Всем привет, сегодня мы будем выполнять такую задачу: У нас есть 2D матрица, заполненная числами.
Нам нужно написать код, который будет искать в двумерном массиве определённое число. Но мы сегодня будем не просто реализовывать такой алгоритм, а постараемся сделать его максимально быстрым и оптимизированным, насколько сможем.
Мы же любим соревноваться с другими разработчиками на LeetCode? 😁. Верно?
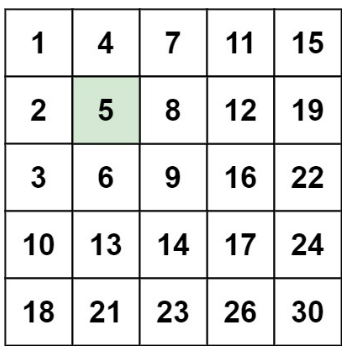
Есть ещё одна интересная деталь. Элементы в машей матрице находятся не просто в случайном порядке. В каждой строке элементы располагаются по возрастанию, слева направо. И в каждом столбце элементы располагаются по возрастанию сверху вниз.
Заметьте. Они не просто рассортированы по возрастанию. Они именно по строкам и столбцам отдельно.
То есть новая строка начинается не с какой-нибудь 16, а с 2. Надеюсь, вы поняли принцип.
Эта информация поможет нам реализовать быстрый поиск по массиву. Давайте начинать.
Приступаем к решению задачи
Для начала не будем делать никаких сложных конструкций, а сделаем самый обыкновенный поиск по массиву. Если есть элемент, выведем true, если нет, false.
А вот так. Начнём с простого и узнаем, что же будет.
Мои прогнозы: на каком-нибудь 50-ом или 100-ом кейсе от LeetCode нам попадётся очень большой пример, который мы не сможем решить из за оптимизации.
Он решил эту задачу за 57 мс. Это очень странно, а что же будет на более больших примерах?
Обычно наши стартовые кейсы решаются за 0-4 мс. Это приблизительно, могу ошибаться.
Проверим код на большой выборке
Всё верно. Наш код остановился на 126-ом кейсе из за недостатка оптимизации. Здесь время выполнения кода ограничено. Давайте ка это исправим.
Приступаем к оптимизации
Я предлагаю такой способ: мы будем проходиться по строке, перебирать элементы и сравнивать их с искомым значением ("target"). Если же вдруг окажется, что наш элемент больше "target", код перенесётся на следующую строку вниз.
Я думаю, что в будущем мы можем столкнуться ещё с какими-то обстоятельствами, из за которых нам придётся дополнять и оптимизировать наш механизм.
Да нет, я уже прямо сейчас это вижу. Нам не обязательно перескакивать в начало следующей строчки, мы можем перепрыгнуть прямо под семёрку, и начать проверку оттуда. Это же один столбец, а в столбце, по условию задачи, числа расположены по возрастанию.
Если число больше, чем "target", просто "break" ставим. (Реализовываем механизм с позапредыдущей картинки, не предыдущей, это где просто переходим в начало новой строки)
Теперь стартовые кейсы выполняются за 52 миллисекунды.
Но по оптимизации наш код по-прежнему не проходит.
Возвращаемся к нашей схемке, и вместо "break" переносим "y" цикла на +1. А потом меняем x на -1.
В таком случае мы не просто переносимся на следующую строку, а переносимся прямо в низ
А если наш y будет равен n, это будет означать, что мы вышли за границы массива, и цикл надо прервать.
Но если мы просто y увеличим на 1, мы перенесёмся не на предыдущую ячейку, которая нам нужна, а вообще на две ячейки вперёд. Во-первых, мы перемещаемся строго вниз, во-вторых, во время новой итерации цикла, мы переместимся дальше, и только после этого будет проверка.
Поэтому нам надо уменьшить x на 2.
Я решил, если мы много взаимодействуем с X и Y вручную, может быть заменить цикл "for" на цикл "while" для удобства?
Но у нас может возникнуть вот такая ситуация
Нам нужна проверка на выход за границу массива.
У нас механизм такой. Из X вычитается -2, чтобы на следующей итерации -2 превратилась в -1.
Нам нужно проверить, будет ли эта позиция "-2 + 1" находиться за пределами массива.
Если такое происходит, получается, не существует правильного решения. Подумайте сами, справа по строке нужного значения нет, а мы находимся в самом первом элементе. Ниже значения тоже больше, и там не будет нужного значения. Получается, при таком условии нам надо просто завершить цикл.
По нашему новому механизму код застревает на 117-ом кейсе
Если визуализировать, наш код выполняет такие действия.
Я выделил красным квадратом проблемный участок. Здесь он, если опираться на здравый смысл, должен был бы переместиться назад, но он перемещается вниз, а потом влево.
Из за этого он пропускает места, где мог бы скрываться "target" (21).
А если изменить этот способ? Если сделать не так, чтобы он сначала опускался, а потом смещался влево, а сделать так, чтобы он сначала смещался влево, а потом спускался? И спускался, в зависимости от того, попал ли он в элемент, меньше чем "target", иначе двигался бы вообще вправо.
Спускаться он будет, только если новое число меньше "target".
Теперь мы будем не прибавлять y каждый раз, когда число больше "target", мы наоборот, будем идти назад по x.
И да, так как мы теперь в цикле while, мы можем переписать наш код. Мы можем прибавлять x в зависимости от условий, то есть не каждую итерацию цикла. В этом условии мы можем просто вычесть один из x.
Только в двух условиях у нас будет меняться x. В предыдущем условии мы x уменьшали, а в следующем условии "else", то есть "matrix[y][x] < target" будем увеличивать x.
Также добавим проверку, не вышел ли наш y за границу массива. Просто проверка на выход из границы массива есть только у цикла с "y", а он проверяет это, только когда закончатся все итерации с "x" по строке.
Выглядеть это будет так.
В целом, код такой, пока что
Мы также в цикле ещё. Но хорошо, что наш новый механизм заработал.
В этом месте мы можем поменять порядок действий. Ситуация, когда наша ячейка равна "target" встречается очень редко, только один раз. Но код постоянно проверяет ячейку на равенство, а потом на знак больше или меньше.
На первом месте должны стоять действия, которые проводятся чаще всего. А чаще всего наша ячейка оказывается меньше target.
Проверка на равенство вообще должны быть в "else", то есть не больше, не меньше.
Если наш x находится возле левой границы, бессмысленно тратить время на вычитание, а потом сравнивание, меньше ли x, чем 0. Можно сразу проверить, равен ли x просто нулю, а потом вычесть из него 1.
Понимаю, очень слабое влияние будет. Но всё же, будет.
Как сказал мне один опытный человек, "это экономия на спичках". 😃
Наши тестовые примеры выполняются за 50 миллисекунд. Запомним это, потом будем сравнивать.
Я попробовал вывести все ячейки по которым мы проходимся в консоль, и понял одну важную вещь. Когда наша строка заканчивается, мы переходим на новую строку и начинаем сначала. Только, когда число больше, чем "target" мы спускаемся вниз. Нужно сделать такой же спуск вниз, но в конце строки.
И таким образом мы пройдёмся по 15 клеткам, а не по 21. И это ещё в маленькой таблице. Я думаю, в крупной таблице разница будет существенная.
Для ситуаций, когда ячейка больше "target" и так существует механизм спуска. Сделаем то же самое, но и для условия, когда ячейка меньше "target". Но для этого условия сделаем ещё условие, такой спуск будет работать только в самом конце строки.
И да, с 50 мс наш код разогнался до 48 мс.
Наша новая конструкция сломалась на 123 кейсе, перед тем, как двигаться назад, нужно было сделать такую же проверку, что если наш элемент единственный в строке?
Да!! Мы справились!! Но плохо 😃.
Хотя мы обошли 15.83% разработчиков, решивших эту задачу. Давайте посчитаем, для интереса.
Решали задачу 2.4 миллиона разработчиков, из них 1.4 миллиона решили эту задачу. Из этого 1.4 миллиона мы обошли 15.83%, то есть 221 тысячу разработчиков. А 221 тысяча решивших + 1 миллион проваливших это 1.2 миллиона разработчиков. А 1.2 от 2.4 это 50%. Мы обошли 50% разработчиков, бравшихся за эту задачу.
А никаких ни 15.83%. Будьте на позитиве 😄.
У меня есть идея. А давайте сломаем программу и посмотрим один из примеров, чтобы на них понять, что делает наша программа?
Таблица размером 10 на 8. (Я переписываю данные из массива в LibreOffice Calc, ну или аналог Microsoft Excel).
Для удобства, красными линиями я пометил моменты, где ячейка меньше "target", синим, где больше.
Пока я смотрел код, по нему строил эту картинку, я заметил в коде одну любопытную деталь. Проверки на y у нас происходят постоянно. А должны только после того, как этот Y реально меняется
Правда это действие не значительно ускорило наш код...
Я заметил, что забыл убрать "console.log()",
И это разогнало наш код до 488 мс, было 571 мс. Вот вам и консоль логи.
Я заметил ещё одну деталь. Почему, когда мы возвращаемся в ту же клетку, мы должны снова получать значение оттуда? Мы же там уже были и знаем, что она меньше "target".
Если кто не знал, получать значения из двумерных массивов тоже относительно затратная задача.
На более низком уровне, приближенном к компьютеру, нужно узнать, сколько занимают элементы массива в памяти (int - 2 байта), сколько занимает памяти массив в массиве (строка в таблице, она в этом примере - 10 байт), узнать, на каком месте в памяти наша строка с нужным элементом (10 байт * 3 = 30 байт), а потом по позиции элемента в массиве массива узнать, где он сам находится в памяти (36 позиция по байтам, если рассматривать пример).
А в JavaScript у нас не простые прямоугольные массивы с int-ами. В JavaScript массивы могут быть разной длины, с элементами разного типа (float может весить 4 байта, а какая-нибудь "строка" 6 байт), и всё это надо рассчитывать. Каждая строка будет иметь разный размер в памяти. Лучше лишний раз не обращаться в память за элементом двумерного массива, лучше просто запомнить, что он меньше "target".
Сделаем новую переменную. Она будет true, если наша предыдущая ячейка меньше "target".
Если ячейка будет меньше "target", если она не на конце, где нужно сделать спуск, тогда переменная будет "true", в других случаях "false".
Эту переменную нужно вставлять в те места, где происходит движение назад.
Теперь выполняется за 525 мс, что очень странно. Должно же быть быстрее.
Я отключил этот способ, стало 489 мс.
Я понял. Таких ситуаций, когда мы дважды вернулись в одну ячейку, не так много, а постоянные добавления лишней переменной и сравнивание с ней только тормозит наш код. Похоже, таких моментов не так много. Вот если бы таких моментов было подавляющее большинство, такой способ мог бы нам пригодиться. Придётся этот способ отменить.
Я понял ещё кое что. Мы можем сделать эти движения в конце в виде прямой линии. Нет смысла наворачивать такие зигзаги.
Вот так должно быть:
Мы можем сделать по-другому. Убрать условие "m != 1" и вообще убрать уменьшение x на 1, если ячейка меньше "target". Я понял, что смысла в этом нет.
И получится, что наш код будет просто спускаться по Y вниз.
Мы продвинулись ещё дальше, и у нас 401 миллисекунда.
Давайте попробуем посмотреть ещё один пример (специально сломал код ещё раз).
Так, этот пример не подходит, слишком маленький. Смотрим другие.
Здесь тоже придраться не к чему. Сразу спуститься нельзя к 14, способ сломается тогда.
Здесь тоже всё очень хорошо выглядит.
Я придумал. Мы можем один раз рассчитать "num" и использовать его в других местах, так будет чуть быстрее.
Не понял, а почему повторяются условия? Не доглядел...
Я тут подумал. Если нашему коду каждый раз приходится двигаться к концу таблицы, чтобы потом по ней идти назад, почему бы возле правой границы и не сделать начальную точку?
Ой, ой, ой, ой, разогнался то как!!! 😉 Мы смогли залезть на этот столбик.
Посмотрим, сможем ли мы упасть с него в другом направлении 😉.
Я понял ещё кое что. Смотрите, раньше у нас было два цикла, по Y и по X.
Раньше это нужно было, чтобы перебирать все элементы по Y и X. А теперь у нас есть проверки внутри самого цикла. Теперь наш код не выходит за границу строки, а плавно по этой границе спускается. Можно убрать эти два цикла, убрать лишние проверки, убрать в конце цикла "y++" и сделать просто цикл "while(true)", который завершаться будет только через "return".
Хорошо, мы перескочили на другой столбик, и наш код выполняет все кейсы уже за 265 мс. А может это не все кейсы, может это некоторое среднее число выполнения кейсов. Наш маленький стартовый кейс выполняется за 63 мс. Возможно это действительно какое-то среднее время.
Подведём итоги
Очень хорошо, мы справились с поставленной задачей и смогли её решить достойно. Наш код работает, справляется со своими функциями, и по своей оптимизации достойно держится наравне с трудами других разработчиков.
Давайте посчитаем. Задачу решали 2.4 миллиона разработчиков, из них решили 1.4 миллиона, а не решил 1 миллион. 48.09% это 673 тысячи.
1 миллион + 673 тысячи = 1 673 000 разработчиков, 69.7%. Это очень хороший результат, мы сделали код лучше, чем почти 70% разработчиков.
Давайте посмотрим примеры нашего кода, как он справляется с нашими задачами, если это визуализировать
Это очень хорошо. Хочу вас предупредить, писал эту статью я около 6 часов, не меньше, уж точно. Возможно и больше. Более 6 часов я занимался написанием статьи, обдумыванием задачи, написанием кода и рисованием множество разных схем. Также я редактировал текст и рисовал превью для этой статьи, делал я это всё без использования ИИ.
Я надеюсь вы оцените мой труд хотя бы лайком. Сидеть над статьями по нескольку часов, проделывать такую работу, и при этом умудриться за относительно короткий срок написать 40 статей для блога, это надо постараться.