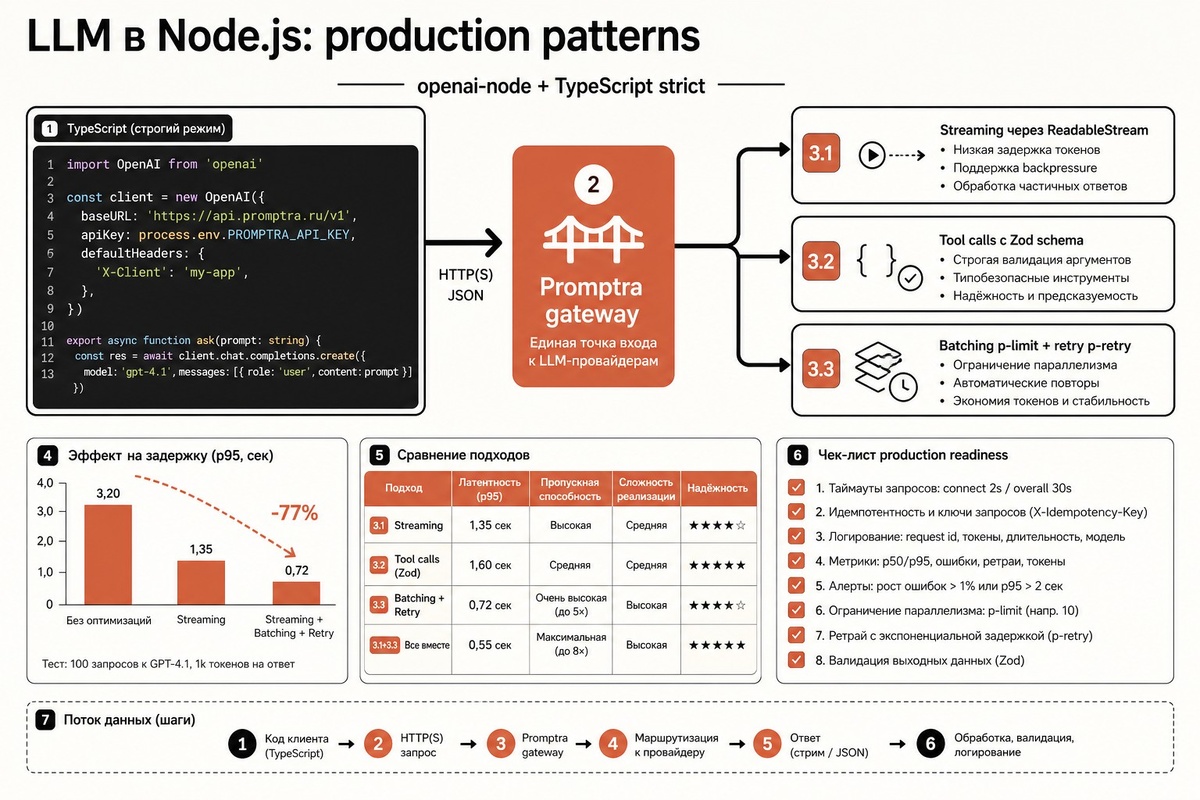
Node.js и TypeScript — стандарт для serverless-LLM приложений: Vercel Edge Functions, Cloudflare Workers, Next.js API routes, NestJS-бэкенды. Преимущества — типизация (compile-time контроль), serverless-friendly runtime, простой streaming через ReadableStream Web API. Но без правильных паттернов вы быстро упираетесь в any-типы, socket-лимиты, потерю tool calls и нестабильный streaming. Через единый шлюз Promptra (Claude Opus 4.7 — 350/1790 ₽, GPT-5.5 — 350/2150 ₽, Gemini 3.1 Pro — 140/860 ₽, DeepSeek V4 Pro — 30/60 ₽) base_url: 'https://api.promptra.ru/v1' подключает openai-node SDK к любому из провайдеров без переписывания кода.
Этот гайд — рабочие production-паттерны для TypeScript: строгая типизация через SDK + Zod, streaming через async iterator и ReadableStream, типизированные tool calls с runtime-валидацией, batching через p-limit, error handling через типизированные SDK-классы, готовые примеры для Edge Functions и Node-backend. оплата в рублях по договору, полный пакет закрывающих документов.
TL;DR — production setup
npm install openai zod p-limit
# Опционально
npm install @anthropic-ai/sdk zod-to-json-schema p-retry
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY,
baseURL: "https://api.promptra.ru/v1",
maxRetries: 3,
timeout: 120_000, // 120 сек для reasoning
});
Одна зависимость — все модели. Дальше типизация и production-паттерны.
Установка и типизированный клиент
Полная типизация из коробки — SDK экспортирует все типы:
import OpenAI from "openai";
import type {
ChatCompletion,
ChatCompletionChunk,
ChatCompletionMessageParam,
ChatCompletionTool,
} from "openai/resources/chat/completions";
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1",
maxRetries: 0, // ретраи делаем сами через p-retry
timeout: 120_000,
});
async function chat(messages: ChatCompletionMessageParam[]): Promise<string> {
const response: ChatCompletion = await client.chat.completions.create({
model: "claude-opus-4-7",
messages,
max_tokens: 2000,
});
return response.choices[0].message.content ?? "";
}
Типы ChatCompletionMessageParam, ChatCompletionTool, ChatCompletionChunk идут из самого SDK — не пишите свои. Документация — openai-node на GitHub и platform.openai.com/docs.
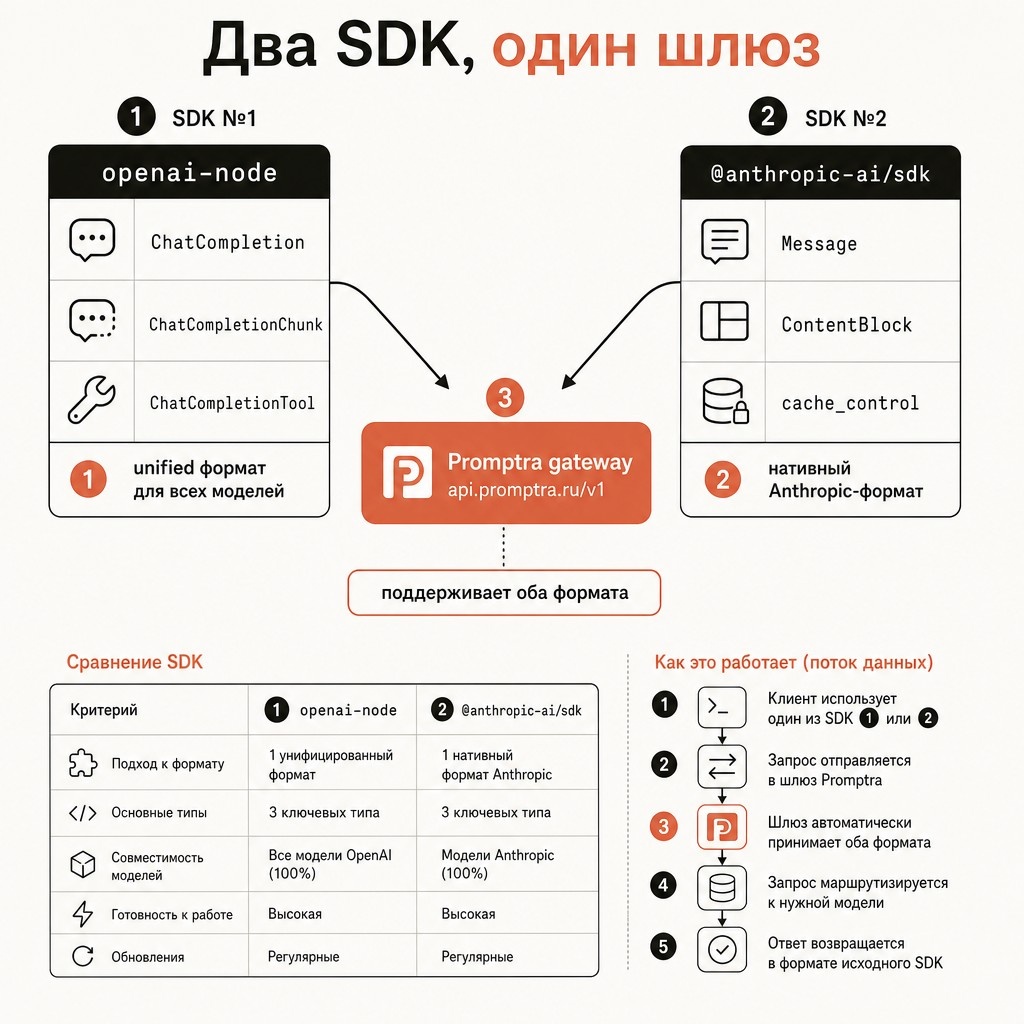
Для нативного Anthropic-формата (с системой cache_control и тонкими настройками Claude) используйте @anthropic-ai/sdk:
import Anthropic from "@anthropic-ai/sdk";
const anthropic = new Anthropic({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1", // Promptra поддерживает оба формата
});
const message = await anthropic.messages.create({
model: "claude-opus-4-7",
max_tokens: 2000,
messages: [{ role: "user", content: "..." }],
});
Promptra принимает запросы и в OpenAI, и в Anthropic-формате — выбирайте под привычки команды. Подробнее про миграцию с прямого OpenAI/Anthropic — Миграция с OpenAI на Promptra за 10 минут.
Streaming: async iterator и ReadableStream
В Node.js streaming — основной паттерн для chat-UI. SDK даёт две формы.
Async iterator — Node-классика для CLI и backend:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1",
});
async function streamChat(prompt: string) {
const stream = await client.chat.completions.create({
model: "claude-opus-4-7",
messages: [{ role: "user", content: prompt }],
stream: true,
});
let firstTokenTime: number | null = null;
const start = Date.now;
for await (const chunk of stream) {
if (!firstTokenTime && chunk.choices[0]?.delta?.content) {
firstTokenTime = Date.now - start;
console.log(`TTFT: ${firstTokenTime}ms`);
}
const content = chunk.choices[0]?.delta?.content;
if (content) {
process.stdout.write(content);
}
}
console.log(`\nTotal: ${Date.now - start}ms`);
}
await streamChat("Расскажи о SSE в 5 предложениях.");
ReadableStream Web API — для Edge Functions, отдачи SSE в браузер:
// app/api/chat/route.ts — Next.js Edge route
import OpenAI from "openai";
import { OpenAIStream, StreamingTextResponse } from "ai"; // Vercel AI SDK
export const runtime = "edge";
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1",
});
export async function POST(req: Request) {
const { messages } = await req.json;
const response = await client.chat.completions.create({
model: "gpt-5-5",
messages,
stream: true,
});
// Конвертируем в ReadableStream и шлём как SSE
const stream = OpenAIStream(response);
return new StreamingTextResponse(stream);
}
runtime = "edge" запускает функцию на Vercel Edge — близкая к пользователю инфраструктура с минимальной TTFT. Через Promptra baseURL это работает идентично — никаких отличий между Edge и Node. Подробнее про SSE и TTFT — Streaming LLM-ответов через SSE на Python (паттерны те же, синтаксис другой).
Без Vercel AI SDK — ручной ReadableStream:
export async function POST(req: Request) {
const { messages } = await req.json;
const response = await client.chat.completions.create({
model: "gpt-5-5",
messages,
stream: true,
});
const encoder = new TextEncoder;
const stream = new ReadableStream({
async start(controller) {
try {
for await (const chunk of response) {
const text = chunk.choices[0]?.delta?.content || "";
if (text) {
controller.enqueue(encoder.encode(`data: ${JSON.stringify({ text })}\n\n`));
}
}
controller.enqueue(encoder.encode("data: [DONE]\n\n"));
} catch (e) {
controller.error(e);
} finally {
controller.close;
}
},
});
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
},
});
}
Tool calls с типизацией через Zod
Tool calls без типизации — arguments: any, runtime баги. С Zod получаете compile-time типы и runtime-валидацию.
import OpenAI from "openai";
import { z } from "zod";
import zodToJsonSchema from "zod-to-json-schema";
const GetCurrencyRateSchema = z.object({
base: z.string.length(3).describe("Базовая валюта, ISO код, например USD"),
target: z.string.length(3).describe("Целевая валюта, ISO код, например RUB"),
});
type GetCurrencyRateArgs = z.infer<typeof GetCurrencyRateSchema>;
const tools: OpenAI.ChatCompletionTool[] = [
{
type: "function",
function: {
name: "get_currency_rate",
description: "Получить актуальный курс валют от ЦБ РФ",
parameters: zodToJsonSchema(GetCurrencyRateSchema, { target: "openAi" }),
},
},
];
async function getCurrencyRate(args: GetCurrencyRateArgs): Promise<{ rate: number }> {
// Реальный вызов API ЦБ
const res = await fetch(`https://www.cbr-xml-daily.ru/latest.js`);
const data = await res.json;
return { rate: data.rates[args.base] };
}
async function agentTurn(userMessage: string) {
const messages: OpenAI.ChatCompletionMessageParam[] = [
{ role: "user", content: userMessage },
];
while (true) {
const response = await client.chat.completions.create({
model: "claude-opus-4-7",
messages,
tools,
tool_choice: "auto",
});
const choice = response.choices[0];
messages.push(choice.message);
if (choice.finish_reason === "stop") {
return choice.message.content;
}
if (choice.message.tool_calls) {
for (const toolCall of choice.message.tool_calls) {
if (toolCall.function.name === "get_currency_rate") {
// Runtime-валидация через Zod
const parsed = GetCurrencyRateSchema.parse(JSON.parse(toolCall.function.arguments));
const result = await getCurrencyRate(parsed);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: JSON.stringify(result),
});
}
}
}
}
}
Ключевые моменты:
- z.infer: тип GetCurrencyRateArgs выводится из схемы — никаких дублей.
- zodToJsonSchema: одна схема Zod → JSON schema для OpenAI tools.
- runtime parse через GetCurrencyRateSchema.parse(...) — модель может прислать невалидный JSON, нужен defensive guard.
- while loop с защитой от бесконечности — ограничьте max_iterations: 10.
Подробнее про function calling на Python — Function calling и tool use на Python.
Structured outputs: гарантированный JSON
OpenAI 2024+ поддерживает response_format: json_schema — модель гарантированно вернёт валидный JSON по схеме. Через Promptra работает для совместимых моделей (GPT-5+, новые Claude через переходник).
import { z } from "zod";
import zodToJsonSchema from "zod-to-json-schema";
const ProductExtractSchema = z.object({
name: z.string,
price_rub: z.number,
in_stock: z.boolean,
tags: z.array(z.string),
});
type ProductExtract = z.infer<typeof ProductExtractSchema>;
async function extractProduct(text: string): Promise<ProductExtract> {
const response = await client.chat.completions.create({
model: "gpt-5-5",
messages: [
{ role: "system", content: "Извлекай продукт из текста как JSON." },
{ role: "user", content: text },
],
response_format: {
type: "json_schema",
json_schema: {
name: "product",
schema: zodToJsonSchema(ProductExtractSchema, { target: "openAi" }),
strict: true,
},
},
});
const content = response.choices[0].message.content!;
return ProductExtractSchema.parse(JSON.parse(content));
}
const product = await extractProduct("Купил iPhone 17 Pro за 119900 ₽, в наличии, теги: смартфон, флагман.");
// product типизирован как ProductExtract на compile-time
// + runtime-проверка через Zod parse
strict: true гарантирует, что модель не выйдет за рамки схемы. На крупных моделях (GPT-5, Opus 4.7) это работает с надёжностью >99.5%. Для дешёвых моделей лучше дополнительно валидировать через Zod как fallback.
Подробнее про подсчёт токенов и стоимость структурированных ответов — Как считать токены LLM.
Batching через p-limit
Когда нужно обработать 1000 запросов параллельно — Promise.all напрямую упрётся в socket limit (256 по умолчанию в Node) или 429 от провайдера. Правильный паттерн — p-limit:
import pLimit from "p-limit";
interface Item {
id: string;
text: string;
}
interface ProcessedItem extends Item {
summary: string;
tokens: number;
}
async function processBatch(items: Item[], concurrency = 10): Promise<ProcessedItem[]> {
const limit = pLimit(concurrency);
const tasks = items.map((item) =>
limit(async : Promise<ProcessedItem> => {
const response = await client.chat.completions.create({
model: "deepseek-v4-pro", // 30/60 ₽ — дёшево для batch
messages: [
{ role: "user", content: `Суммаризируй: ${item.text}` },
],
max_tokens: 200,
});
return {
...item,
summary: response.choices[0].message.content ?? "",
tokens: response.usage?.total_tokens ?? 0,
};
})
);
return Promise.all(tasks);
}
const items: Item[] = [/* 1000 элементов */];
const processed = await processBatch(items, 10); // 10 параллельных
Concurrency = 10 — баланс между скоростью и rate limit'ом провайдера. Для DeepSeek можно 20–30, для Opus 4.7 лучше 5–8.
Для очень больших batch (>1000) выгоднее Async и Batch API LLM с 50% скидкой — отправляете JSONL-файл, провайдер обрабатывает в течение 24 часов с половинной ценой.
Retry через p-retry с типизированными ошибками
openai-node имеет встроенный retry (maxRetries: 3), но для production нужен контроль через p-retry:
import OpenAI from "openai";
import pRetry, { AbortError } from "p-retry";
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1",
maxRetries: 0, // выключаем встроенный, делаем сами
timeout: 120_000,
});
async function llmCallWithRetry(messages: OpenAI.ChatCompletionMessageParam[], model: string) {
return pRetry(
async => {
try {
return await client.chat.completions.create({ model, messages });
} catch (err) {
// 4xx (кроме 429) не ретраим — баг в коде
if (err instanceof OpenAI.APIStatusError) {
if (err.status === 429) {
// 429 — ретраим
throw err;
}
if (err.status >= 400 && err.status < 500) {
// 400, 401, 403, 422 — не ретраим
throw new AbortError(err.message);
}
}
// 5xx, network — ретраим
throw err;
}
},
{
retries: 5,
factor: 2,
minTimeout: 1000,
maxTimeout: 60_000,
randomize: true, // jitter
onFailedAttempt: (err) => {
console.warn(`Attempt ${err.attemptNumber} failed: ${err.message}`);
},
}
);
}
Параметры p-retry:
- factor: 2 — exponential (1с, 2с, 4с, 8с, 16с).
- maxTimeout: 60_000 — потолок.
- randomize: true — jitter, без него thundering herd.
- AbortError — бросаете когда retry бессмысленно (4xx).
Это аналог Python tenacity. Подробнее про стратегии retry и circuit breaker — Rate limiting и retry стратегии для LLM API.
Типизированный error handling
openai-node экспортирует типизированные классы ошибок. Стандарт production:
import OpenAI from "openai";
try {
const response = await client.chat.completions.create({ ... });
return response;
} catch (err) {
if (err instanceof OpenAI.APIConnectionError) {
// Сеть, DNS, TCP — стоит retry
console.error("Network error:", err.cause);
} else if (err instanceof OpenAI.APITimeoutError) {
// Таймаут — retry с увеличенным
console.error("Timeout after", err.message);
} else if (err instanceof OpenAI.RateLimitError) {
// 429 — retry с backoff и retry-after
const retryAfter = err.headers["retry-after"];
console.error("Rate limited, retry after", retryAfter);
} else if (err instanceof OpenAI.APIStatusError) {
// 4xx (кроме 429) и 5xx
console.error(`API error ${err.status}: ${err.message}`);
if (err.status >= 400 && err.status < 500) {
// Баг в коде, не retry
throw err;
}
} else {
// Неожиданная ошибка
console.error("Unexpected:", err);
throw err;
}
}
Не ловите catch (err: any) — теряете тип. Не ловите catch (err: Error) — пропускаете специфичные методы. Правильно — catch (err) с typeof + instanceof проверками.
Edge Functions: специфика
Vercel Edge и Cloudflare Workers — серьёзные runtime-ограничения:
- Нет полноценного fs — конфиги в env vars, не в файлах.
- Нет dynamic imports — все зависимости статически.
- Нет child_process — нельзя shell-out.
- Лимит CPU time — 50 сек Edge, 30 сек Worker (на free).
- WebStreams only — никаких Node streams.
- process minimal — только env vars.
LLM-streaming идеально ложится на Edge: ReadableStream + Response отдаются клиенту с минимальной TTFT (близкий regional PoP). Чат-приложение на Vercel Edge с Promptra:
// app/api/chat/route.ts
import OpenAI from "openai";
import { z } from "zod";
export const runtime = "edge";
export const dynamic = "force-dynamic";
const RequestSchema = z.object({
messages: z.array(z.object({
role: z.enum(["user", "assistant", "system"]),
content: z.string,
})),
model: z.enum(["claude-opus-4-7", "gpt-5-5", "gemini-3-1-pro"]).default("claude-opus-4-7"),
});
const client = new OpenAI({
apiKey: process.env.PROMPTRA_API_KEY!,
baseURL: "https://api.promptra.ru/v1",
});
export async function POST(req: Request) {
const body = await req.json;
const { messages, model } = RequestSchema.parse(body);
const stream = await client.chat.completions.create({
model,
messages,
stream: true,
max_tokens: 2000,
});
const encoder = new TextEncoder;
const readable = new ReadableStream({
async start(controller) {
try {
for await (const chunk of stream) {
const text = chunk.choices[0]?.delta?.content;
if (text) {
controller.enqueue(encoder.encode(`data: ${JSON.stringify({ text })}\n\n`));
}
}
controller.enqueue(encoder.encode("data: [DONE]\n\n"));
controller.close;
} catch (e) {
controller.error(e);
}
},
});
return new Response(readable, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
"Connection": "keep-alive",
"X-Accel-Buffering": "no",
},
});
}
Заголовок X-Accel-Buffering: no критичен — без него nginx буферизует SSE и стрим встаёт. Документация Edge — vercel.com/docs.
Production-чеклист
- [ ] openai-node + TypeScript strict mode — никаких any.
- [ ] Типизированные классы ошибок в catch — instanceof OpenAI.RateLimitError и т.д.
- [ ] Zod-схемы для tool calls + runtime parse — нет arguments: any.
- [ ] structured outputs через json_schema где возможно — гарантированный валидный JSON.
- [ ] p-limit для batching — concurrency 5–10 для flagship, 20+ для дешёвых.
- [ ] p-retry с factor=2, randomize=true — exponential backoff с jitter.
- [ ] AbortError на 4xx — не ретраить баги в коде.
- [ ] maxRetries: 0 в SDK — все ретраи через p-retry, не дублировать.
- [ ] timeout: 120_000 — для reasoning-моделей.
- [ ] runtime: "edge" для streaming chat-UI.
- [ ] X-Accel-Buffering: no заголовок в SSE — иначе nginx буферизует.
- [ ] PROMPTRA_API_KEY в env vars, не в коде — никаких hardcoded ключей.
- [ ] Логирование request_id, user_id, model, tokens, cost, duration — для observability.
- [ ] Zod-валидация request body на каждой API-ручке — защита от мусорных запросов.
Через Promptra одна замена baseURL: "https://api.promptra.ru/v1" подключает любую модель — Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Pro — без переписывания TypeScript-кода. Для сравнения цен и выбора оптимальной модели — Сравнение цен LLM 2026. Для observability стека на Node — Langfuse поддерживает Node SDK с теми же декораторами, что и Python: Логирование и observability LLM-приложений.
Антипаттерны
- any-типы из-за лени — теряете compile-time проверку, ловите runtime баги.
- try/catch с catch (err) без типизации — не различаете 429 от 400.
- Promise.all на 1000+ запросах — socket limit и 429.
- maxRetries и p-retry одновременно — дублируется, retry-storm.
- Полный prompt в console.log — утечка PII в Vercel logs.
- Без Zod на tool call arguments — модель пришлёт мусор, runtime crash.
- runtime: "nodejs" для streaming chat-UI — теряете преимущество edge PoP.
- Без X-Accel-Buffering — nginx буферизует SSE, latency растёт.
Запасные варианты
- Vercel AI SDK — обёртка над openai-node + Anthropic SDK + Google + Mistral с унифицированным API. Удобно для multi-provider приложений.
- LangChain.js — для сложных агентских pipeline с memory и RAG. Тяжелее, но больше функций из коробки.
- Hono / Elysia — лёгкие фреймворки для Bun/Edge, быстрее Next.js на тонких ручках.
- NestJS — для классических корпоративных Node-бэкендов с DI и модульной архитектурой.
Для русского B2B на Next.js + Vercel Edge — связка openai-node + Zod + p-limit + p-retry покрывает 90% сценариев без лишних зависимостей.
FAQ
Почему openai-node SDK, а не fetch?
SDK даёт типизированные методы, автоматический retry, async iterators для streaming, parsing tool calls. Fetch — писать всё самому. Через Promptra base_url openai-node работает со всеми моделями — Claude, GPT, Gemini, DeepSeek.
Как типизировать ответы LLM строго?
Три уровня: структурные типы из SDK (ChatCompletion), Zod schemas для tool calls с runtime parse, response_format json_schema для structured outputs. Compile-time + runtime guarantee.
Async iterator или ReadableStream?
Async iterator — Node-классика для backend (for await ... of stream). ReadableStream — Web-стандарт для Edge Functions и SSE на фронтенд. Promptra поддерживает оба одинаково.
Как batchить с лимитом concurrency?
p-limit — const limit = pLimit(10); await Promise.all(items.map(i => limit( => llmCall(i)))). Concurrency 10 для flagship, 20+ для дешёвых. Не Promise.all напрямую — упрётесь в socket limit.
Edge или Node для LLM?
Edge — для streaming chat-UI (близкий PoP, минимальная TTFT). Node — для backend, агентов с tool calling, batch. Через Promptra baseURL работает идентично.
Как обрабатывать ошибки openai-node?
instanceof проверки: OpenAI.RateLimitError (429), OpenAI.APIStatusError (4xx/5xx), OpenAI.APIConnectionError (сеть), OpenAI.APITimeoutError. Не catch (err: any) — теряете тип.
Promptra — российский LLM API-агрегатор
Один OpenAI-совместимый endpoint ко всем флагманам: OpenAI (GPT-5.5, GPT-5.4), Anthropic (Claude Opus 4.7, Sonnet 4.6), Google (Gemini 3.1 Pro, 3.5 Flash), DeepSeek V4 Pro, Qwen 3.6 Plus.
Цены 1-в-1 с провайдером по курсу ЦБ — без наценки на токены. Оплата в рублях по договору, полный пакет закрывающих документов. Без VPN — легальный B2B-сервис в России.
Если статья была полезной — попробуйте Promptra: главная страница · каталог моделей · документация