокойно обучится на бесплатной Tesla T4 в Google Colab.
Вот базовый скелет кода для запуска обучения через библиотеку trl (Transformer Reinforcement Learning):
Шаг 3. Тестируем «Франкенштейна»
После обучения у вас появится папка с адаптером (обычно весит всего 50-100 МБ). Теперь самое интересное — заставляем модель писать код, опираясь на ваши наработки.
Что вы получите на выходе?
Модель не просто напишет парсер. Она использует ваши импорты, ваши кастомные исключения и ваш подход к обработке ошибок, потому что она «видела» это сотни раз в вашем датасете.
Обучение LLM на собственном коде — это не фантастика, а рутина для современного разработчика. Персональная модель экономит десятки часов на онбординге новых сотрудников в проект и позволяет создать IDE-плагин, который реально понимает специфику именно вашей компании.
А какой AI-инструмент используете вы? Пишите в комментариях! 👇
Читайте также:
Генерация микросервисов с ИИ: архитектура + код (практический гайд)
AI для DevOps: как автоматизировать CI/CD пайплайны
Claude 3.5 vs GPT-4o для программирования: честное сравнение