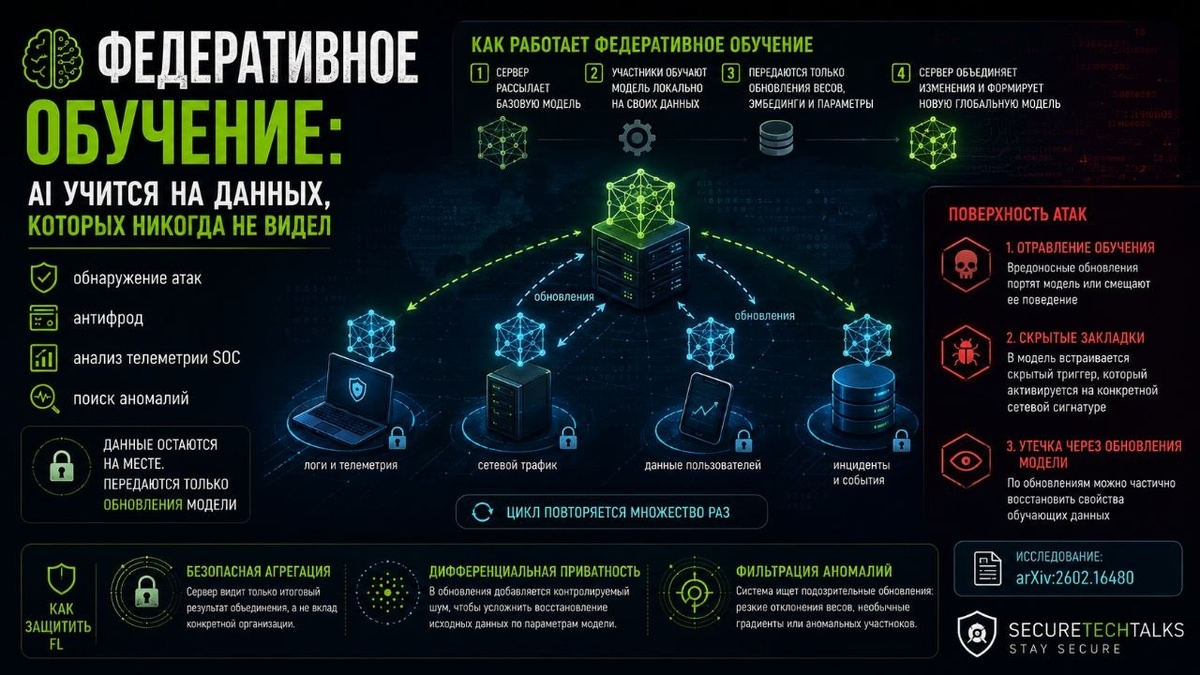
🧠 Федеративное обучение: AI учится на данных, которых никогда не видел
Федеративное обучение всё чаще рассматривают для задач ИБ:
🔹 обнаружение атак
🔹 антифрод
🔹 анализ телеметрии SOC
🔹 поиск аномалий
Компании не готовы делиться сырыми логами, сетевым трафиком и инцидентами. Вместо централизации данных модель обучается распределённо.
⚙️ Как работает федеративное обучение?
Типовая схема выглядит следующим образом:
1⃣ сервер рассылает базовую модель
2⃣ участники обучают её локально на своей телеметрии;
3⃣ наружу уходят только обновления весов, эмбединги и параметры обучения;
4⃣ сервер объединяет изменения (обычно через усреднение данных) и формирует новую глобальную модель.
Цикл повторяется множество раз. Данные инфраструктуру не покидают.
🧨 Поверхность атак
Федеративное обучение создаёт отдельную поверхность атак в виде самого процесса обучения.
1⃣ Отравление обучения
Скомпрометированный участник начинает отправлять вредоносные обновления, чтобы ухудшить обнаружение конкретных угроз или сместить поведение модели.
2⃣ Скрытые закладки
В модель встраивается скрытый триггер. Например, система обнаружения атак начинает пропускать вредоносный трафик только при определённой сетевой сигнатуре.
3⃣ Утечка через обновления модели
Даже без доступа к исходным данным иногда можно частично восстановить свойства обучающих примеров через анализ эмбеддингов.
То есть:
🛡️ Защита подхода FL
Лучшая практика защищать не только модель, но и весь цикл обучения. Обычно используют комбинацию мер:
🔹 Безопасная агрегация Сервер видит только итоговый результат объединения, а не вклад конкретной организации. Это снижает риск утечки через отдельные обновления.
🔹 Дифференциальная приватность
В обновления добавляется контролируемый шум, чтобы усложнить восстановление исходных данных по параметрам модели.
🔹 Фильтрация аномалий Система ищет подозрительные обновления: резкие отклонения весов, необычные градиенты или клиентов, чьё влияние слишком сильно отличается от остальных.
🔗 Исследование: https://arxiv.org/abs/2602.16480
Stay secure and read SecureTechTalks 📚
#кибербезопасность #AI #MachineLearning #FederatedLearning #Privacy #CyberSecurity #SOC #AIsecurity #ThreatDetection #SecureTechTalks