Когда агент ходит 5 шагов с tool calling, каждый шаг — отдельный LLM-вызов, а конечный ответ кажется «странным» — стандартные логи Python вам не помогут. Нужно видеть полное дерево trace: какой system prompt, какие tool calls, что вернули функции, какой final answer, сколько всего токенов и за сколько секунд. Без этого даже банальная оптимизация стоимости невозможна. Через единый шлюз Promptra (Claude Opus 4.7 — 350/1790 ₽, GPT-5.5 — 350/2150 ₽, DeepSeek V4 Pro — 30/60 ₽) integration с observability стеками идёт через стандартный OpenAI SDK, что упрощает плагинирование любого инструмента.
Этот обзор — три ключевых tool'а: Langfuse (open-source trace + evaluations), Helicone (SaaS cost tracking + rate limiting), OpenTelemetry GenAI (стандарт для self-hosted APM). Интеграционный код на Python, метрики которые реально нужны, схема trace на сложном агентском pipeline, сравнение self-hosted vs SaaS под русский B2B. оплата в рублях по договору, полный пакет закрывающих документов.
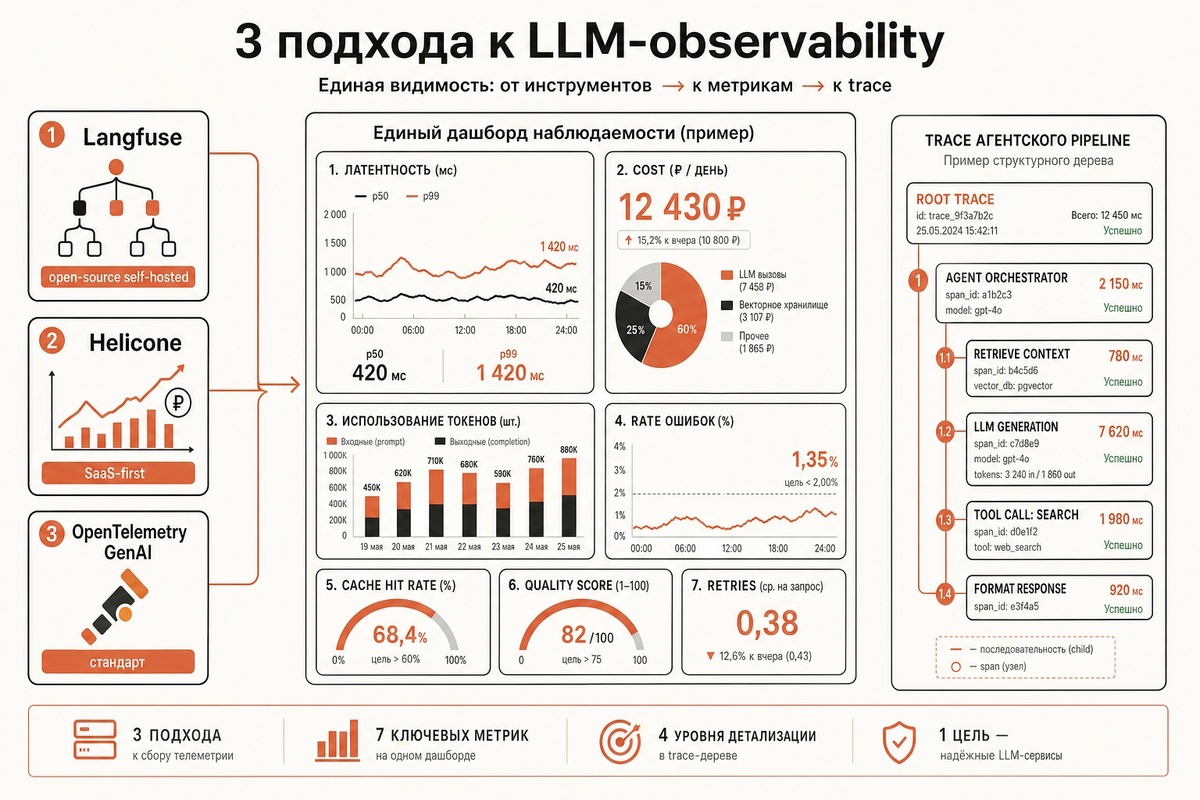
TL;DR — observability стек за 30 минут
- Langfuse self-hosted (Docker + Postgres) — главный backend для trace и evaluations.
- OpenAI SDK + langfuse-decorator — каждый вызов автоматически логируется с prompt, response, usage, latency.
- Дашборд: latency p50/p99, cost ₽/день, token usage по моделям, error rate, cache hit rate.
- Алерты: error rate > 5%, p99 latency > 30 сек, cost spike > 200% от baseline.
- Evaluations 5% sample через LLM-as-judge: DeepSeek V4 Pro оценивает GPT-5.5 на 0–10. Эта статья — production-расширение нашего pillar-гида полный технический гид по LLM API на Python: токены, function calling, streaming, RAG, async/batch.
Базовая интеграция — 20 строк кода. Полноценный стек с дашбордами — день работы.
Что измеряем: 7 обязательных метрик
Без этих метрик вы не управляете LLM-приложением:
- #: 1 • Метрика: Total latency • Зачем: UX и SLA • Норма: p50 < 3с, p99 < 15с (без reasoning)
- #: 2 • Метрика: TTFT (для streaming) • Зачем: Воспринимаемая скорость • Норма: < 800 мс
- #: 3 • Метрика: Cost per request, ₽/день • Зачем: Бюджет • Норма: watch для spike'ов > 2× baseline
- #: 4 • Метрика: Token usage input/output по моделям • Зачем: Оптимизация • Норма: output > input в 2× → возможна экономия
- #: 5 • Метрика: Error rate по типам • Зачем: Стабильность • Норма: < 1% для retry-обходимых, < 0.1% для остальных
- #: 6 • Метрика: Cache hit rate • Зачем: ROI кэша • Норма: > 25% для FAQ, иначе кэш не помогает
- #: 7 • Метрика: Quality score (eval) • Зачем: Не деградирует ли • Норма: стабильно ± 5% от baseline
Quality — самый важный и самый забываемый. Без него вы можете «сэкономить» переключив на дешёвую модель и тихо просесть в LSAT-score без понимания.

Langfuse: open-source trace + evaluations
Langfuse — самый популярный open-source инструмент для LLM observability (~16K звёзд GitHub). Фокус — trace-уровень: одно дерево показывает полный pipeline агента, от входного user-запроса через все tool calls до финального ответа. Документация — langfuse.com/docs.
Установка self-hosted:
# docker-compose.yml
version: "3.5"
services:
langfuse-server:
image: langfuse/langfuse:2
ports:
- "3000:3000"
environment:
- DATABASE_URL=postgresql://postgres:postgres@db:5432/postgres
- NEXTAUTH_SECRET=<32-byte-random>
- SALT=<32-byte-random>
- NEXTAUTH_URL=https://langfuse.your-domain.ru
depends_on:
- db
db:
image: postgres:16
environment:
- POSTGRES_PASSWORD=postgres
volumes:
- db-data:/var/lib/postgresql/data
volumes:
db-data:
docker compose up -d — UI доступен на :3000. Создаёте организацию, project, получаете API ключи.
Интеграция в Python код через декоратор:
from langfuse.openai import openai # drop-in replacement
import os
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://langfuse.your-domain.ru"
client = openai.OpenAI(
api_key="sk-promptra-...",
base_url="https://api.promptra.ru/v1",
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "..."}],
# Метаданные для группировки в UI
metadata={"user_id": "user-42", "session_id": "sess-abc", "tags": ["faq"]},
)
# Langfuse автоматически логирует prompt, response, usage, latency, cost
Drop-in замена import openai на from langfuse.openai import openai — все вызовы автоматически трассируются. Без изменений в бизнес-логике.
Для агентов с несколькими шагами нужен явный trace:
from langfuse.decorators import observe, langfuse_context
@observe
def agent_pipeline(user_query: str):
langfuse_context.update_current_trace(
user_id="user-42",
session_id="sess-abc",
tags=["agent", "v2"],
)
# Шаг 1: классификация интента
intent = classify_intent(user_query)
# Шаг 2: поиск в RAG
docs = retrieve_docs(user_query)
# Шаг 3: финальный ответ
return generate_answer(user_query, intent, docs)
@observe(as_type="generation")
def classify_intent(query: str):
return client.chat.completions.create(
model="gpt-5-4", # 170/1070 ₽
messages=[{"role": "user", "content": f"Классифицируй интент: {query}"}],
)
# Каждый вложенный @observe становится child span в trace
В Langfuse UI вы увидите дерево: agent_pipeline (корень) → 3 child span'а с детальным prompt/response каждого, total latency, cost и token usage по каждому. Для дебага сложных pipeline это бесценно.
Подробнее про агентов с tool calling — Function calling и tool use.
Helicone: SaaS cost tracking и rate limiting
Helicone — SaaS-first observability с фокусом на cost и rate limiting. Self-hosted доступен, но основной сценарий — облако. Документация — helicone.ai/docs.
Интеграция — одна строка изменения в base_url:
from openai import OpenAI
client = OpenAI(
api_key="sk-promptra-...",
base_url="https://oai.helicone.ai/v1", # Helicone proxy перед Promptra
default_headers={
"Helicone-Auth": "Bearer sk-helicone-...",
"Helicone-Target-URL": "https://api.promptra.ru/v1", # backend = Promptra
"Helicone-Property-User-Id": "user-42",
"Helicone-Property-Session-Id": "sess-abc",
},
)
Helicone становится прокси перед Promptra — каждый запрос автоматически логируется в дашборд. В UI: cost по моделям, latency-перцентили, rate limiting per user/session/api key, prompt management.
Плюсы Helicone:
- Минимум кода (одна строка proxy).
- Готовые дашборды без настройки.
- Rate limiting per user из коробки (полезно для multi-tenant приложений).
- Custom properties для group by (по пользователю, тенанту, фиче).
Минусы:
- Данные идут через US-сервера (есть EU-регион, но проверяйте 152-ФЗ).
- Меньше функций trace/evaluations чем у Langfuse.
- Self-hosted сложнее, чем Langfuse.
Для русского B2B с строгими требованиями к локализации данных Helicone проигрывает self-hosted Langfuse. Для быстрого MVP без своей инфры — отличный выбор.
OpenTelemetry GenAI: стандарт для self-hosted APM
OpenTelemetry GenAI Semantic Conventions — утверждённый в 2025 стандарт для трейсинга LLM-вызовов. Атрибуты span'а:
gen_ai.system = "openai"
gen_ai.request.model = "claude-opus-4-7"
gen_ai.request.max_tokens = 2000
gen_ai.request.temperature = 0.7
gen_ai.response.id = "chatcmpl-..."
gen_ai.response.model = "claude-opus-4-7"
gen_ai.response.finish_reasons = ["stop"]
gen_ai.usage.input_tokens = 1240
gen_ai.usage.output_tokens = 587
gen_ai.operation.name = "chat"
Это значит — данные едины в любом backend (Jaeger, Tempo, Honeycomb, Grafana Cloud). Не зависят от вендора. Если у вас уже есть OpenTelemetry-стек для микросервисов — LLM-трейсы естественно туда встают.
Интеграция через opentelemetry-instrumentation-openai-v2:
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor
# Setup
provider = TracerProvider
processor = BatchSpanProcessor(OTLPSpanExporter(endpoint="https://otel-collector:4317"))
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
# Auto-instrument OpenAI SDK
OpenAIInstrumentor.instrument
# Все вызовы client.chat.completions.create теперь автоматически создают span
# с GenAI-атрибутами
После этого span'ы идут в ваш OTEL collector → Tempo/Jaeger/Honeycomb. На дашборде Grafana — стандартные latency/error/cost дашборды на TraceQL. Подробнее про OpenTelemetry GenAI — официальная спецификация.
Для русского self-hosted стека: Promptra → собственный OTEL collector → Grafana Tempo на Yandex Cloud. Данные не покидают РФ, форматы стандартные. См. B2B-чеклист 12 вопросов поставщику LLM API — раздел про observability и compliance.
Сравнение трёх подходов
Что выбрать под вашу задачу:
- Критерий: Open-source • Langfuse: Да • Helicone: Частично • OpenTelemetry: Да
- Критерий: Self-hosted • Langfuse: Просто (Docker compose) • Helicone: Сложно • OpenTelemetry: Просто (если уже есть OTEL)
- Критерий: SaaS Cloud • Langfuse: Да ($59/mo Team) • Helicone: Да ($25/mo Pro) • OpenTelemetry: Нет (используйте Grafana Cloud / Honeycomb)
- Критерий: Trace tree • Langfuse: Отличный • Helicone: Базовый • OpenTelemetry: Через Tempo/Jaeger
- Критерий: Evaluations • Langfuse: Встроены • Helicone: Базовые • OpenTelemetry: Нужно строить самому
- Критерий: Cost tracking • Langfuse: Да • Helicone: Главная фича • OpenTelemetry: Через свои метрики
- Критерий: Rate limiting • Langfuse: Нет • Helicone: Да (per user) • OpenTelemetry: Нет
- Критерий: Prompt management • Langfuse: Да • Helicone: Да • OpenTelemetry: Нет
- Критерий: 152-ФЗ compliance • Langfuse: Self-hosted в РФ • Helicone: EU/US regions • OpenTelemetry: Self-hosted в РФ
- Критерий: Цена 1M events/мес • Langfuse: 2-5K ₽ (self-host) или $59 • Helicone: $100 • OpenTelemetry: 1-3K ₽ (Yandex+Tempo)
Рекомендация для русского B2B:
- MVP / прототип: Helicone Cloud (одна строка кода, готовый дашборд).
- Production с requirement 152-ФЗ: Langfuse self-hosted на Yandex Cloud.
- Уже есть OpenTelemetry: добавьте OpenAIInstrumentor и интегрируйте в существующий стек.
Логи: что писать в каждый вызов
Минимальный набор полей для production-логов LLM:
import structlog
import time
logger = structlog.get_logger
async def llm_call_with_logging(messages, model, **kwargs):
start = time.monotonic
request_id = kwargs.pop("request_id", str(uuid.uuid4))
user_id = kwargs.pop("user_id", None)
log_ctx = {
"request_id": request_id,
"user_id": user_id,
"model": model,
"input_messages_count": len(messages),
"input_chars": sum(len(m["content"]) for m in messages),
}
try:
response = await client.chat.completions.create(model=model, messages=messages, **kwargs)
duration = time.monotonic - start
# ВАЖНО: не логируйте полный prompt/response в plain logs (sensitive data)
# Логируйте hash и метаданные. Полные данные — в Langfuse/Helicone с access control
logger.info(
"llm.success",
**log_ctx,
duration_ms=int(duration * 1000),
input_tokens=response.usage.prompt_tokens,
output_tokens=response.usage.completion_tokens,
finish_reason=response.choices[0].finish_reason,
cost_rub=calculate_cost(model, response.usage),
prompt_hash=hashlib.sha256(str(messages).encode).hexdigest[:16],
)
return response
except Exception as e:
duration = time.monotonic - start
logger.error(
"llm.error",
**log_ctx,
duration_ms=int(duration * 1000),
error_type=type(e).__name__,
error_msg=str(e)[:500],
)
raise
Критично:
- request_id и user_id — для join'а логов между сервисами.
- prompt_hash вместо полного prompt — приватность пользователя + меньше объём логов.
- token usage отдельными полями — для агрегации в дашбордах.
- cost_rub — рассчитываем сразу для удобства аналитики.
- error_type отдельно — для group by по типам.
Полные prompt/response — в Langfuse/Helicone с access control. В обычных логах — только метаданные.
Quality evaluation: LLM-as-judge
Качество — самая сложная метрика. Три подхода:
1. Pattern matching — regex на JSON schema, длину, ключевые слова. Дёшево, узко.
def eval_json_format(response: str) -> float:
try:
json.loads(response)
return 1.0
except json.JSONDecodeError:
return 0.0
2. LLM-as-judge — вторая модель оценивает первую по rubric'у. Универсально, дороже.
JUDGE_PROMPT = """Оцени ответ ассистента по шкале 0-10 по критериям:
- Точность (фактическая корректность)
- Полнота (покрыт ли вопрос полностью)
- Релевантность (соответствует ли вопросу)
Вопрос: {query}
Ответ: {answer}
Выведи только число от 0 до 10, без объяснений."""
def llm_judge(query: str, answer: str) -> float:
response = client.chat.completions.create(
model="deepseek-v4-pro", # 30/60 ₽ — дёшево для judge
messages=[{"role": "user", "content": JUDGE_PROMPT.format(query=query, answer=answer)}],
max_tokens=10,
temperature=0,
)
try:
return float(response.choices[0].message.content.strip)
except ValueError:
return -1.0 # parse error
Judge на DeepSeek V4 Pro — 30/60 ₽ за 1М токенов, в 12 раз дешевле Opus. Можно гонять на 100% трафика без больших расходов.
3. Embedding similarity — cosine между ответом и gold reference. Подходит когда есть эталонный ответ.
def eval_similarity(answer: str, gold: str) -> float:
a = embed(answer)
g = embed(gold)
return cosine_similarity(a, g)
В production комбинируйте: pattern matching на 100%, LLM-judge на 5% sample, embedding similarity на A/B-тестах при смене модели. Подробнее про embeddings — Embeddings и векторный поиск.
Алерты: что должно будить дежурного
Минимальный набор алертов для production:
- Алерт: Error rate spike • Условие: error_rate > 5% за 5 мин • Severity: P1
- Алерт: p99 latency spike • Условие: p99 > 30 сек за 10 мин • Severity: P2
- Алерт: Cost spike • Условие: daily_cost > 200% от 7-day avg • Severity: P1
- Алерт: Quality drop • Условие: judge_score 7-day avg < 90% от baseline • Severity: P2
- Алерт: Cache hit rate drop • Условие: hit_rate < 70% от baseline • Severity: P3
- Алерт: Provider 429 rate • Условие: 429_rate > 10% за 5 мин • Severity: P2
- Алерт: Circuit breaker open • Условие: breaker_state=open > 30 сек • Severity: P1
- Алерт: DLQ size • Условие: dlq_size > 0 • Severity: P3 (но требует разбора)
Каналы: P1 → телефон дежурного, P2 → Slack + Telegram, P3 → email. Cost spike обычно означает баг (бесконечный цикл, забытый retry) или DDoS — стоит лимита снизу.
Подробнее про retry-policy и circuit breaker, которые подкармливают эти метрики — Rate limiting и retry стратегии для LLM API. Про webhook async pipeline и DLQ — Webhook'и и async events с LLM в production.
Production-чеклист observability
- [ ] Хотя бы один tool: Langfuse self-hosted ИЛИ Helicone ИЛИ OpenTelemetry. Без observability вы слепы.
- [ ] 7 основных метрик трекаются: latency, cost, tokens, errors, cache hit, quality, retries.
- [ ] Каждый запрос имеет request_id и user_id для join'а логов.
- [ ] Полный prompt/response — в observability tool с access control, не в plain logs.
- [ ] structlog для JSON-логов + ELK/Loki/Datadog как backend.
- [ ] Cost calculation per call — рассчитан и записан сразу, не считается потом.
- [ ] Quality eval хотя бы pattern matching 100% + LLM-judge 5% sample.
- [ ] Алерты P1: error rate, cost spike, circuit breaker open.
- [ ] Алерты P2: p99 latency, quality drop, provider 429 rate.
- [ ] Дашборд с per-model breakdown: видно, какая модель дорожит, какая медленная.
- [ ] Дашборд с per-user/tenant breakdown: видно abuse и top spenders.
- [ ] Sampling для дорогих метрик (eval, embedding similarity) — не 100%, а 1–10%.
- [ ] Retention policy: trace 30 дней, агрегаты 1 год, raw logs 90 дней.
- [ ] Доступ к prompt/response — only PII-cleared engineers (compliance).
Через Promptra OpenAI-совместимый формат позволяет подключать любой observability-tool без изменения бизнес-логики. См. Миграция с OpenAI на Promptra за 10 минут — observability стек сохраняется без изменений после миграции.
Антипаттерны
- Логировать полный prompt в plain logs — GDPR/152-ФЗ violation, утечка PII.
- Считать cost вручную потом — теряете данные о деноминированных моделях и проч.
- Не отслеживать quality — сэкономили на модели, тихо просели в качестве.
- Алерты без severity — все одинаково «orange», дежурный игнорирует всё.
- Observability как-афтер-thought — добавляете когда уже горит, спецификации потеряны.
- Только cost tracking без latency и quality — оптимизируете один из трёх параметров, ломаете другие.
- 100% sampling на дорогие метрики — eval бюджет съедает реальный.
FAQ
Зачем специализированная LLM-observability — недостаточно Sentry?
Sentry ловит исключения, не показывает: какой prompt отправили, сколько токенов потратили, latency каждого шага агента. LLM-стек — cost per request, token usage, quality, cache hit, trace tool calls. Без них оптимизация невозможна.
Langfuse или Helicone?
Langfuse — open-source, self-hosted, trace + evaluations. Подходит для сложных pipeline и compliance с 152-ФЗ. Helicone — SaaS-first, cost tracking + rate limiting, проще для базового мониторинга. Для русского B2B — Langfuse self-hosted.
Что такое OpenTelemetry GenAI?
Стандарт OTEL для LLM-трейсинга (утв. 2025). Атрибуты: gen_ai.system, gen_ai.request.model, gen_ai.usage.input_tokens. Данные едины в любом backend (Tempo, Jaeger). Интегрируется с существующим OTEL-стеком.
Какие метрики критичны?
Семь: latency (total + TTFT), cost ₽/день, token usage, error rate по типам, cache hit rate, quality score, retry/fallback rate. Без quality остальные не дают полной картины.
Как оценивать качество автоматически?
Pattern matching на 100% (regex/JSON schema), LLM-as-judge на 5% sample (DeepSeek V4 Pro — 30/60 ₽), embedding similarity для A/B-тестов. Комбинация всех трёх — стандарт.
Стоимость self-hosted vs SaaS?
Langfuse self-hosted: 1500-2500 ₽/мес на Yandex Cloud. Helicone Cloud Pro $25/мес (1.8K ₽) до 100K req. Langfuse Cloud Team $59/мес (4K ₽). Для русского B2B с 152-ФЗ self-hosted выгоднее.
Promptra — российский LLM API-агрегатор
Один OpenAI-совместимый endpoint ко всем флагманам: OpenAI (GPT-5.5, GPT-5.4), Anthropic (Claude Opus 4.7, Sonnet 4.6), Google (Gemini 3.1 Pro, 3.5 Flash), DeepSeek V4 Pro, Qwen 3.6 Plus.
Цены 1-в-1 с провайдером по курсу ЦБ — без наценки на токены. Оплата в рублях по договору, полный пакет закрывающих документов. Без VPN — легальный B2B-сервис в России.
Если статья была полезной — попробуйте Promptra: главная страница · каталог моделей · документация