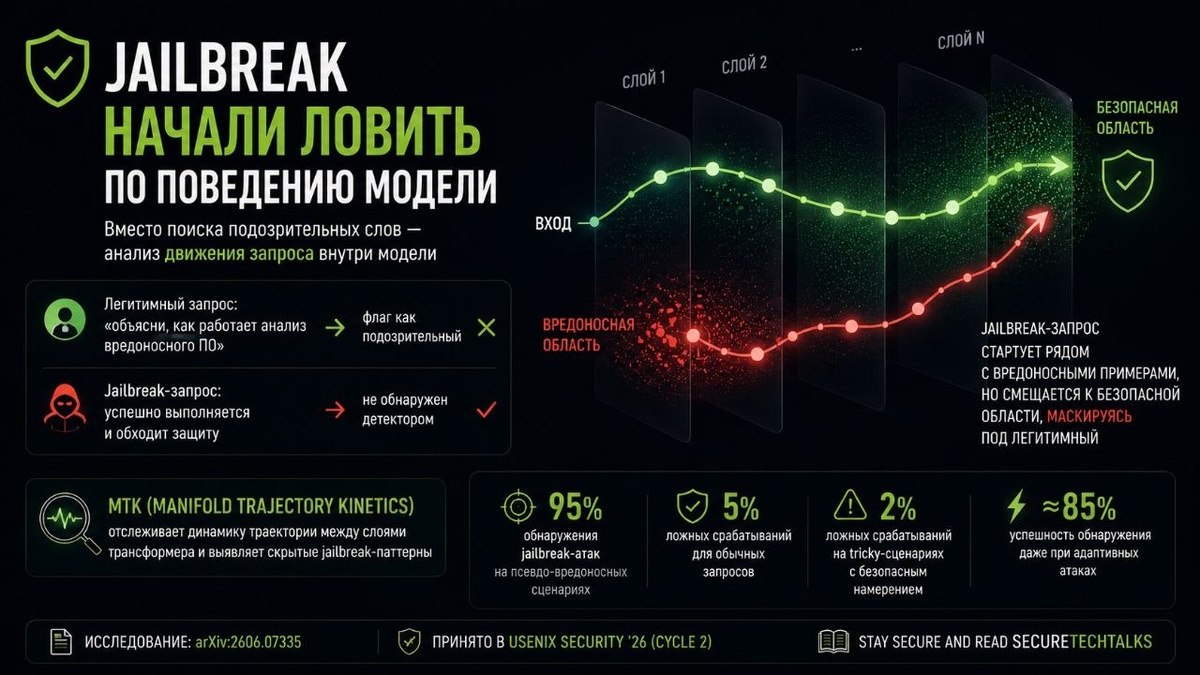
🛡️ Jailbreak начали ловить по поведению модели
Большинство защит LLM работают довольно прямолинейно:
🔹 анализируют prompt
🔹 ищут подозрительные шаблоны
🔹 смотрят на внутренние представления модели
🔹 пытаются вычислить «опасное» пространство признаков
Однако вполне легитимный запрос вроде: «объясни, как работает анализ вредоносного ПО» фиксируется, как подозрительный просто из-за словаря, а реально вредоносный промпт успешно выполняется.
⚙️ Анализ движения внутри модели
В новой работе Manifold Trajectory Kinetics (MTK) исследователи предлагают сформироваться на том, как запрос эволюционирует внутри модели.
Технически MTK отслеживает динамику траектории между слоями трансформера. Нормальный запрос обычно остаётся рядом с другими безопасными примерами на протяжении всех вычислений модели.
А вот jailbreak-запрос часто стартует рядом с вредоносными примерами, но затем начинает «маскироваться» и постепенно смещается ближе к безопасной области, пытаясь обмануть систему защиты.
🧪 Цифры
На псевдо-вредоносных сценариях система показала:
🔹 95% обнаружения jailbreak-атак
🔹 5% ложных срабатываний для обычных запросов
🔹 всего 2% ложных срабатываний на tricky-сценариях с безопасным намерением
Также MTK неплохо переживает адаптивные атаки. Когда атакующий специально оптимизирует jailbreak под обход детектора, успешность обнаружения всё ещё держится около 85%.
Для защиты от jailbreak это очень сильный результат.
🧠 Похоже, защита от jailbreak постепенно эволюционирует из фильтрации ключевых слов в полноценную телеметрию поведения LLM во время рассуждений.
🔗 Исследование: https://arxiv.org/abs/2606.07335
Stay secure and read SecureTechTalks 📚
#кибербезопасность #AI #LLM #Jailbreak #PromptInjection #AIsecurity #CyberSecurity #USENIX #AdversarialAI #SecureTechTalks