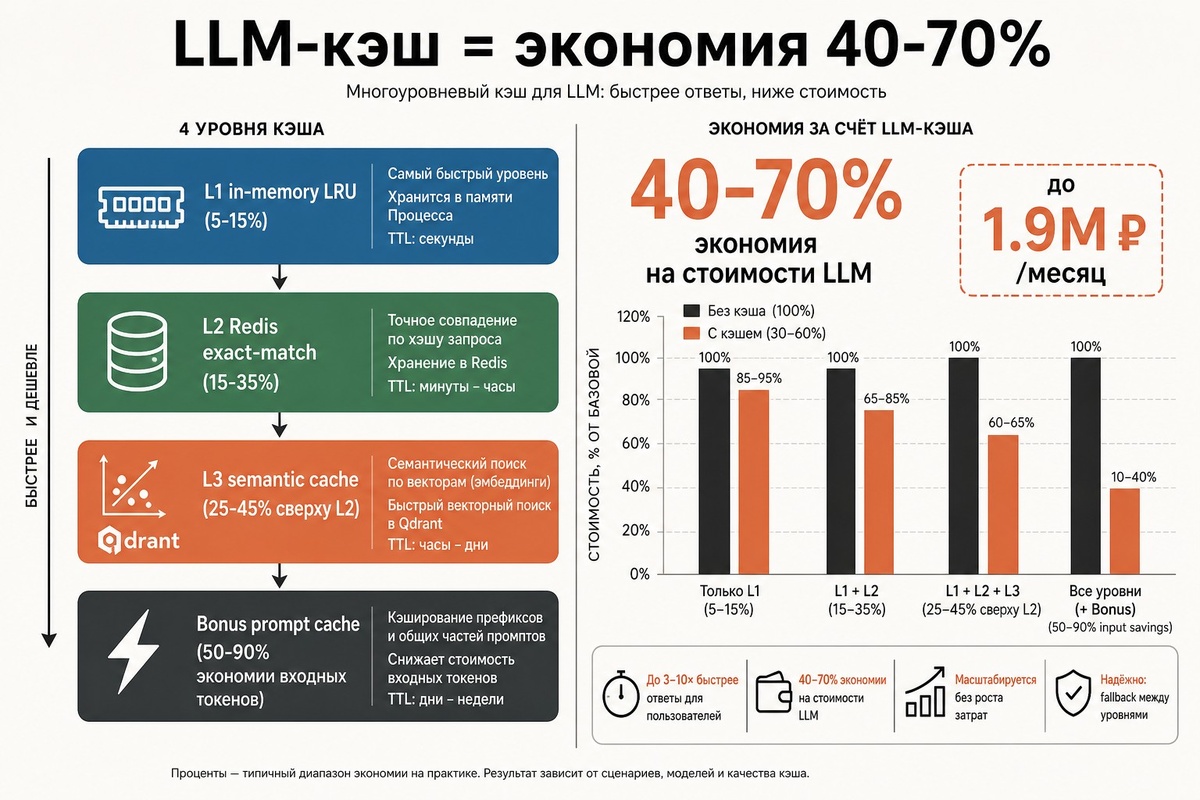
LLM-API — самая дорогая зависимость в стеке. На FAQ-боте с 100K запросов в день Claude Opus 4.7 (350/1790 ₽ за 1М токенов) выливается в 250–400 тыс ₽ в месяц. Половину этой суммы можно вернуть кэшированием: точные повторы запросов часто составляют 20–40%, перефразированные близкие — ещё 20–30%, итого 40–70% запросов вообще не должны доходить до модели. Через единый шлюз Promptra prompt caching от Anthropic и OpenAI пробрасывается без изменений, что плюсом срезает 60–80% input-стоимости для агентов с длинным system prompt.
Этот гайд — три уровня кэширования с готовым кодом: in-memory LRU для микро-кэша последних N запросов в одном процессе, Redis exact-match с TTL для распределённого кэша между worker'ами, semantic cache через embeddings и Qdrant для семантически близких запросов. С реальными бенчмарками cost savings, инвалидацией, защитой от ложных срабатываний. оплата в рублях по договору, полный пакет закрывающих документов.
TL;DR — три уровня кэша
- Уровень: L1 in-memory LRU • Где: RAM процесса • Hit rate: 5–15% • Когда: Микро-кэш горячих запросов, один worker
- Уровень: L2 Redis exact-match • Где: Распределённый • Hit rate: 15–35% • Когда: Точные повторы между worker'ами
- Уровень: L3 semantic cache • Где: Qdrant + embeddings • Hit rate: 25–45% сверху L2 • Когда: Перефразированные вопросы, FAQ-боты
- Уровень: Bonus prompt cache • Где: На стороне провайдера • Hit rate: 60–80% input savings • Когда: Агенты с длинным system prompt
Суммарно при удачной комбинации — 50–70% запросов не доходят до flagship-модели.
L1: in-memory LRU для горячих запросов
Самый простой уровень — кэш в RAM одного worker'а через functools.lru_cache или его asyncio-вариант. Подходит для маленьких микросервисов с одним процессом. Эта статья — production-расширение нашего pillar-гида полный технический гид по LLM API на Python: токены, function calling, streaming, RAG, async/batch.
from functools import lru_cache
import hashlib
import json
def messages_hash(messages: list[dict], model: str) -> str:
"""Стабильный hash от messages и model."""
payload = json.dumps({"messages": messages, "model": model}, sort_keys=True)
return hashlib.sha256(payload.encode).hexdigest
@lru_cache(maxsize=1024)
def _cached_completion(key: str, model: str, messages_json: str) -> str:
"""Внутренний кэш, ключ — hash. Содержит JSON-сериализованный ответ."""
messages = json.loads(messages_json)
response = client.chat.completions.create(model=model, messages=messages)
return json.dumps({
"content": response.choices[0].message.content,
"usage": response.usage.model_dump,
})
def llm_with_l1(messages: list[dict], model: str) -> dict:
key = messages_hash(messages, model)
return json.loads(_cached_completion(key, model, json.dumps(messages, sort_keys=True)))
Плюсы: одна строка, нет внешних зависимостей. Минусы: кэш живёт только в одном процессе, теряется при рестарте, не масштабируется на 10+ worker'ов. Подходит для CLI-тулов, dev-режима, маленьких pet-проектов.
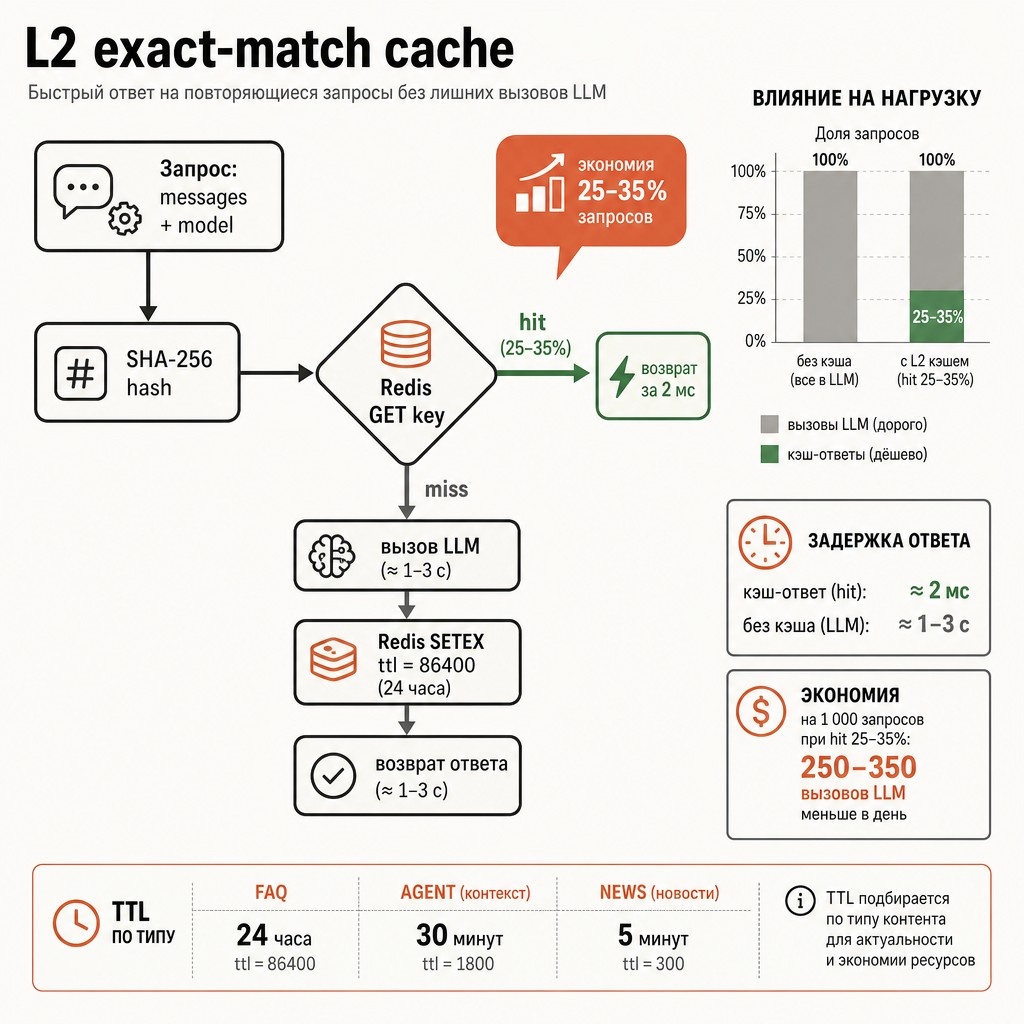
L2: Redis exact-match с TTL
Базовый production-кэш: hash запроса как ключ, сериализованный ответ как значение, TTL по типу контента. Работает между всеми worker'ами.
import hashlib
import json
import redis.asyncio as redis
from openai import OpenAI
r = redis.from_url("redis://localhost:6379/3")
client = OpenAI(api_key="sk-promptra-...", base_url="https://api.promptra.ru/v1")
CACHE_TTL_BY_TYPE = {
"faq": 86400, # 24 часа для статичных FAQ
"summary": 14400, # 4 часа для summary
"agent": 1800, # 30 минут для агентских ответов
"news": 300, # 5 минут для новостей
}
def cache_key(messages: list[dict], model: str, kind: str) -> str:
payload = json.dumps({"messages": messages, "model": model}, sort_keys=True, ensure_ascii=False)
h = hashlib.sha256(payload.encode("utf-8")).hexdigest
return f"llm:{kind}:{model}:{h}"
async def llm_with_l2(messages: list[dict], model: str, kind: str = "agent") -> dict:
key = cache_key(messages, model, kind)
cached = await r.get(key)
if cached:
# Метрика hit
await r.incr(f"cache:hits:{kind}")
return json.loads(cached)
# Метрика miss
await r.incr(f"cache:misses:{kind}")
response = client.chat.completions.create(model=model, messages=messages)
result = {
"content": response.choices[0].message.content,
"usage": {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
},
"model": response.model,
}
await r.setex(key, CACHE_TTL_BY_TYPE.get(kind, 1800), json.dumps(result, ensure_ascii=False))
return result
Ключевые моменты:
- sort_keys=True + ensure_ascii=False — стабильный hash независимо от порядка ключей и unicode.
- TTL по типу — статичные FAQ живут долго, новости — недолго.
- Префикс llm:<kind>:<model>: — упрощает инвалидацию по типу или модели (SCAN llm:faq:* + DEL).
- Метрики hits/misses — обязательны для оценки эффективности.
Hit rate exact-match cache: на FAQ-боте обычно 20–40%, на агентских pipeline — 5–15%, на креативной генерации — почти 0. Для перефразированных вопросов нужен следующий уровень.
L3: semantic cache через embeddings
Exact-match не ловит перефразированное: «как открыть API ключ» и «где взять токен для API» — разные строки, но один смысл. Semantic cache решает это через embeddings.
Архитектура:
- На запрос считаем embedding (используем дешёвую модель вроде text-embedding-3-small или DeepSeek embeddings).
- Ищем в Qdrant top-1 точку с косинусным сходством > 0.92.
- Если найдена — возвращаем кэшированный ответ.
- Если нет — вызываем LLM, сохраняем embedding+ответ в Qdrant.
from openai import OpenAI
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
import uuid
import json
client = OpenAI(api_key="sk-promptra-...", base_url="https://api.promptra.ru/v1")
qdrant = QdrantClient(host="localhost", port=6333)
COLLECTION = "llm_semantic_cache"
EMBEDDING_MODEL = "text-embedding-3-small" # 1536 dim
SIMILARITY_THRESHOLD = 0.92
# Один раз при старте
qdrant.recreate_collection(
collection_name=COLLECTION,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
def embed(text: str) -> list[float]:
resp = client.embeddings.create(model=EMBEDDING_MODEL, input=text)
return resp.data[0].embedding
def query_text(messages: list[dict]) -> str:
"""Берём последнее user-сообщение как query для embedding."""
for m in reversed(messages):
if m["role"] == "user":
return m["content"]
return ""
def llm_with_semantic_cache(messages: list[dict], model: str) -> dict:
query = query_text(messages)
if not query or len(query) < 10:
# Слишком короткий запрос — semantic cache бесполезен
return raw_llm(messages, model)
# Embedding запроса
query_vector = embed(query)
# Поиск в Qdrant
hits = qdrant.search(
collection_name=COLLECTION,
query_vector=query_vector,
limit=1,
with_payload=True,
)
if hits and hits[0].score >= SIMILARITY_THRESHOLD:
# Hit
return {
"content": hits[0].payload["content"],
"from_cache": True,
"similarity": hits[0].score,
}
# Miss — идём в LLM
response = client.chat.completions.create(model=model, messages=messages)
content = response.choices[0].message.content
# Сохраняем
qdrant.upsert(
collection_name=COLLECTION,
points=[PointStruct(
id=str(uuid.uuid4),
vector=query_vector,
payload={"query": query, "content": content, "model": model},
)],
)
return {"content": content, "from_cache": False}
Параметры на тюнинг:
- SIMILARITY_THRESHOLD = 0.92 — стартовая точка. Ниже 0.88 — много ложных срабатываний. Выше 0.96 — почти ничего не хитится. Для FAQ — 0.93. Для технических вопросов — 0.96.
- EMBEDDING_MODEL — дешёвая модель достаточна. text-embedding-3-small или DeepSeek embeddings (через Promptra) дают качество, сопоставимое с LLM-pump для FAQ.
- Длина query > 10 символов — embeddings от слишком коротких запросов нестабильны.
Подробнее про embeddings и RAG-стек — Embeddings и векторный поиск: RAG-стек 2026. Про подбор embedding-модели для русского — Embeddings API в России.
Защита от ложных срабатываний
Semantic cache опасен когда близкие по смыслу запросы требуют разных ответов. Классические сценарии и решения:
1. Запросы с параметрами / ID. «Заказы клиента 42» и «заказы клиента 43» — embedding почти идентичен (0.97+), но ответы разные. Решение — исключить такие запросы из semantic cache:
import re
ID_PATTERNS = [
r"\b\d{3,}\b", # Длинные числа
r"\b[A-Z]{2,}\d{2,}\b", # SKU/Article codes
r"@\w+", # Mentions
r"https?://\S+", # URLs
]
def has_parametric(text: str) -> bool:
return any(re.search(p, text) for p in ID_PATTERNS)
def llm_with_smart_cache(messages, model):
query = query_text(messages)
if has_parametric(query):
# Параметрический запрос — только exact-match L2
return llm_with_l2(messages, model, kind="parametric")
# Чистый текст — можно semantic
return llm_with_semantic_cache(messages, model)
2. Контекстно-зависимые запросы. «Расскажи подробнее» в чате означает разное в зависимости от истории. Решение — кэшировать только single-turn запросы (длина messages = 1–2), или включать hash от system prompt в ключ.
3. Запросы с датой/временем. «Покажи новости сегодня» — сегодня меняется. Кэшировать на короткий TTL (5–15 минут) и инвалидировать в полночь.
Дополнительная защита — whitelist по интентам: классифицируете запрос в один из N интентов (FAQ, news, agent, code), и semantic cache работает только для FAQ-интента.
Prompt caching: бонус от провайдера
OpenAI и Anthropic кэшируют префикс промта на своей стороне. Это другой механизм, не путать с собственным кэшем:
- Anthropic prompt caching: пометка cache_control: {type: "ephemeral"} на блоке system или последнем сообщении. Первый запрос — обычная цена + 25% за запись. Последующие в течение 5 минут — ×0.1 от input. Документация — Anthropic prompt caching.
- OpenAI prompt caching: автоматическое для промтов >1024 токенов. Префикс кэшируется на 5–10 минут, повтор стоит ×0.5 от input. Заголовок ответа prompt_cache_hit_tokens показывает количество cached токенов.
Через Promptra prompt caching работает без изменений — просто передаёте те же параметры:
# Anthropic-стиль через Promptra
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{
"role": "system",
"content": "Ты помощник по продуктам Promptra. <Длинный system prompt 5000+ токенов>",
"cache_control": {"type": "ephemeral"}, # пробрасывается напрямую
},
{"role": "user", "content": user_message},
],
)
Экономия для агентов с long system prompt:
- Сценарий: Agent с 8K system, 200 RPS, GPT-5.5 • Без cache: 8K × 200 × 350 ₽/M = 560 ₽/мин на input • С prompt cache: 8K × 200 × 175 ₽/M = 280 ₽/мин • Экономия: 50% input
- Сценарий: Agent с 15K system, 50 RPS, Opus 4.7 • Без cache: 15K × 50 × 350 ₽/M = 263 ₽/мин • С prompt cache: 15K × 50 × 35 ₽/M = 26 ₽/мин • Экономия: 90% input
Для агентов с богатым system prompt экономия только на prompt caching достигает 200K-600K ₽/месяц. См. также Сравнение цен LLM 2026 для расчёта по конкретной модели.
Реальные бенчмарки cost savings
Production-замеры с FAQ-бота (русские пользователи, Mostly support questions):
Сценарий: 100K запросов/день, GPT-5.5 (350/2150 ₽/M)
Средний запрос: 800 input + 400 output токенов
Baseline (без кэша):
- 100K × (800 × 350 + 400 × 2150) / 1M = 28 000 + 86 000 = 114 000 ₽/день
- 3.4 млн ₽/месяц
+L2 Redis exact-match (hit 28%):
- 72K вызовов LLM × средняя цена = 114K × 0.72 = 82 080 ₽/день
- Экономия 28% = 31 920 ₽/день, 957 600 ₽/месяц
+L3 semantic cache (cumulative hit 55%):
- 45K вызовов LLM × средняя цена = 114K × 0.45 = 51 300 ₽/день
- Экономия 55% = 62 700 ₽/день, 1 881 000 ₽/месяц
- Минус embedding-стоимость (для 45K hits + 100K queries × $0.00002) ≈ 700 ₽/день
- Net 62K ₽/день = 1.86M ₽/месяц
+Prompt caching на system prompt (агентский use case):
- На каждый вызов экономия 50% input → ещё минус 6% от итога
- Net 1.91M ₽/месяц экономии = 22.9M ₽/год
Реальные числа зависят от природы трафика. Для уникального креатива (генерация маркетингового текста) hit rate < 5%, экономия минимальна. Для FAQ-ботов, support чатов и интент-классификации — 50–70% типично.
Инфраструктура semantic cache:
- Redis 8 GB RAM — 600–1200 ₽/мес (Yandex Cloud).
- Qdrant 1 vCPU + 2 GB RAM на 100K точек — 500–800 ₽/мес.
- Embedding-вызовы (text-embedding-3-small) — около $0.02 на 1M токенов = 1.43 ₽/M. На 100K запросов с 200 токенов = 28.6 ₽/день.
Итого инфра semantic cache — 1500–2000 ₽/мес против экономии 60–200K ₽/мес. ROI положительный с первого дня. Подробнее про async batch как ещё один способ экономии — Async и Batch API LLM: 50% скидка.
Инвалидация: что и когда выкидывать
Кэш без инвалидации — это утечка времени. Стандартные триггеры:
- Время (TTL) — встроено в Redis SETEX. Для Qdrant — отдельный crontab cleanup по полю created_at.
- Смена модели — все ответы под старой моделью становятся неактуальны. Префикс ключа включает имя модели → DROP COLLECTION или DELETE FROM ... WHERE model = old_model.
- Смена system prompt — если изменили промт агента, старые ответы инвалидируются. Включайте hash от system prompt в cache key.
- Обновление документации (для RAG) — при reingest корпуса инвалидируете весь кэш ответов на основе старых документов.
- Ручная инвалидация — админский endpoint POST /admin/cache/invalidate с фильтром (kind/model/pattern).
# Bulk инвалидация по паттерну
async def invalidate_by_kind(kind: str):
cursor = 0
deleted = 0
while True:
cursor, keys = await r.scan(cursor, match=f"llm:{kind}:*", count=1000)
if keys:
deleted += await r.delete(*keys)
if cursor == 0:
break
return deleted
# Qdrant инвалидация
def invalidate_semantic_by_model(old_model: str):
qdrant.delete(
collection_name=COLLECTION,
points_selector={"filter": {"must": [{"key": "model", "match": {"value": old_model}}]}},
)
Production-чеклист
- [ ] L2 Redis обязателен в production — никаких прямых вызовов LLM на повторяющиеся запросы.
- [ ] TTL по типу контента — FAQ 24h, summary 4h, agent 30min, news 5min.
- [ ] Cache key включает model — миграция между моделями не отдаёт устаревшие ответы.
- [ ] Метрики hits/misses по типам — обязательны для оценки ROI.
- [ ] L3 semantic cache для FAQ-ботов и support — 25–45% сверху L2.
- [ ] SIMILARITY_THRESHOLD 0.92 стартово, тюнить под качество.
- [ ] Параметрические запросы (с ID, URL) — исключать из semantic cache.
- [ ] Prompt caching для агентов с long system prompt — экономия 50–90% input.
- [ ] Инвалидация по смене модели и system prompt — обязательна.
- [ ] Cleanup Qdrant раз в день — точки старше TTL удаляются.
- [ ] Admin endpoint для ручной инвалидации.
- [ ] Алерт на hit rate < 15% — что-то сломалось, либо трафик уникален и кэш не нужен.
Через Promptra все провайдеры доступны через base_url="https://api.promptra.ru/v1" — кэшированный код работает одинаково для Opus, GPT и Gemini, что упрощает A/B-тесты моделей с сохранением hit rate. Подробнее про миграцию между провайдерами — Миграция с OpenAI на Promptra за 10 минут. Про подсчёт токенов до отправки и оптимизацию payload — Как считать токены LLM.
Анти-паттерны
- Кэш без TTL — данные устаревают, ответы становятся неверными.
- Cache key без модели — после миграции на новую модель отдаёте старые ответы.
- Semantic cache на параметрические запросы — отвечаете про клиента 42 на запрос про клиента 43.
- Слишком низкий SIMILARITY_THRESHOLD (< 0.88) — много ложных hits, плохой UX.
- Слишком высокий threshold (> 0.97) — почти не хитится, инфра впустую.
- Игнорировать prompt caching — теряете 50–90% input savings на агентах.
- Кэш на write-операциях — нельзя кэшировать вызовы с tool calls которые меняют state.
- Не мониторить hit rate — не знаете эффективность.
Запасные варианты
- LangChain RedisCache / SemanticCache — готовые интеграции, но менее гибкие. Подойдут для прототипа.
- GPTCache — отдельная библиотека под Python с подключаемыми хранилищами. Удобно для исследования.
- OpenAI Batch API — для офлайн-обработки 50% скидка вместо кэша. Подходит когда задержка 24ч приемлема.
- Anthropic prompt caching — обязательно при длинных system prompt, экономия 90% input.
Для FAQ-бота на 50K-200K запросов в день оптимальный стек — Redis L2 + Qdrant semantic L3 + prompt caching. Окупается за 1–3 дня и стабильно работает годами.
FAQ
Чем отличаются exact-match и semantic cache?
Exact-match — кэш по точной строке (SHA-256 hash). Hit 15–35% на повторах. Semantic — по смыслу: embedding + поиск в векторной БД с порогом 0.92. Hit 40–70% на FAQ-ботах. Стоит embedding-вызов и инфра, но экономит в разы больше.
Что такое prompt caching от провайдера?
OpenAI и Anthropic кэшируют префикс промта на 5–10 минут. Anthropic — cache_control: ephemeral, ×0.1 от input. OpenAI — автоматически >1024 токенов, ×0.5. Через Promptra пробрасывается без изменений. Экономия 50–90% input для агентов с длинным system prompt.
Какой TTL ставить в Redis?
FAQ — 24 часа, summary — 4 часа, агенты — 30 минут, новости — 5 минут. Эмбеддинги кэшируйте долго, но инвалидируйте при смене модели.
Когда semantic cache даёт ложные срабатывания?
При параметрических запросах с ID/URL (заказы клиента 42 vs 43 — embedding 0.97). Решение — детектить параметры regex'ом и отправлять такие запросы только в L2 exact-match.
Сколько реально экономия?
FAQ-бот 100K req/day на GPT-5.5: baseline 3.4M ₽/мес, L2+L3+prompt cache ≈ 1.5M ₽/мес. Экономия 55–60%, 1.8M ₽/мес. Для уникального креатива — почти 0.
Можно ли кэшировать streaming?
Можно. При первом вызове аккумулируете chunks, сохраняете полный ответ. На hit эмулируете streaming через генератор с 20–40мс задержкой на token. Hit при streaming видно по TTFT < 50 мс.
Promptra — российский LLM API-агрегатор
Один OpenAI-совместимый endpoint ко всем флагманам: OpenAI (GPT-5.5, GPT-5.4), Anthropic (Claude Opus 4.7, Sonnet 4.6), Google (Gemini 3.1 Pro, 3.5 Flash), DeepSeek V4 Pro, Qwen 3.6 Plus.
Цены 1-в-1 с провайдером по курсу ЦБ — без наценки на токены. Оплата в рублях по договору, полный пакет закрывающих документов. Без VPN — легальный B2B-сервис в России.
Если статья была полезной — попробуйте Promptra: главная страница · каталог моделей · документация