
Я заметил интересную цифру в журнале выполнения агента.
24 решённые задачи подряд.
24 успешные верификации.
Ноль ошибок.
Итоговый success rate — 100%.
На первый взгляд звучит как рекламный лозунг очередной AI-платформы. Но есть нюанс.
За этим результатом не стоит огромная модель на сотни миллиардов параметров. Агент работает локально на qwen2.5-coder:7b, а вычислительные ресурсы ограничены обычным домашним ПК с RTX 5060 и 8 ГБ видеопамяти.
Главное отличие заключается в другом.
Успех обеспечила не модель, а архитектура.
В этой системе языковая модель отвечает только за генерацию решений. Проверка, накопление опыта и ускорение работы реализованы отдельным символическим слоем, который действует детерминированно и не зависит от качества очередного ответа LLM.
Именно поэтому цифра 24/24 интересна не сама по себе, а как показатель того, что архитектурный подход действительно работает.
Что на самом деле означает 24 успешных решения подряд
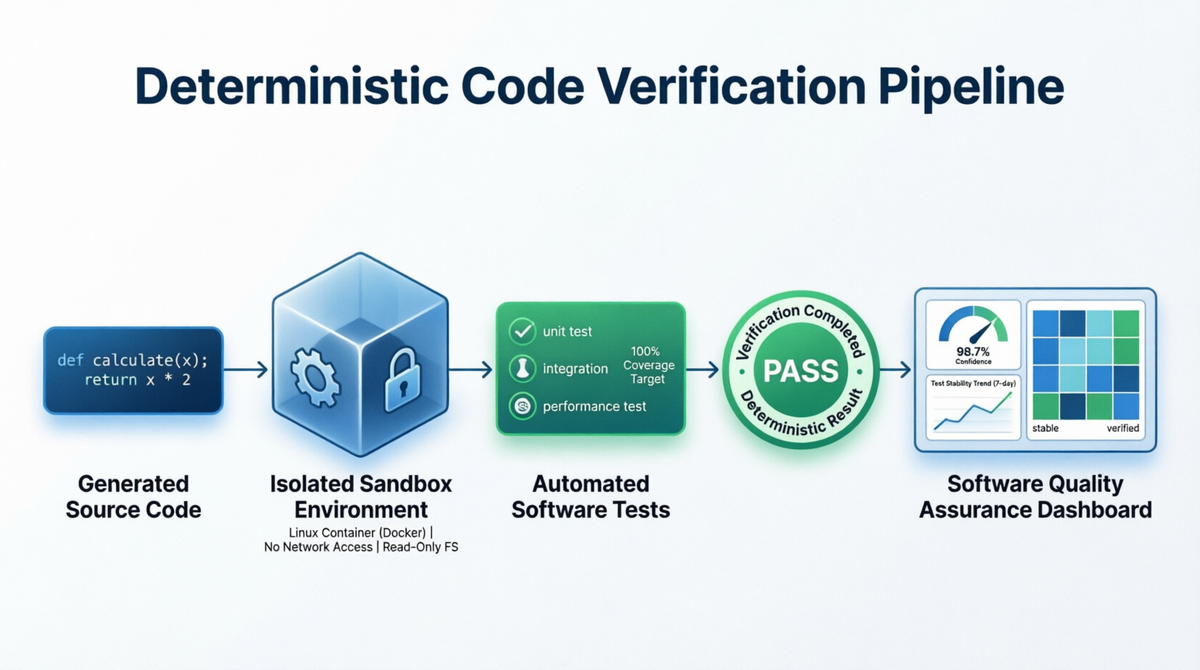
Когда говорят о точности агентных систем, часто возникает вопрос: как именно измерялся успех?
В моём случае критерием является не мнение модели и не субъективная оценка результата.
Каждое решение проходит через ValidatorNano.
После генерации код запускается в изолированной среде и проходит полный набор тестов задачи.
Результат считается успешным только при выполнении двух условий:
- программа завершилась без ошибок;
- вывод полностью совпал с ожидаемым результатом.
Именно тогда решение получает статус test_verified.
Это важно, потому что в системе отсутствует классическая схема проверки через вторую языковую модель.
Никакого cross-validation между двумя LLM.
Никаких дополнительных запросов к внешним сервисам.
Есть только выполнение кода и объективный результат тестов.
Фактически единственным критерием истины становится работающая программа.
Подход напоминает архитектурные принципы Deep Agents SDK, где выполнение потенциально опасных действий изолируется внутри sandbox-среды и не влияет на основную систему.
Почему многие задачи решаются практически мгновенно
Если посмотреть статистику последних запусков, становится заметно, что далеко не каждая задача требует обращения к модели.
Причина проста — Symbolic Cache.
После успешной верификации решение автоматически сохраняется как навык вместе с метаданными:
- идентификатор задачи;
- источник появления;
- уровень сложности;
- дата создания;
- результаты проверки.
Когда аналогичная задача появляется повторно, агент не генерирует код заново.
Он просто находит соответствующий навык и возвращает уже проверенное решение.
Например, задача Roman to Integer была выполнена без единого вызова модели.
От запроса до подтверждения корректности прошло менее 15 миллисекунд.
Для системы это уже не генерация нового решения, а извлечение существующего знания.
Важно отметить, что здесь не используется поиск по эмбеддингам или векторная база данных.
Доступ осуществляется напрямую по problem_id.
Фактически это операция с постоянной сложностью O(1), которая занимает минимальное время независимо от размера накопленной базы навыков.
Где в этой архитектуре находится LLM
Несмотря на акцент на символических механизмах, языковая модель остаётся важной частью системы.
Но её роль существенно ограничена.
Модель qwen2.5-coder:7b запускается только в одном случае — когда нужного решения нет в Symbolic Cache.
Такой сценарий называется cache miss.
Тогда агент получает условие задачи, генерирует код и передаёт результат в ValidatorNano.
Дальше всё решает верификация.
Если тесты успешно пройдены, решение попадает в базу навыков.
Если нет — оно отклоняется независимо от того, насколько убедительным выглядел ответ модели.
Это принципиальное отличие от многих агентных систем, где модель одновременно генерирует, оценивает и проверяет собственные результаты.
Здесь генерация и оценка полностью разделены.
Модель предлагает гипотезу.
ValidatorNano устанавливает факт.
При анализе неудачных попыток используется дополнительная трассировка выполнения. Ошибки группируются по типам, выявляются повторяющиеся паттерны отказов, оценивается качество промптов и инструментов. Такой подход концептуально близок к механизмам анализа траекторий, которые применяются в LangSmith.
Почему 100% success rate — это следствие архитектуры
Когда люди видят показатель 100%, обычно возникает закономерный вопрос:
«Не слишком ли это хорошо, чтобы быть правдой?»
В действительности секрет довольно прост.
Система максимально сокращает количество мест, где может возникнуть неопределённость.
Ложноположительные результаты практически исключены, потому что решение обязано пройти реальные тесты.
Ложноотрицательные результаты минимизируются за счёт того, что при отсутствии навыка агент получает полное условие задачи и необходимый контекст для генерации.
Но самый интересный эффект проявляется со временем.
Каждая успешно решённая задача пополняет Symbolic Cache.
Каждая новая запись уменьшает вероятность повторной генерации.
Каждый цикл делает систему немного быстрее и немного надёжнее.
Получается своеобразный накопительный эффект.
Если традиционная LLM каждый раз начинает решение практически с нуля, то нейро-символьный агент постепенно формирует долговременную базу проверенных знаний.
По мере роста этой базы зависимость от модели начинает снижаться.
Именно поэтому успех определяется не качеством отдельного ответа, а устройством всей системы.
Для объективной оценки подобных архитектур сегодня используются специализированные инструменты бенчмаркинга. Один из наиболее интересных примеров — Harbor framework, который применяется для тестирования агентных систем в большом количестве изолированных контейнерных сред.
Вместо вывода
Когда я увидел в логах показатель 24/24, главным открытием стала не сама цифра.
Гораздо важнее оказалось понимание того, откуда она появилась.
Этот результат обеспечила не очередная более мощная модель.
Не новый промпт.
Не увеличение контекстного окна.
Причина значительно прозаичнее и одновременно интереснее.
Языковая модель занимается только тем, что умеет лучше всего — генерирует варианты решений.
Всё остальное берут на себя символические механизмы:
- ValidatorNano проверяет корректность;
- Symbolic Cache хранит подтверждённые знания;
- система трассировки анализирует ошибки;
- накопленный опыт постепенно повышает надёжность.
Поэтому 100% success rate в данном случае — это свойство архитектуры, а не свойство модели.
И чем больше задач проходит через такую систему, тем заметнее становится это различие.
Используете ли вы детерминированную верификацию в своих агентных системах или всё ещё доверяете проверку второй LLM? Поделитесь своим опытом в комментариях.