Каждый запрос к LLM — это деньги в токенах. Чтобы платить ровно столько, сколько нужно, и не получать сюрпризов в счёте на конец месяца, надо уметь считать токены до отправки, а не только по факту в response.usage. В этом гайде — три рабочих способа подсчёта (через tiktoken, anthropic-tokenizer и SDK Gemini), точные формулы стоимости в рублях для всех актуальных моделей через Promptra, реальные коэффициенты плотности «символы → токены» для русского и английского, и шаблон функции, которая возвращает прогноз чека до того, как запрос ушёл в API.
Если вы уже мигрировали на единый эндпоинт по гайду «Миграция с OpenAI API на Promptra» и работаете на юр.лицо российское юр.лицо с полным пакетом закрывающих документов через ЭДО — этот материал поможет дожать юнит-экономику до копейки.
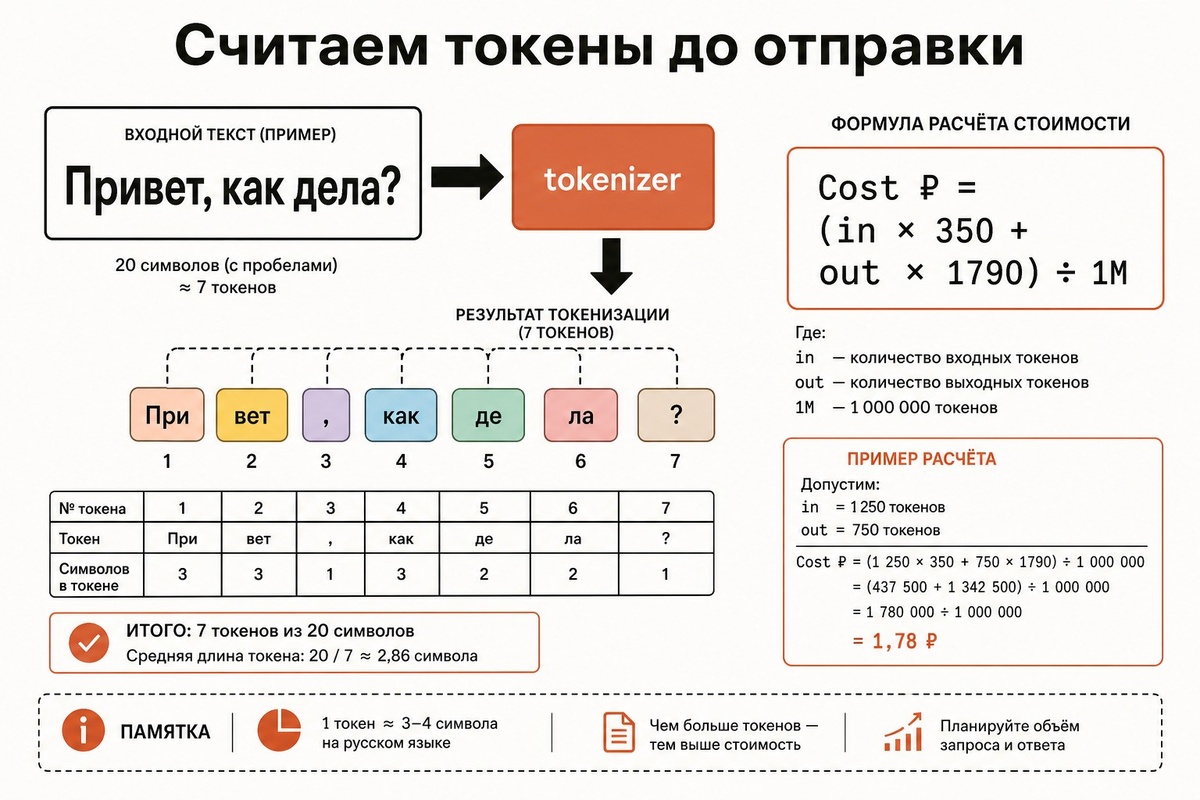
TL;DR — формула, которую надо запомнить
Cost ₽ = (input_tokens / 1_000_000) × input_price
+ (output_tokens / 1_000_000) × output_price
Input считаем заранее через tokenizer. Output прогнозируем по средней длине ответа на вашем трафике + 25% запаса. Тарифы — для Claude Opus 4.7 это 350/1790 ₽ за 1М, для GPT-5.5 — 350/2150 ₽, для Gemini 3.1 Pro — 140/860 ₽, для DeepSeek V4 Pro — 30/60 ₽. Один tokenizer на все модели не работает — у каждого вендора свой.
Что такое токен и почему он не равен слову
Токен — это атомарная единица текста, которую модель видит как одно целое. Один токен может быть целым словом (hello), куском слова (unbeliev+able), отдельным символом (!) или сразу несколькими байтами Unicode. Tokenizer — алгоритм, который преобразует строку в последовательность номеров из словаря. Современные LLM используют Byte-Pair Encoding (BPE) или близкие варианты: словарь строится так, чтобы частые подпоследовательности байт получали короткие коды, редкие — длинные. Эта статья — часть pillar-гида: полный технический гид по LLM API на Python — токены, function calling, streaming, RAG, batch.
Практические следствия:
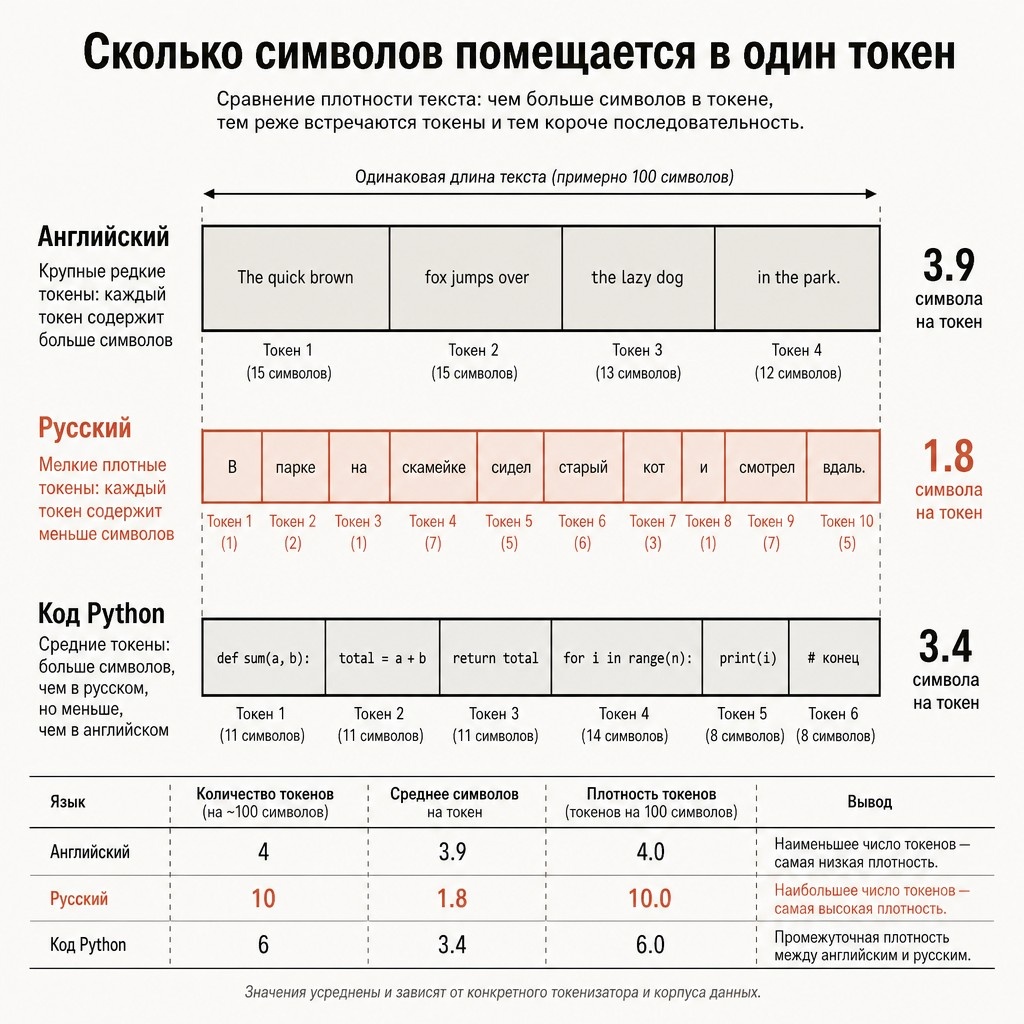
- Английский текст плотный: ~3.5–4 символа на токен в среднем. Слово production — один токен.
- Русский текст разреженный: ~1.5–2 символа на токен. Слово производство — обычно 3–4 токена (про+из+вод+ство или похожее разбиение).
- Код плотнее английского: ~3–5 символов на токен, потому что в словаре заранее есть частые ключевые слова и identifier'ы.
- JSON и XML — между обычным текстом и кодом по плотности, скобки и кавычки часто становятся отдельными токенами.
Это значит: один и тот же смысловой запрос на русском обычно стоит в 2–2.5 раза дороже, чем тот же запрос на английском. На больших объёмах это аргумент рассмотреть Gemini 3.1 Pro (140/860 ₽) или Claude Opus 4.7 с новым токенайзером, который стал заметно плотнее на кириллице.
Считаем токены для GPT через tiktoken
OpenAI выпускает официальный пакет `tiktoken` — это С++-биндинг к их BPE, работает быстро, считает точно. Через единый шлюз Promptra та же модель доступна по знакомому SDK — токенайзер используется тот же:
pip install tiktoken
Минимальный пример для GPT-5.5:
import tiktoken
# Берём encoding по имени модели — не хардкодим словарь
encoding = tiktoken.encoding_for_model("gpt-5-5")
text = "Привет, как дела? Расскажи короткий анекдот про разработчиков."
tokens = encoding.encode(text)
print(f"Текст: {len(text)} символов")
print(f"Токенов: {len(tokens)}")
print(f"Плотность: {len(text) / len(tokens):.2f} символа на токен")
Для chat-формата с системой и историей считают так:
from typing import List, Dict
def count_chat_tokens(messages: List[Dict], model: str = "gpt-5-5") -> int:
"""Возвращает число токенов в chat-completion запросе.
OpenAI добавляет ~4 служебных токена на каждое сообщение
плюс 3 на форматирование ответа. Эти числа меняются между
семействами моделей — для GPT-5.x они стабильны.
"""
encoding = tiktoken.encoding_for_model(model)
tokens_per_message = 4 # role, content, name, separator
tokens_per_name = -1 # если есть name, role не добавляется
total = 0
for msg in messages:
total += tokens_per_message
for key, value in msg.items:
total += len(encoding.encode(value))
if key == "name":
total += tokens_per_name
total += 3 # priming для assistant ответа
return total
Вызов:
messages = [
{"role": "system", "content": "Ты — помощник-программист. Отвечай по-русски, кратко."},
{"role": "user", "content": "Объясни, что такое замыкание в Python, в 3 предложениях."},
]
print(count_chat_tokens(messages)) # ≈ 65 токенов
Эта же функция работает для GPT-5.4 (170/1070 ₽), GPT-5.4 mini, и старых семейств — tiktoken.encoding_for_model сам подберёт нужный encoding.
Считаем токены для Claude через anthropic-tokenizer
У Claude — свой токенайзер, своя плотность, и tiktoken для него не подходит. Anthropic выпускает `anthropic-tokenizer` (Python — через anthropic SDK):
pip install anthropic
from anthropic import Anthropic
# Клиент через единый шлюз
client = Anthropic(
api_key="sk-promptra-...",
base_url="https://api.promptra.ru/v1",
)
response = client.messages.count_tokens(
model="claude-opus-4-7",
system="Ты — помощник по коду на Python.",
messages=[{"role": "user", "content": "Расскажи про async/await."}],
)
print(response.input_tokens) # точное число для этого запроса
count_tokens делает полноценный round-trip к API, но не списывает деньги — это бесплатный endpoint. Удобство — токенайзер всегда тот, что у текущей версии модели. С новым Claude Opus 4.7 токенайзер обновлён: тот же русский текст теперь даёт примерно на 10–20% меньше токенов, чем у Sonnet 3.5 годовой давности.
Если делать оффлайн (без round-trip) — есть пакет tokenizers (от Hugging Face) с загружаемыми весами токенайзера Claude, но это для продвинутого юзкейса. Для большинства задач count_tokens через SDK достаточно — он быстрый (десятки миллисекунд), и его результат гарантированно совпадает с тем, что модель посчитает реально.
Считаем токены для Gemini
Google в google-genai SDK предоставляет метод count_tokens:
pip install google-genai
from google import genai
client = genai.Client(
api_key="sk-promptra-...",
http_options={"base_url": "https://api.promptra.ru/v1"},
)
result = client.models.count_tokens(
model="gemini-3-1-pro",
contents="Расскажи про trade-offs между микросервисами и монолитом.",
)
print(result.total_tokens)
Gemini-токенайзер исторически плотнее на кириллице, чем OpenAI/Anthropic — отчасти потому что Google обучает модели на более многоязычном корпусе. На том же русском тексте Gemini 3.1 Pro обычно даёт на 15–30% меньше токенов, чем GPT-5.5. Это плюс к и без того низкой ставке 140/860 ₽ за 1М.
Точная формула стоимости запроса
Когда вы знаете input_tokens (точно — через tokenizer) и прогноз output_tokens (по средней + запас), считаете рубли:
PRICING = {
# модель: (input_₽_per_1M, output_₽_per_1M)
"claude-opus-4-7": (350, 1790),
"claude-sonnet-4-6": (210, 1070),
"gpt-5-5": (350, 2150),
"gpt-5-4": (170, 1070),
"gemini-3-1-pro": (140, 860),
"gemini-3-5-flash": (100, 640),
"deepseek-v4-pro": (30, 60),
"qwen-3-6-plus": (20, 130),
}
def estimate_cost_rub(
model: str,
input_tokens: int,
output_tokens_estimate: int,
) -> float:
"""Возвращает прогноз стоимости запроса в рублях."""
in_price, out_price = PRICING[model]
return (
input_tokens * in_price + output_tokens_estimate * out_price
) / 1_000_000
# Пример: Opus 4.7, 2000 input + 800 output
cost = estimate_cost_rub("claude-opus-4-7", 2000, 800)
print(f"Прогноз: {cost:.2f} ₽") # ≈ 2.13 ₽
Завышайте output_tokens_estimate на 20–30% от вашей реальной средней — реальность всегда шумит. Если у вас 95-перцентиль выхода — 1200 токенов, прогноз для бюджетного guard лучше считать по 1500.
Реальные коэффициенты плотности (Promptra benchmark 2026-05)
Замеряли на типовых задачах через единый шлюз — нагрузка ~5000 запросов на язык/модель. Цифры — медиана отношения «символы текста / токены»:
- Сегмент: Русский (статьи, диалоги) • GPT-5.5 (o200k_base): 1.8 • Claude Opus 4.7: 2.0 • Gemini 3.1 Pro: 2.3
- Сегмент: Английский (документация) • GPT-5.5 (o200k_base): 3.9 • Claude Opus 4.7: 4.0 • Gemini 3.1 Pro: 4.1
- Сегмент: Code Python • GPT-5.5 (o200k_base): 3.4 • Claude Opus 4.7: 3.6 • Gemini 3.1 Pro: 3.8
- Сегмент: JSON / API responses • GPT-5.5 (o200k_base): 2.7 • Claude Opus 4.7: 2.9 • Gemini 3.1 Pro: 3.1
- Сегмент: Тех-русский (термины) • GPT-5.5 (o200k_base): 2.1 • Claude Opus 4.7: 2.3 • Gemini 3.1 Pro: 2.5
Что это значит на практике: 1000 символов русского текста — это около 555 токенов для GPT-5.5 и 435 токенов для Gemini 3.1 Pro. На объёме 1M входных символов разница — 120K токенов, или 42 ₽ для GPT-5.5 против 17 ₽ для Gemini. Подробное сравнение моделей по сценариям — в «GPT-5.5 vs Claude Opus 4.7: бенчмарки 2026».
Pre-flight check: считаем чек до отправки
Финальный шаблон — функция, которая возвращает «можно ли отправить запрос» с учётом бюджета:
import tiktoken
def preflight(
model: str,
system: str,
user_message: str,
expected_output_tokens: int,
budget_rub: float,
) -> dict:
"""Считает прогноз стоимости и решает, отправлять ли запрос."""
encoding = tiktoken.encoding_for_model(model)
input_tokens = (
len(encoding.encode(system)) + len(encoding.encode(user_message)) + 8
)
cost = estimate_cost_rub(model, input_tokens, expected_output_tokens)
return {
"input_tokens": input_tokens,
"output_tokens_estimate": expected_output_tokens,
"estimated_cost_rub": round(cost, 4),
"allowed": cost <= budget_rub,
"model": model,
}
result = preflight(
model="gpt-5-5",
system="Ты — финансовый аналитик. Отвечай таблицами.",
user_message="Сделай SWOT-анализ нашего пайплайна обработки заявок.",
expected_output_tokens=2000,
budget_rub=10.0,
)
print(result)
# {
# 'input_tokens': 38,
# 'output_tokens_estimate': 2000,
# 'estimated_cost_rub': 4.31,
# 'allowed': True,
# 'model': 'gpt-5-5'
# }
Эту функцию подключают в три места:
- Frontend — показать пользователю «вы потратите ~4 ₽» перед нажатием «отправить».
- API guard — отказать запросу, если он превышает дневной лимит пользователя.
- Router — выбрать модель на лету: если задача простая, дешёвый прогноз идёт на GPT-5.4 (170/1070 ₽); если сложная — на Opus 4.7. Подробнее про роутинг моделей — в материале «Function calling и tool use на Python».
Как сверять прогноз с реальностью
После каждого запроса ответ возвращает response.usage с фактическими числами. Сохраняйте predicted и actual в лог:
response = client.chat.completions.create(...)
actual_in = response.usage.prompt_tokens
actual_out = response.usage.completion_tokens
# логируем для калибровки
logger.info({
"predicted_in": preflight_result["input_tokens"],
"actual_in": actual_in,
"predicted_out": preflight_result["output_tokens_estimate"],
"actual_out": actual_out,
"drift_in_pct": (actual_in - preflight_result["input_tokens"]) / actual_in * 100,
})
После 500–1000 запросов вы поймёте, на сколько процентов в среднем расходится ваш прогноз с реальностью, и подкрутите коэффициент завышения выходных токенов под свой профиль трафика. У зрелых сервисов на единый эндпоинт Promptra расход совпадает с прогнозом с точностью ±5% — это уровень, при котором можно показывать пользователю реальную цену и не бояться расхождений в счёте.
Оплата и закрывающие документы
Единый счёт на пополнение, прозрачный расход в дашборде по моделям и по ключам, по факту оказания услуг — закрывающие документы через ЭДО. Юрлицо-исполнитель — российское юр.лицо , резидент РФ. Сервисная комиссия 5% — только при пополнении; на токены наценки нет, всё считается строго по курсу ЦБ. Полный пакет (договор-оферта, счёт на оплату, акт оказанных услуг, счёт-фактура, УПД) приходит через ЭДО — Диадок, СБИС, Контур. Подробнее — на странице «Тарифы» и в гайде «Сравнение цен LLM 2026».
Что дальше
Считать токены — это базовая дисциплина для всех, кто работает с LLM на коммерческой нагрузке. Через 30 минут после прочтения у вас есть три рабочих функции: count_chat_tokens для OpenAI, client.messages.count_tokens для Claude, client.models.count_tokens для Gemini, и шаблон preflight для pre-flight бюджет-гарда. Прокачать дальше: function calling и tool use («Function calling и tool use на Python»), streaming для UI («Streaming LLM-ответов через SSE») и batch API для экономии до 50% («Async-вызовы и Batch API»). Если нужно прикинуть стоимость на вашем трафике или подключить ключ через юрлицо — напишите команде Promptra в Telegram.
📚 Главный гайд по теме: Лучшая нейросеть 2026: какую LLM выбрать под задачу — связанные материалы и обзор всей категории.
FAQ
Как точно посчитать токены в ChatGPT до отправки запроса?
Установите пакет tiktoken от OpenAI, выберите encoding для модели (o200k_base для GPT-5.x), и вызовите len(encoding.encode(text)). Это даёт точное число токенов — то же, что считает сама модель. Для chat-формата с ролями нужно учитывать служебные токены (около 4 на сообщение плюс 3 на сам ответ).
Почему одно слово в русском занимает больше токенов, чем в английском?
Tokenizer обучается на корпусе с большой долей английского, поэтому английские слова часто становятся одним токеном целиком, а русские разбиваются на 2–4 подслова. На практике коэффициент плотности — около 1.5–2 символа на токен для русского против 3.5–4 для английского.
Зачем считать токены, если usage возвращается в ответе?
Чтобы знать стоимость до отправки запроса, а не после. Это критично для прогноза цены пользователю, контроля бюджет-лимита в коде и выбора модели на лету по сложности задачи.
Какая формула стоимости запроса в рублях?
Cost = (input_tokens / 1_000_000) × input_price + (output_tokens / 1_000_000) × output_price. Для Claude Opus 4.7 это (in × 350 + out × 1790) / 1_000_000. Полная таблица — в материале «Сравнение цен LLM 2026».
Влияет ли способ форматирования промта на число токенов?
Сильно. Лишние повторы инструкций, длинные few-shot примеры и многословные system messages добавляют токены к каждому запросу. На больших объёмах экономия 100 токенов на запрос превращается в десятки тысяч рублей в месяц.
Что такое o200k_base и cl100k_base?
Имена encoding-словарей tiktoken. cl100k_base — для GPT-3.5/4. o200k_base — для GPT-5.x, словарь вдвое больше, плотнее упаковывает мультиязычный текст. Получайте encoding через tiktoken.encoding_for_model('gpt-5-5'), чтобы код переживал смену поколений.
Promptra — российский LLM API-агрегатор
Один OpenAI-совместимый endpoint ко всем флагманам: OpenAI (GPT-5.5, GPT-5.4), Anthropic (Claude Opus 4.7, Sonnet 4.6), Google (Gemini 3.1 Pro, 3.5 Flash), DeepSeek V4 Pro, Qwen 3.6 Plus.
Цены 1-в-1 с провайдером по курсу ЦБ — без наценки на токены. Оплата в рублях по договору, полный пакет закрывающих документов. Без VPN — легальный B2B-сервис в России.
Если статья была полезной — попробуйте Promptra: главная страница · каталог моделей · документация