
Проблема
По
мере наполнения Вашей базы знаний в полный рост встает проблема поиска
по всем заметкам и простого поиска по вхождению символов в текст заметок
недостаточно, так как часто помнишь только смысл записанного, а иногда
вообще не помнишь какой материал у тебя есть в базе знаний.
Давайте структурируем описанные проблемы:
- Недостаточная функциональность поиска, в особенности по смыслу.
- Нет четкой уверенности в наличии материала по определенной теме.
В итоге приходим к требованиям к нашей системе:
- Поиск по смыслу, а не только по вхождению символов в текст.
- Выдача ответа на основе найденного материала.
Что у нас должно быть на старте:
- База знаний с obsidian последней версией для управления заметками.
- Сервер с LLM
и видеокартой, так как значительная часть вычислений должна быть на
видеокарте для ускорения процесса выдачи конечного результата. Можно и
без видеокарты, но скорость ответа от сервиса тогда значительно
увеличится. - Навыки программирования: bash, docker, python. Можно делать по аналогии и это только приветствуется.
- OS Linux, так как все что ниже буду описывать применительно к этой операционной системе.
Архитектурно планируем сделать так:
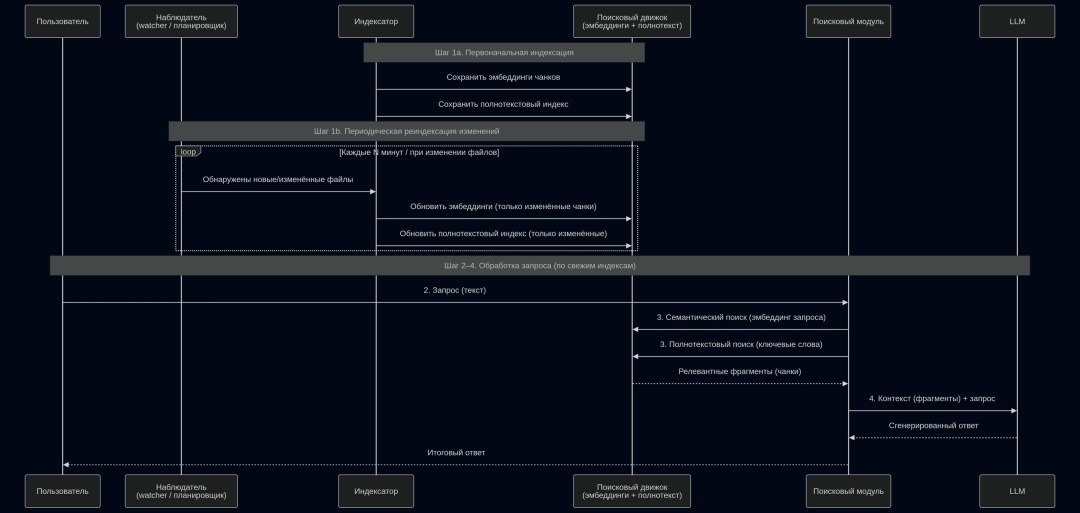
Краткое описание:
- Индексация: система разбивает заметки на небольшие кусочки, превращает каждый в смысловой отпечаток (эмбеддинг) и строит полнотекстовый индекс.
- Фоновое
обновление: специальный наблюдатель периодически проверяет новые и
изменённые файлы и переиндексирует только их, не трогая остальное. - Поиск
под запрос: когда вы задаёте вопрос, поисковый модуль превращает его в
отпечаток, одновременно выполняет семантический поиск (по близости
смыслов) и полнотекстовый поиск (по точным словам), объединяет
результаты и возвращает несколько самых релевантных кусочков - Генерация
ответа: эти кусочки вместе с вопросом передаются локальной LLM с чёткой
инструкцией отвечать строго по предоставленному контексту, и LLM выдаёт
итоговый ответ пользователю.
В этой статье попробуем настроить такую систему.
LLM
Мы хотим, чтобы наша LLM по API
была доступна за пределами нашей сети, а это значит, что нам необходимо
настроить авторизацию по стандартному механизму. В своих домашних
проектах я использую Nginx Proxy Manager, поэтому авторизацию буду настраивать именно там.
- Добавляем новый proxy host в виде http://<ip>:11434.
- В настройках добавляем:
location / {
# Проверяем, что заголовок Authorization совпадает с нашим секретным ключом
if ($http_authorization != "Bearer <api_key>") {
return 401; # Если не совпадает, возвращаем ошибку
}
# Проксируем запрос к Ollama, передавая заголовок дальше
proxy_pass http://<ip>:11434;
proxy_set_header Host $host;
proxy_buffering off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
proxy_connect_timeout 3600;
proxy_send_timeout 3600;
Индексатор и поисковый движок
Настраивать будем obsidian-hybrid-search как основу для индексации наших заметок, поиска и сортировки результата.
# Обновите списки пакетов и установите Node.js и npm
sudo pacman -Syu nodejs npm
# Установка глобально через npm
npm install -g obsidian-hybrid-search
# После установки проверьте, что всё прошло успешно
obsidian-hybrid-search --version
# Обновление
npm install -g obsidian-hybrid-search@latest
Также нам необходимо добавить переменные:
- OPENAI_BASE_URL - адрес нашей локальной LLM.
- OBSIDIAN_IGNORE_PATTERNS - какие пути в obsidian нам игнорировать при индексации.
- OPENAI_API_KEY - ключ авторизации для нашей локальной LLM, который мы задавали выше.
Весь механизм будет работать у нас в терминале, поэтому эти переменные мы должны задать в нашей оболочке. Я использую zsh, поэтому выполняю nano ~/.zshrc:
# Вставляем
export OPENAI_BASE_URL="https://<url>"
export OPENAI_EMBEDDING_MODEL="/<model>"
export OBSIDIAN_IGNORE_PATTERNS=".obsidian/**, *.canvas, templates/**, .trash/**"
export OPENAI_API_KEY="/<api_key>"
Применяем изменения: source ~/.zshrc
Теперь мы можем выполнить (первая индексация может занять значительное время):
cd path_your_vault
obsidian-hybrid-search reindex
В итоге в вашем path_your_vault будет создана SQLite база данных и при необходимости можно посмотреть ее структуру :)
Чтобы не копировать базу по всем клиентам Syncthing
(использую для синхронизации файлов между устройствами) рекомендую
синхронизировать базу с сервером и ПК, а на остальных клиентах сделать
исключение для этой базы.
Для индексации изменений нужно выполнить: obsidian-hybrid-search reindex. Можно выполнять по cron, но я пока делаю "руками".
Для сортировки результата используется bge-reranker-v2-m3, но для этого нужно добавить к поисковому запросу --rerank.
Obsidian
Как
и писал выше взаимодействовать с нашим вопросно-ответным сервисом будем
через терминал и не хочется "прыгать" по окнам: из obsidian в терминал и
обратно. Для этого в obsidian устанавливаем O-Terminal. Все инструкции по установке есть в репозитории, поэтому не дублирую их тут.
В итоге в obsidian у нас есть возможность работать в терминале.
RAG скрипт
В самом начале я пытался написать скрипт на Bash , но он был слишком нагруженным и плохо читался. Решил писать его на Python.
Скрипт:
import argparse
import json
import logging
import os
import re
import subprocess
import time
from pathlib import Path
from typing import List, Tuple
import requests
DEFAULT_VAULT = Path("/<path>/")
DEFAULT_OLLAMA_HOST = "http://<ip>:11434"
DEFAULT_MODEL = "deepseek-r1:8b"
DEFAULT_LIMIT = 5
DEFAULT_SNIPPET_LEN = 2500
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
log = logging.getLogger("rag")
def clean_content(text: str) -> str:
"""
Очищает текст заметки от служебных и мусорных элементов.
Parameters
----------
text : str
Исходный текст заметки (полный или сниппет).
Returns
-------
str
Очищенный текст, пригодный для использования в качестве контекста LLM.
"""
# 1. frontmatter
if text.startswith("---\n"):
text = text.split("---\n", 2)[-1]
# 2. блоки кода
text = re.sub(r"```(?:dataview|text).*?```", "", text, flags=re.DOTALL)
# 3. изображения и пустые ссылки
text = re.sub(r"!\[.*?\]\(.*?\)", "", text) # 
text = re.sub(r"\[\!\[.*?\]\(.*?\)\]\(.*?\)", "", text) # [](url)
text = re.sub(r"\[\s*\]\([^)]+\)", "", text) # [](url)
# 4. markdown-ссылки → только текст
text = re.sub(r"\[([^\]]+)\]\([^)]+\)", r"\1", text)
# 5. строки-теги
text = re.sub(r"(?m)^\s*#[\w/-]+\s*$", "", text)
# 6. секция Links … Description
text = re.sub(r"# Links\s*\n.*?# Description\s*\n", "", text, flags=re.DOTALL)
# 7. HTML-теги
text = re.sub(r"<[^>]+>", "", text)
# 8. заменяем неразрывные пробелы и прочие спецсимволы
text = text.replace("\xa0", " ") # -> пробел
text = re.sub(r"[\x00-\x08\x0B\x0C\x0E-\x1F\x7F]", "", text) # непечатные
# 9. одиночный '!' в конце строки
text = re.sub(r"!\s*$", "", text, flags=re.MULTILINE)
# 10. нормализуем пустые строки (не более двух подряд)
text = re.sub(r"\n\s*\n\s*\n+", "\n\n", text)
return text.strip()
def normalize_ollama_host(url: str) -> str:
"""
Удаляет суффикс '/v1' из URL, если он присутствует.
Используется для преобразования OPENAI_BASE_URL (который может содержать '/v1'
для совместимости с эмбеддингами) в базовый URL для вызова Ollama API
(эндпоинт /api/generate).
Parameters
----------
url : str
Исходный URL, возможно заканчивающийся на '/v1' или '/v1/'.
Returns
-------
str
URL без суффикса '/v1'. Если суффикса нет, возвращает исходную строку.
Examples
--------
>>> normalize_ollama_host("https://ollama.example.com/v1")
'https://ollama.example.com'
>>> normalize_ollama_host("http://localhost:11434/v1/")
'http://localhost:11434'
>>> normalize_ollama_host("http://<ip>:11434")
'http://192.168.0.144:11434'
"""
if url.endswith("/v1"):
return url[:-3]
if url.endswith("/v1/"):
return url[:-4]
return url
def search_and_snippet(query: str, limit: int, vault: Path, snippet_len: int, threshold: float) -> List[Tuple[str, str]]:
"""
Выполняет поиск через obsidian-hybrid-search и возвращает список кортежей (абсолютный_путь, сниппет).
Сниппет уже очищается через clean_content.
"""
cmd = [
"obsidian-hybrid-search", query,
"--mode", "hybrid",
"--limit", str(limit),
"--rerank",
"--threshold", str(threshold),
"--json",
"--snippet-length", str(snippet_len)
]
result = subprocess.run(cmd, cwd=vault, capture_output=True, text=True, timeout=30)
if result.returncode != 0:
raise RuntimeError(f" Ошибка поиска: {result.stderr}")
try:
data = json.loads(result.stdout)
except json.JSONDecodeError as e:
raise RuntimeError(f" Ошибка парсинга JSON: {e}\nВывод: {result.stdout[:500]}")
items = []
for entry in data:
rel_path = entry.get("path")
snippet = entry.get("snippet", "")
if not rel_path or not snippet:
continue
abs_path = str(vault / rel_path)
cleaned = clean_content(snippet)
if cleaned:
items.append((abs_path, cleaned))
return items[:limit]
def build_prompt(query: str, context_items: List[Tuple[str, str]]) -> str:
"""
Собирает промпт из списка (путь, сниппет). Возвращает строку с инструкциями.
"""
sources_list = "\n".join(f"- {path}" for path, _ in context_items)
context_str = ""
for i, (path, cont) in enumerate(context_items, 1):
context_str += f"\n\n--- ИСТОЧНИК {i}: {path} ---\n{cont}"
return f"""Ты — ассистент, который отвечает строго на основе предоставленных источников.
Вопрос пользователя: {query}
Доступные источники (всего {len(context_items)}):
{sources_list}
Правила:
1. Используй ТОЛЬКО информацию из перечисленных источников.
2. Если ответ можно найти в нескольких источниках, синтезируй полный ответ, но не придумывай ничего нового.
3. Если информация противоречива, отметь это и приведи все версии.
4. Если нужных данных нет ни в одном источнике, ответь: «В предоставленных заметках нет информации о {query}».
5. Запрещено использовать теги <think>, <analyse> или любые другие служебные конструкции – отвечай сразу по существу.
6. Пиши на русском языке, чётко и по делу.
7. Используй только текст, без других форм, например: json, mermaid и т.д.
Контекст (источники):
{context_str}
Ответ:"""
def generate_answer(prompt: str, model: str, host: str, api_key: str = "") -> None:
"""
Отправляет промпт в Ollama и выводит ответ в потоковом режиме.
Поддерживает передачу API ключа через заголовок Authorization, если задан.
"""
url = f"{host}/api/generate"
headers = {}
if api_key:
headers["Authorization"] = f"Bearer {api_key}"
payload = {
"model": model,
"prompt": prompt,
"stream": True,
"options": {"num_ctx": 8192}
}
with requests.post(url, json=payload, headers=headers, stream=True, timeout=120) as resp:
if resp.status_code != 200:
raise RuntimeError(f" Ollama ошибка {resp.status_code}")
for line in resp.iter_lines(decode_unicode=True):
if not line:
continue
try:
chunk = json.loads(line)
if "response" in chunk:
print(chunk["response"], end="", flush=True)
except json.JSONDecodeError:
pass
print()
def main() -> None:
# Чтение переменных окружения
openai_base_url = os.getenv("OPENAI_BASE_URL", "")
openai_embedding_model = os.getenv("OPENAI_EMBEDDING_MODEL", "")
openai_api_key = os.getenv("OPENAI_API_KEY", "")
obsidian_ignore = os.getenv("OBSIDIAN_IGNORE_PATTERNS", "")
# Если заданы, передаём их в окружение дочернего процесса явно
if openai_base_url:
os.environ["OPENAI_BASE_URL"] = openai_base_url
log.info(" OPENAI_BASE_URL=%s", openai_base_url)
if openai_embedding_model:
os.environ["OPENAI_EMBEDDING_MODEL"] = openai_embedding_model
log.info(" OPENAI_EMBEDDING_MODEL=%s", openai_embedding_model)
if obsidian_ignore:
os.environ["OBSIDIAN_IGNORE_PATTERNS"] = obsidian_ignore
log.info(" OBSIDIAN_IGNORE_PATTERNS=%s", obsidian_ignore)
if openai_api_key:
log.info(" OPENAI_API_KEY задан (будет передан в заголовке)")
start_total = time.time()
parser = argparse.ArgumentParser()
parser.add_argument("query", nargs="?", default="Что такое Zettelkasten?")
parser.add_argument("--vault", type=Path, default=DEFAULT_VAULT)
parser.add_argument("--model", default=DEFAULT_MODEL)
parser.add_argument("--limit", type=int, default=DEFAULT_LIMIT)
parser.add_argument("--snippet-len", type=int, default=DEFAULT_SNIPPET_LEN,
help="Длина сниппета в символах (по умолчанию 2000)")
parser.add_argument("--threshold", type=float, default=0.6,
help="Порог релевантности для поиска (по умолчанию 0.6)")
args = parser.parse_args()
if openai_base_url:
os.environ["OPENAI_BASE_URL"] = openai_base_url
# Для генерации берём базовый URL без /v1
ollama_host = normalize_ollama_host(openai_base_url)
else:
ollama_host = DEFAULT_OLLAMA_HOST
log.info(" Используется модель: %s (по умолчанию: %s)", args.model, DEFAULT_MODEL)
log.info(" Поиск (гибридный) в %s, порог %.2f", args.vault, args.threshold)
start_step = time.time()
try:
results = search_and_snippet(args.query, args.limit, args.vault, args.snippet_len, args.threshold)
except RuntimeError as e:
log.error(str(e))
return
elapsed = time.time() - start_step
log.info(" Найдено и загружено %d сниппетов (за %.2f сек, всего %.2f сек)",
len(results), elapsed, time.time() - start_total)
if not results:
print(" Ничего не найдено.")
return
# Вывод вопроса и источников
print("\n" + "=" * 60)
print(f" Вопрос: {args.query}")
print("\n Источники (абсолютные пути):")
for path, _ in results:
print(f" • {path}")
print("=" * 60 + "\n")
start_step = time.time()
prompt = build_prompt(args.query, results)
elapsed = time.time() - start_step
log.info(" Промпт (%d символов) построен за %.2f сек (всего %.2f сек)",
len(prompt), elapsed, time.time() - start_total)
start_step = time.time()
generate_answer(prompt, args.model, ollama_host, openai_api_key)
elapsed = time.time() - start_step
total = time.time() - start_total
log.info(" Генерация ответа заняла %.2f сек. Общее время выполнения: %.2f сек", elapsed, total)
if __name__ == "__main__":
import sys
if len(sys.argv) == 1:
sys.argv.append("Что такое LLM?")
main()
Используем скрипт:
~/Документы/vvy_knowledge_base/scripts/ask-vault.py "Что такое LLM или большая языковая модель?" --threshold 0.1 --limit 5
Итог
В итоге у нас есть удобный поиск по нашей базе знаний, мы можем взаимодействовать с ним, и мы можем его расширять.
По
мере написания статьи нашел как возможно получить больший функционал,
но для этого необходимо время :) Описал, что сейчас использую и оно мне
очень сильно помогает.
Ссылки:
- Как запустить свою базу знаний?
- Как запустить локально LLM?
- Как запустить прокси-сервер для сервисов?
- Как установить драйвера NVIDIA в Linux?