Система — это не сумма частей, а результат их взаимодействия
Russell Ackoff
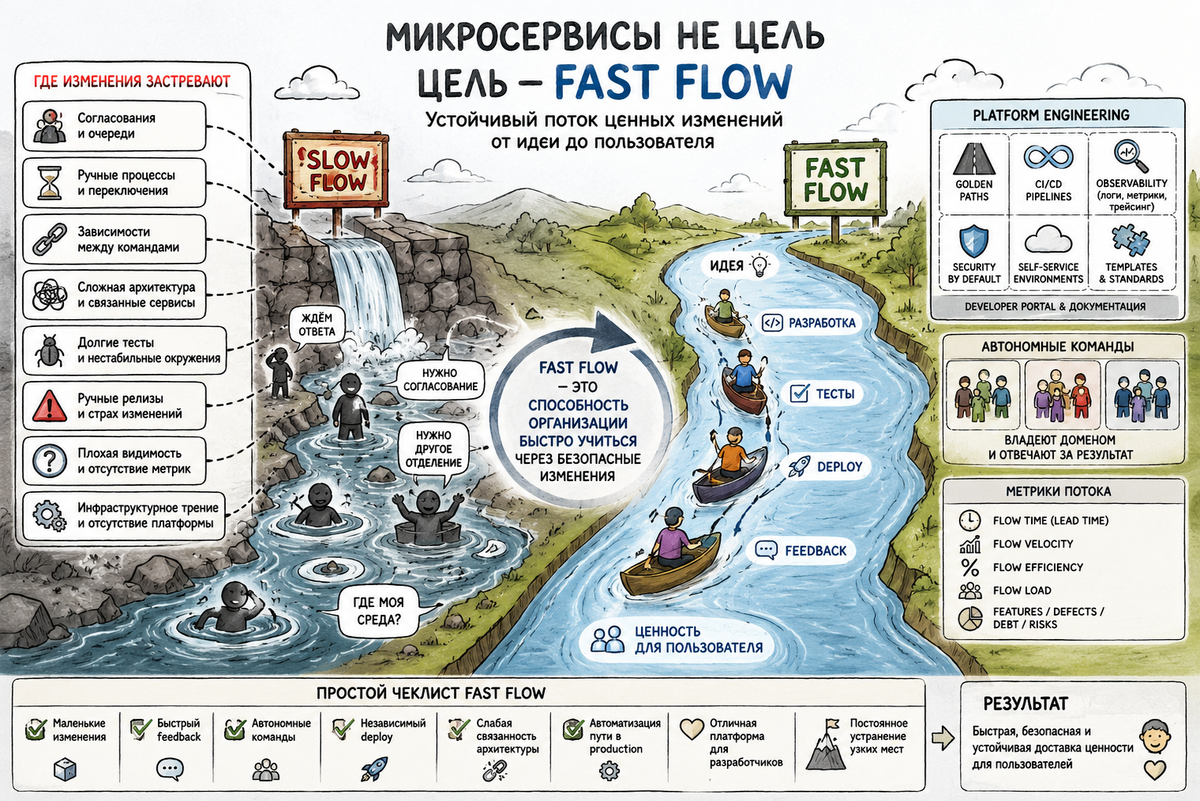
В первой части главная мысль была такая: микросервисы не цель. Цель — Fast Flow, то есть устойчивый поток ценных изменений от идеи до пользователя.
Теперь практический вопрос: что должно быть вокруг команд и архитектуры, чтобы этот поток реально появился? Здесь в картину входят Platform Engineering, метрики, AI-инструменты и простой чеклист, который показывает, где изменения застревают.
1. Почему здесь появляется Platform Engineering
Когда команд становится много, нельзя каждой команде вручную изобретать:
- CI/CD
- логирование
- метрики
- трейсинг
- секреты
- шаблоны сервисов
- деплой
- security checks
- локальную разработку
- создание окружений
- интеграции
Иначе каждая команда будет тратить силы на инфраструктурную борьбу.
Здесь появляется platform team и Internal Developer Platform. Team Topologies определяет platform team как команду, которая предоставляет внутренний продукт, ускоряющий delivery stream-aligned команд.
На microservices.io Richardson в серии про Microservices Platforms прямо пишет, что платформы важны для Fast Flow и что stream-aligned service teams нуждаются в наборе платформ для разработки микросервисов.
Смысл платформы:
Разработчик не должен каждый раз спрашивать:
- "Как создать сервис?"
- "Как настроить pipeline?"
- "Как подключить логирование?"
- "Как пройти security?"
- "Как задеплоить?"
- "Как получить тестовое окружение?"
Платформа должна давать golden path:
- создал сервис из шаблона
- получил стандартный pipeline
- получил observability
- получил security defaults
- получил стандартный деплой
- получил документацию
Это сильно ускоряет поток.
Но плохая платформа может наоборот замедлить flow, если она превращается в ticket queue.
2. Чем Fast Flow отличается от Flow Framework
Здесь легко запутаться.
Fast Flow — это широкая идея и цель: сделать быстрый, устойчивый поток ценности.
Flow Framework — это более конкретный управленческий/метрический подход, связанный с value stream management. Официальный сайт Flow Framework описывает его как способ измерять поток работы через end-to-end product value streams, находить bottlenecks и связывать delivery с бизнес-результатами.
Flow Framework говорит: давайте измерять разные типы работы:
- Features — новая ценность
- Defects — исправление качества
- Debts — технический долг
- Risks — безопасность, compliance, privacy
И смотреть метрики:
- Flow Time — сколько времени работа идёт через поток
- Flow Velocity — сколько единиц работы завершается
- Flow Efficiency — сколько времени работа реально активна, а сколько ждёт
- Flow Load — сколько работы одновременно в процессе
- Flow Distribution — баланс features / defects / debt / risks
Это полезно для менеджмента, потому что показывает: команда не просто «медленная», а, например, 70% времени тратит на rework, security risk или technical debt.
Но для тебя пока достаточно так:
Fast Flow — цель и мышление.
- Flow Framework — один из способов измерять и управлять flow.
- DORA — другой набор метрик для software delivery performance.
- Team Topologies — способ организовать команды под flow.
- Microservices / modular monolith — архитектурные варианты для flow.
- Platform Engineering — способ убрать инфраструктурное трение.
3. К чему это приведёт
1. Архитектуру будут всё чаще оценивать по изменяемости
Раньше архитектуру часто оценивали так:
- выдержит ли нагрузку?
- надёжна ли?
- безопасна ли?
- дешёвая ли инфраструктура?
Теперь всё чаще добавляется вопрос:
- насколько быстро и безопасно мы можем её менять?
Это приведёт к росту значения:
- bounded contexts
- модульности
- loose coupling
- independent deployability
- contract testing
- observability
- platform engineering
- developer experience
Архитектор будущего — это не только человек, который рисует компоненты. Это человек, который проектирует систему так, чтобы команды могли быстро учиться и менять продукт.
2. Микросервисы перестанут быть самоцелью
Fast Flow делает микросервисы более честными.
Если микросервисы помогают независимым командам быстро и безопасно менять продукт — отлично.
Если они создают хаос, сеть зависимостей, distributed transactions, shared database и адский debugging — они вредят flow.
Поэтому тренд будет такой:
- меньше "давайте распилим всё"
- больше "давайте найдём правильные границы"
Иногда правильный первый шаг — не микросервисы, а хороший modular monolith.
3. Platform Engineering станет обязательной частью серьёзной разработки
Fast Flow почти неизбежно приводит к платформенному мышлению.
Когда у тебя много команд и сервисов, ты не можешь масштабироваться только через инструкции в Confluence. Нужны paved roads / golden paths:
- service templates
- CI/CD templates
- standard observability
- security by default
- self-service environments
- developer portal
- standard deployment model
То есть платформа становится не «внутренней инфраструктурой», а продуктом для разработчиков.
4. Метрики будут смещаться от индивидуальной продуктивности к системному трению
Вместо:
- сколько задач закрыл Вася?
- сколько PR сделал Петя?
- сколько часов списала команда?
будут всё чаще смотреть на:
- lead time
- cycle time
- deployment frequency
- change failure rate
- recovery time
- flow efficiency
- time waiting for review
- time waiting for environment
- time waiting for another team
Это более зрелый взгляд. Он показывает не «кто виноват», а где система тормозит.
5. AI-инструменты усилят важность Fast Flow
Это уже видно в свежих текстах Richardson. Он пишет, что GenAI-инструменты являются усилителем существующих социотехнических возможностей: в slow-flow организации они могут ускорить накопление дефектов, rework и operational risk, а в fast-flow организации могут ускорить устойчивую delivery.
Простыми словами:
Если у тебя плохая архитектура, слабые тесты и ручные релизы,
AI поможет быстрее создавать хаос.
Если у тебя хорошие границы, тесты, pipeline, review и observability,
AI поможет быстрее создавать полезные изменения.
Поэтому Fast Flow станет ещё важнее в эпоху AI-разработки.
4. Главный сдвиг мышления
Обычное мышление:
- Надо больше разработчиков.
- Надо больше задач в спринт.
- Надо быстрее кодить.
- Надо больше контролировать.
- Надо всех загрузить.
Fast Flow мышление:
- Где ценность застревает?
- Почему изменение ждёт?
- Почему команде нужен другой отдел?
- Почему релиз страшный?
- Почему тесты медленные?
- Почему архитектура заставляет менять 5 сервисов?
- Почему команда держит слишком много контекста?
- Почему feedback приходит через месяц?
Это переход от управления людьми к управлению системой.
5. Очень простая формула
Я бы запомнил так:
Fast Flow =
маленькие ценные изменения
+ быстрый feedback
+ автономные команды
+ слабая связанность архитектуры
+ автоматизированный путь в production
+ хорошая developer platform
+ постоянное устранение bottlenecks
И ещё короче:
Fast Flow — это способность организации быстро учиться через безопасные изменения в продукте.
Не просто быстро писать код.
Не просто быстро деплоить.
А быстро превращать идею в проверенную ценность для пользователя.
6. Мини-чеклист: есть ли у команды Fast Flow
1. Может ли команда выпустить маленькое изменение без согласования с 5 другими командами?
2. Может ли команда протестировать свою часть системы автоматически?
3. Может ли команда деплоить независимо?
4. Понятно ли, кто владеет конкретной частью бизнес-домена?
5. Есть ли быстрый feedback после релиза?
6. Видно ли в метриках, где задачи ждут?
7. Большинство изменений маленькие и обратимые?
8. Платформа помогает командам или создаёт очередь заявок?
9. Архитектура помещается в голову команды?
10. Команды оптимизируют ценность для пользователя, а не количество закрытых тикетов?
Если на большинство вопросов ответ «нет», то микросервисы, Kubernetes и AI-агенты сами по себе не спасут.
7. Самое важное для понимания
Fast Flow — это не мода и не отдельная методология. Это зрелый способ смотреть на software engineering как на социотехническую систему.
В этой системе:
- код влияет на команды
- команды влияют на архитектуру
- архитектура влияет на скорость изменений
- процессы влияют на feedback
- платформа влияет на developer experience
- метрики влияют на поведение людей
Поэтому Fast Flow нельзя «купить» одним инструментом.
Его нужно проектировать:
- через архитектуру,
- через границы команд,
- через CI/CD,
- через observability,
- через платформу,
- через маленькие изменения,
- через культуру автономии и ответственности.
Fast Flow — это когда организация устроена так, что полезные изменения проходят от идеи до пользователя быстро, безопасно, маленькими порциями и с быстрой обратной связью.
Именно поэтому Richardson сейчас связывает микросервисы, Team Topologies, DevOps, Platform Engineering и GenAI в одну картину. Микросервисы здесь не цель. Цель — устойчивый поток ценности.