***
…Намедни для очередной статьи понадобилось мне в интерактивном интерпретаторе Python набрать следующий код:
for line in open(r'C:\\Users\\Master\\Desktop\\тошиба.txt').readlines():
print(line.upper(), end='')
Этот код открывает файл тошиба.txt, читает его содержимое построчно, переводит все символы в каждой строке в верхний регистр и выводит их на экран, сохраняя исходную структуру документа.
• Цикл for вызывает файловый метод readlines() для загрузки содержимого файла в память в виде списка строк (он последовательно перебирает элементы списка, полученного от .readlines()).
• На каждой итерации переменная line будет содержать одну строку текста из файла.
• line.upper(): Метод .upper() применяется к строке line. Он создаёт новую строку, в которой все строчные буквы заменены на прописные (заглавные). Исходная строка line не изменяется.
• print(...): Функция выводит результат на экран.
• end='': По умолчанию функция print() добавляет в конец вывода символ новой строки (\n). Поскольку каждая строка из файла уже содержит свой собственный символ \n, вызов print() без этого параметра привёл бы к появлению пустых строк между строками текста (двойной перенос). Параметр end='' говорит функции print() ничего не добавлять в конец, тем самым сохраняя оригинальное форматирование файла.
***
Хотя текстовый файл изначально был сохранён в кодировке utf-8, интерактивный интерпретатор Python, обрабатывая программный код, вывел "кракозябры":
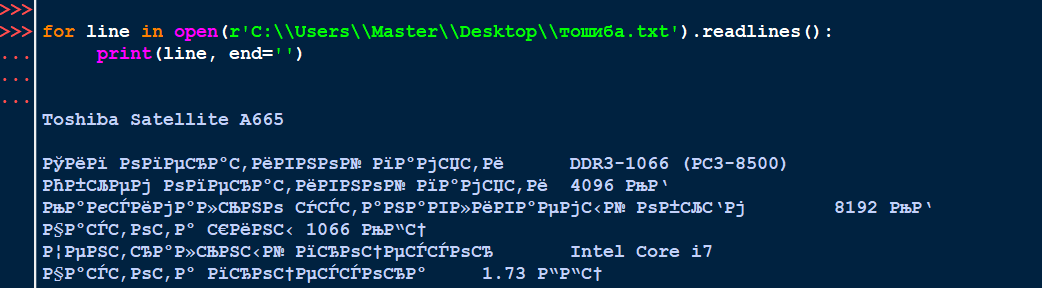
При этом редактор кода PyScripter отображал содержимое файла корректно:
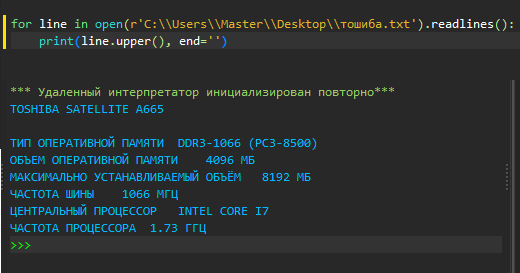
Если в текстовом файле есть великий и могучий кириллица (в названии файла или в его содержимом), в интерактивном интерпретаторе Python могут возникать ошибки с корректным отображением текста (так называемые "кракозябры").
Для надёжной работы с кириллицей лучше всегда указывать кодировку явно – в параметре encoding='utf-8':
for line in open(r'C:\\Users\\Master\\Desktop\\тошиба.txt', encoding='utf-8').readlines():
print(line.upper(), end='')
***
Следует отметить, что метод readlines() фактически загружает в память сразу весь файл, поэтому не является оптимальным (особенно для файлов большого размера!).
Наилучший способ чтения текстового файла строка за строкой – поручить циклу for автоматически вызывать метод __next__() для перехода к следующей строке на каждой итерации:
for line in open(r'C:\\Users\\Master\\Desktop\\тошиба.txt', encoding='utf-8'):
print(line.upper(), end='')
Такой способ построчного чтения текстовых файлов является наилучшим по 3-м причинам:
1) он самый простой в плане написания кода,
2) он самый быстрый для выполнения,
3) он меньше расходует память (ведь файл загружается построчно, а не сразу целиком!).
***
Примечание
Встроенный текстовый dzen-редактор не позволяет сохранять отступы в публикуемом программном коде (отсутствие этих отступов в Python приведёт к ошибке!).