В предыдущей статье мы подробно разобрали, как кворум из трех инстансов управляющего центра (Control Plane) страхует платформу от локальных сбоев. Но давайте поднимем градус катастрофы до максимума.
Что произойдет, если в дата-центре случится тотальный блэкаут, и все виртуальные машины управления одновременно выйдут из строя? Или еще хуже — если произойдет авария на сетевом уровне, хосты полностью потеряют связь друг с другом, но продолжат жить автономно, имея доступ к общей системе хранения данных?
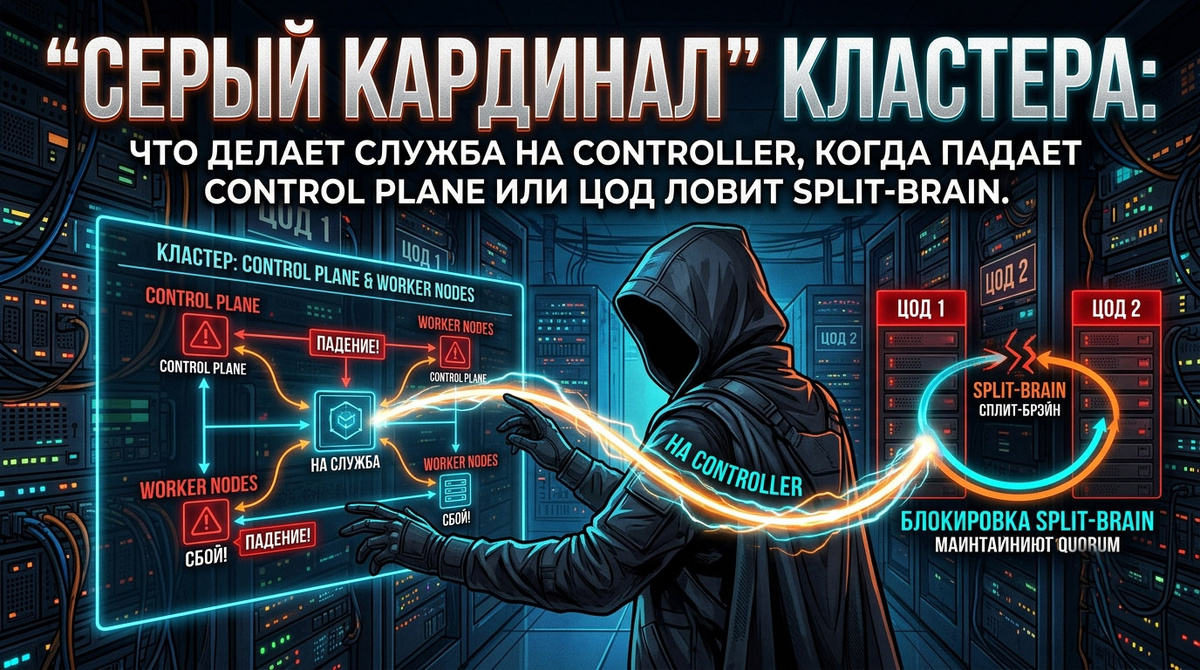
В ИТ-инженерии это называется состоянием «раскола мозга» (Split-Brain). Если в этот момент два изолированных хоста одновременно решат, что сосед умер, и попытаются запустить одну и ту же виртуальную машину с общих дисков, база данных и файловая система будут мгновенно уничтожены параллельной записью.
Для решения подобных критических ситуаций в нашей платформе спроектирован автономный аварийный механизм — служба High Availability Cluster Controller. Сами разработчики уважительно называют её «серым кардиналом» системы. Разберем, как этот сервис спасает инфраструктуру, когда центральное управление полностью ослепло.
Кто такой HA Cluster Controller и где он живет?
Главная архитектурная уязвимость многих классических систем виртуализации заключается в том, что логика их отказоустойчивости завязана на центральный сервер управления (например, vCenter у VMware). Если центральная машина погибает, рядовые хосты гипервизора часто превращаются в «слепых котят» — они продолжают крутить запущенные виртуалки, но не способны скоординировать свои действия при аварии.
Наша служба HA Cluster Controller принципиально отличается тем, что она децентрализована. Это низкоуровневый сервис, который автономно живет на каждом физическом хосте, прямо на уровне гипервизора.
Ей не нужно держать постоянную связь с «вицентром» или интернет-каналами, чтобы знать, что делать. Логика её поведения жестко прописана в локальных конфигурационных файлах, которые дублируются на каждом сервере. Пока жив сам гипервизор хотя бы на одном физическом узле, HA Cluster Controller готов вступить в игру.
Сценарий 1. Тотальное падение Control Plane
Представим худшее: в результате цепочки ошибок или аппаратного сбоя упали абсолютно все инстансы центрального сервера управления. Администратор пытается зайти в админку, но интерфейс недоступен. Инфраструктура осталась без «головы».
В обычной системе это означало бы панику и долгие часы ручного восстановления серверов через консоль. В нашей платформе «серый кардинал» перехватывает инициативу:
1. Автономные службы HA Controller на хостах фиксируют, что центральный орган управления не подает признаков жизни заданное количество времени.
2. Руководствуясь локальными конфигурационными файлами, служба на хосте-лидере берет на себя функции оркестратора.
3. HA Controller автоматически инициирует запуск необходимого количества виртуальных машин центрального сервера из их золотых образов.
4. Как только инстансы управления подняты и восстановили свой кворум, HA Controller незаметно передает бразды правления обратно центральной панели и снова уходит в тень. Для конечных пользователей и критических сервисов этот сбой проходит практически незамеченным.
Сценарий 2. Кошмар по имени Split-Brain
Теперь разберем более коварную аварию — «раскол мозга». Сеть между серверами внутри стойки оборвалась. Хост-01 и Хост-02 больше не видят друг друга. При этом их оптические линки к внешней системе хранения данных (СХД) остались целы — оба сервера прекрасно видят общие диски с виртуальными машинами.
Без строгого арбитража начнется хаос: Хост-02 решит, что Хост-01 сгорел, и попытается поднять у себя его виртуальные машины. Но Хост-01 на самом деле жив и продолжает писать данные на те же LUN-ы в СХД. Результат — гарантированное разрушение данных.
Как эту проблему решает HA Cluster Controller:
· Службы общаются между собой не только по классической менеджмент-сети, но и через специальные микро-метки (heartbeat) прямо на общей системе хранения данных.
· В случае раскола сети HA Controller на каждом хосте мгновенно блокирует возможность бесконтрольного запуска машин.
· Сервис проводит процедуру жесткого взаимного исключения (Fencing). Хост, который потерял кворум и связь с большинством узлов, принудительно изолируется на уровне СХД или уходит в перезагрузку, чтобы гарантированно не повредить диски.
· Выживший сегмент кластера, удерживающий большинство, аккуратно забирает нагрузку и продолжает работу.
Функции аварийного управления: интерфейс лежит, но всё работает
Самое главное: пока недоступен основной орган управления и админка, HA Cluster Controller полностью берет на себя базовые функции жизнеобеспечения кластера.
Если в этот аварийный период упадет какой-то из физических хостов с важной пользовательской виртуалкой, HA Controller на выживших серверах самостоятельно, без участия центрального сервера, примет решение о перезапуске этой машины на здоровом узле.
Он управляет подключениями к дискам, координирует распределение ресурсов и следит за тем, чтобы критические бизнес-процессы компании не остановились ни на секунду, пока сетевые инженеры восстанавливают упавшую инфраструктуру.
Итог
Архитектура, в которой безопасность завязана только на центральную панель управления — это вчерашний день. Наличие «серого кардинала» в виде автономной службы HA Cluster Controller на уровне самого гипервизора превращает кластер в распределенный, интеллектуальный организм. Он способен выжить в условиях полной изоляции, защитить данные от разрушения при Split-Brain и самостоятельно реанимировать систему управления из пепла.
Далее поговорим о деньгах, экономии электричества и математических моделях балансировки. https://dzen.ru/a/aiebelkfs1llk3CO