
Последние новости в мире ИИ-агентов: математический отбор трейсов вместо галлюцинаций. Инженеры перестали выбрасывать неудачные траектории — их сохраняют, анализируют и превращают в учебные данные. Разбираем, как работают Negative skills, cross-validation на двух моделях и TF-IDF с распадом опыта.
Блок 1. Факты и контекст
Negative skills — это не маркетинг. Это практика сохранения неудачных решений агента для последующего анализа паттернов ошибок. В отличие от классического RL, где награда только за успех, здесь каждая ошибка становится точкой роста.
Cross-validation в контексте ИИ-агентов — проверка одного решения двумя независимыми моделями. Например, qwen2.5-coder и llama3.1 (локальные модели для слабых ПК) получают один и тот же запрос. Если ответы расходятся — запускается механизм пересчёта.
Блок 2. Технологии (модели / фреймворки)
Реализации из реального пайплайна (на основе предоставленного контекста):
- Negative skills
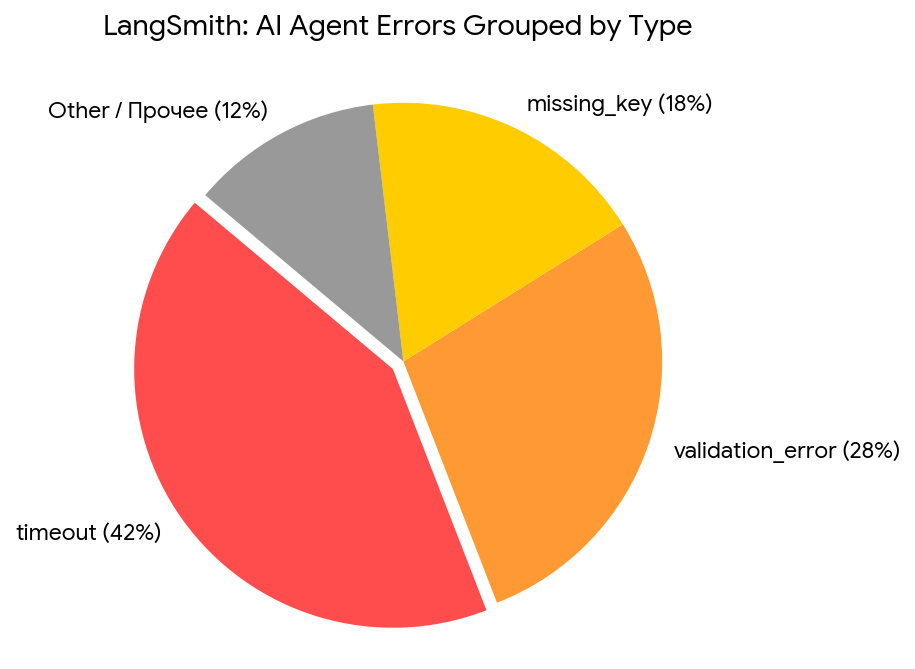
Агент не удаляет фейлы, а складывает в отдельное хранилище с меткой типа ошибки (timeout, validation error, missing key). Периодически запускается задача: сгруппировать ошибки по категориям, предложить исправления в промптах или инструментах. - Cross-validation на двух LLM
Пара (qwen2.5-coder, llama3.1) запускается на одной подзадаче. Если результаты не совпадают — вызывается третья модель-арбитр или запрос к человеку (human-in-the-loop). - Математический отбор трейсов = TF-IDF × Decay
Каждый шаг агента векторизуется (TF-IDF по ключевым токенам). Успешные траектории получают высокий вес, неудачные — низкий. Со временем вес старых трейсов уменьшается (Decay). Консолидация опыта: периодически выбираются трейсы с максимальным произведением TF-IDF на текущий коэффициент использования.
Блок 3. Анализ / Сравнение
Вывод: нет единого рецепта. Для простых чат-ботов хватит success‑трейсов. Для агентов, работающих с файлами, API и длинными документами, Negative skills и кросс‑валидация на двух моделях — необходимый минимум.
Блок 4. Пример использования
LangGraph Swarm + GPU‑песочница
Возьмём open‑source проект LangGraph Swarm (реализация роевого интеллекта). Агенты выполняют задачи в GPU‑песочнице: обработка больших документов, классификация, кластеризация, построение графиков.
Как задействованы Negative skills:
- Воркер получает задание «построить матрицу путаницы и boxplot».
- Если упал (например, не найден seaborn), фиксирует ошибку в специальный трейс с полем status: "failed", error: "ModuleNotFoundError: seaborn".
3. Центральный координатор раз в N итераций запускает анализ всех failed трейсов.
4. Находит повторяющиеся паттерны: «в 70% случаев ошибка — отсутствие seaborn, в 20% — невалидный путь к данным».
5. Автоматически корректирует системный промпт: добавляет команду import seaborn as sns и проверку наличия файла.
Роль cross-validation на двух LLM:
При генерации кода для визуализации одновременно вызываются qwen2.5-coder и llama3.1. Если они выдают разные скрипты — включается human‑in‑the‑loop: пользователь выбирает правильный, и оба варианта сохраняются в трейсы. В следующий раз агент отдаёт предпочтение паттерну, который прошёл проверку.
Математический отбор трейсов (TF‑IDF × Decay):
- Все успешные и неудачные трейсы превращаются в TF‑IDF векторы.
- Коэффициент использования трейса = TF‑IDF × exp(-λ × время_с_последнего_использования).
- При консолидации опыта оставляются только трейсы с коэффициентом выше порога (например, 0.3). Остальные удаляются.
Это позволяет агенту не запоминать устаревшие решения и не переобучаться на редких исключениях.
Вопрос: как мы можем быть в курсе этих технологий? Какие шаги вы предпринимаете, чтобы улучшить обучение ИИ-агентов на своих багах?
Сохраняете ли вы неудачные трейсы? Используете ли пару моделей для перекрёстной проверки? Внедряете ли TF‑IDF с распадом?
Дайте знать в комментариях. Обсудим реальные пайплайны, без маркетинговых галлюцинаций.