🧨 Prompt injection наконец-то начали измерять как нормальную уязвимость
На arXiv вышла работа, где исследователи решили собрать benchmark для атак на AI-агентов и системно проверить, что реально помогает против prompt injection.
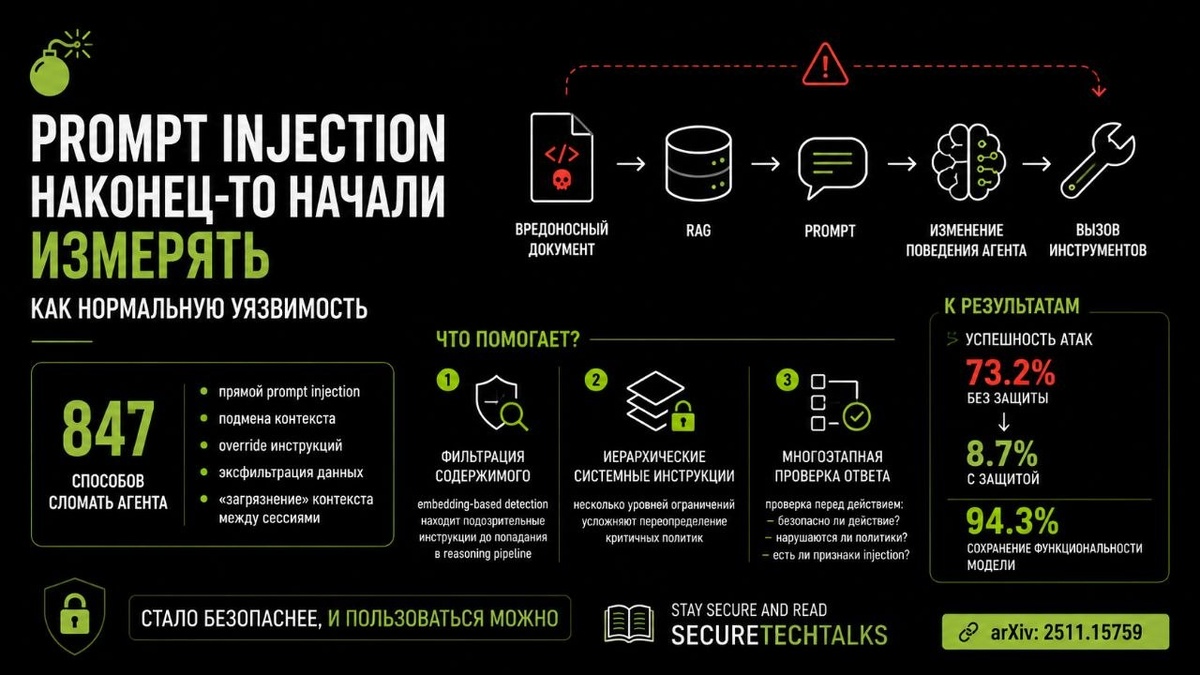
⚙️ 847 способов сломать агента
Авторы собрали 847 adversarial test cases для RAG-агентов и разбили атаки на несколько категорий:
🔹 прямой prompt injection
🔹 подмена контекста
🔹 override инструкций
🔹 эксфильтрация данных
🔹 «загрязнение» контекста между сессиями
Далее все прогоняли через реалистичные сценарии, например: вредоносный документ → попадание в RAG → извлечение в prompt → изменение поведения агента → вызов инструментов.
🧠 Что же помогает?
Исследователи протестировали несколько уровней защиты сразу:
1⃣ Фильтрация содержимого
Система анализирует входной контент и пытается обнаружить аномалии через embedding-based detection, чтобы замечать подозрительные инструкции ещё до попадания в reasoning pipeline.
2⃣ Иерархические системные инструкции
Вместо одного system prompt используются несколько уровней ограничений, где критичные политики сложнее переопределить.
3⃣ Многоэтапная проверка ответа
Перед выполнением действия агент проходит дополнительную verification stage:
➖безопасно ли действие?
➖нарушаются ли политики?
➖нет ли признаков injection?
📉 К результатам
Без защиты успешность атак доходила до 73.2%. Комбинация нескольких механизмов снизила показатель до 8.7%, при этом сохранив 94.3% исходной функциональности модели.
Большинство защит AI обычно работают по принципу «стало безопаснее, но пользоваться невозможно.». Тут все иначе, что не может не радовать.
🔗 Исследование: https://arxiv.org/abs/2511.15759
Stay secure and read SecureTechTalks 📚
#кибербезопасность #AI #LLM #PromptInjection #AgenticAI #RAG #AIsecurity #CyberSecurity #AppSec #SecureTechTalks