Это мультимодальная модель: текст, картинки, аудио, а в документации семейства Gemma 4 отдельно описан и видеовход. Google упаковывает длинный контекст и мультимодальность в локальный формат на 12B параметров.
Заявка: модель можно запускать на ноутбуках с 16 ГБ RAM или unified memory. Важная поправка: это зависит от квантизации и рантайма. В BF16 память будет заметно выше, поэтому 16 ГБ — это consumer-local сценарий, а не тяжёлый полный режим.
Контекстное окно — 256K токенов. Для открытой модели такого размера это уже интересная зона: длинные документы, кодовые базы, скриншоты, аудио и рабочий контекст можно держать ближе к локальной машине, без постоянного похода в облако.
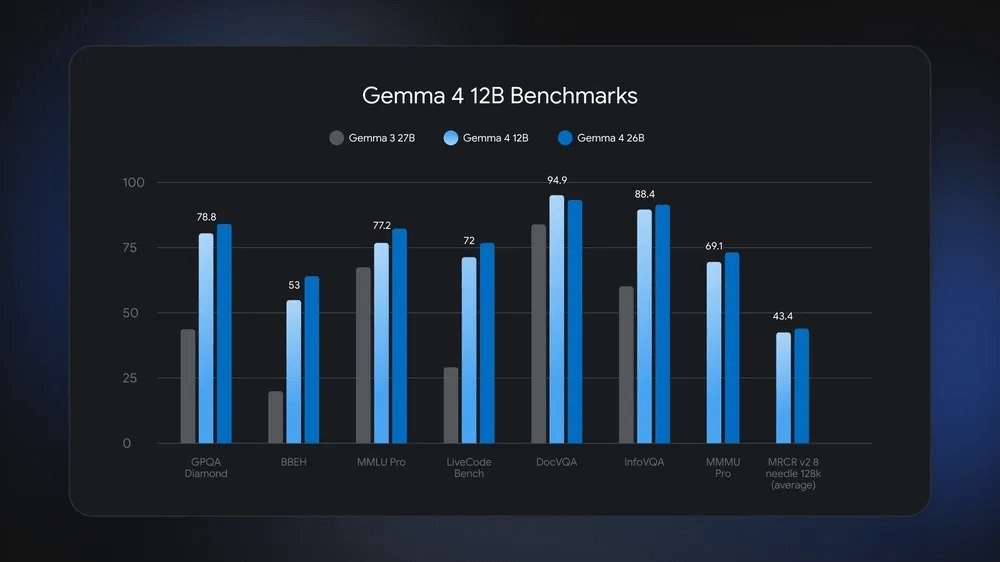
На бенчмарке Gemma 4 12B выглядит близко к Gemma 4 26B в ряде тестов и заметно сильнее Gemma 3 27B. Из подписанных цифр: GPQA Diamond 78.8, MMLU Pro 77.2, LiveCode Bench 72, DocVQA 94.9, InfoVQA 88.4.
Если это нормально заведётся в LM Studio / Ollama / MLX-подобных сборках, мультимодальная локальная модель перестанет быть игрушкой для энтузиастов с огромной видеокартой. Она становится обычным кандидатом для ноутбука.
Источник: Google AI docs
Инструменты и кейсы: @human20
Внедрение: human20.app