Аналитик год назад построил детальную финансовую модель компании и оценил справедливую цену акции в 100 руб. Историческая точность его DCF-моделей — средняя ошибка ±10 руб.
Вчера компания опубликовала квартальный отчёт — выручка неожиданно выросла. Быстрая оценка на основе отчёта даёт новый ориентир 130 руб. Но квартальные отчёты зашумлены разовыми факторами — историческая погрешность таких оценок ±20 руб.
Какова наилучшая оценка справедливой цены акции с учётом обоих сигналов?
А) ~106 руб. Б) ~110 руб. В) ~115 руб. Г) ~120 руб.
Правильный ответ: А — ~106 руб.
Большинство выбирает Б — видимо, нужно взвешивать по точности, но неочевидно как именно. Многие выбирают Г или В: «новая информация важнее» или «возьмём среднее».
Решение
Как объединить два сигнала? Самое простое — взять среднее. Но среднее предполагает что оба источника одинаково надёжны. Это явно не так: модель ошибается на ±10 руб., отчёт — на ±20 руб. Значит источникам нужно дать разные веса — более точному больше, менее точному меньше.
Насколько больше? Пропорционально статистической надёжности источника. В статистике такой мерой служит precision — величина обратная дисперсии (1/σ²): чем меньше разброс, тем выше precision. Это математически оптимальное решение — оно минимизирует ожидаемую ошибку итоговой оценки. Именно так работает байесовское обновление при нормальном распределении ошибок.
- Вес модели: (1/σ₀²) / (1/σ₀² + 1/σ²) = (1/10²) / (1/10² + 1/20²)=
= (1/100) / (1/100 + 1/400) = 80% - Вес отчёта: 1 − 80% = 20%
- Оптимальная оценка: 80% × 100 + 20% × 130 = 80 + 26 = 106 руб.
Допущения: обе оценки несмещённые, ошибки независимы, фундаментальная стоимость компании за год существенно не изменилась.
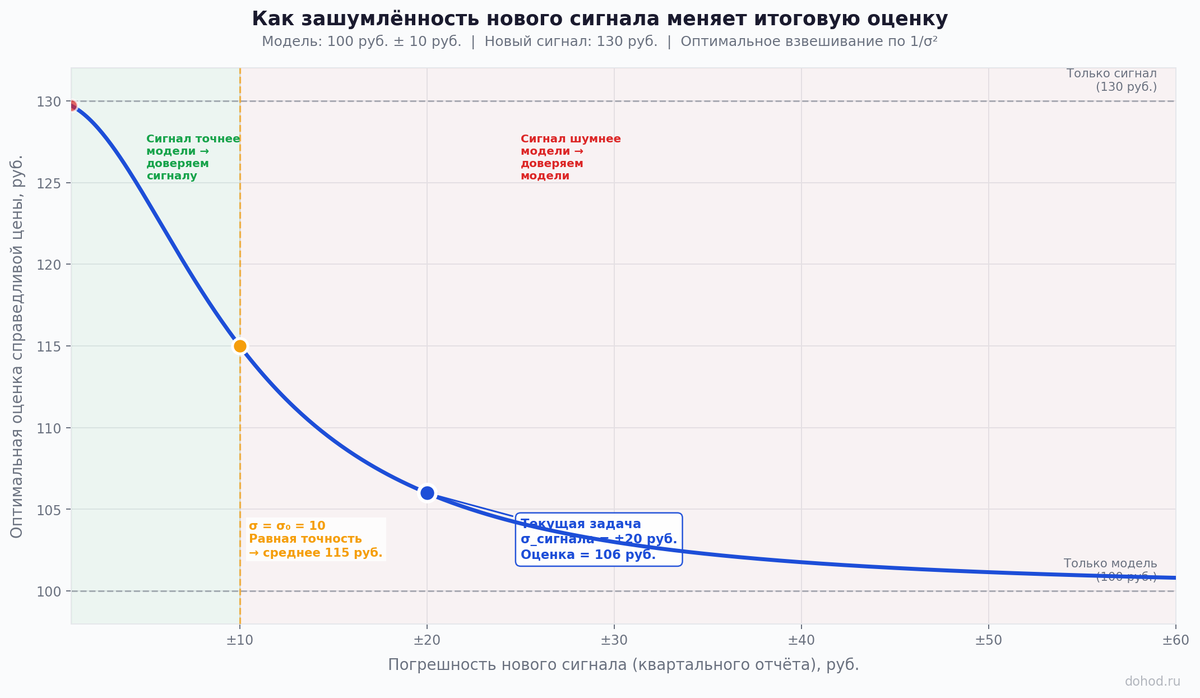
Почему не 120 руб.
Новый сигнал вдвое менее точен чем модель (±20 против ±10). Дисперсия нового сигнала в четыре раза больше — поэтому его вес в четыре раза меньше. Свежесть информации не компенсирует её зашумлённость.
Почему не 115 руб.
Простое среднее предполагает что оба источника одинаково надёжны. В нашем случае модель в два раза точнее — равные веса не являются оптимальными и приводят к большей ожидаемой ошибке оценки.
Почему не 110 руб.
Это ловушка для тех кто взвешивает по обратной ошибке (1/σ) вместо обратного квадрата ошибки — то есть обратной дисперсии (1/σ²). При таком подходе вес модели = (1/10)/(1/10+1/20) = 67%, отчёта = 33% — и оценка выходит ~110 руб. Разница кажется технической, но математически именно 1/σ² даёт оптимальный результат — потому что дисперсия аддитивна, а стандартное отклонение нет.
Что происходит после обновления информации
Два независимых источника точнее одного — потому что их статистические надёжности складываются — поэтому новая дисперсия равна 1/(1/100 + 1/400) = 80, а новая погрешность = ±8,9 руб. — лучше чем каждый источник по отдельности. Два шумных сигнала вместе точнее одного чистого.
Полезные выводы
1. Новизна ≠ надёжность
Самая свежая информация не обязательно самая ценная. Квартальный отчёт может быть зашумлён разовыми факторами, сезонностью, бухгалтерскими корректировками. Детальная модель с историей — часто точнее несмотря на время.
Правильный вопрос не «когда появился сигнал» а «насколько он точен».
2. Надёжность важнее громкости
Когда два источника дают разные оценки — не усредняйте их механически и не доверяйте автоматически тому который новее или громче. Спросите: какой из них исторически ошибается меньше?
Точному источнику нужно дать больший вес — и не просто «немного больше». Если один источник ошибается вдвое меньше — его вес не вдвое, а вчетверо больше. Потому что оптимальный вес пропорционален не обратной ошибке а обратному квадрату ошибки. Именно поэтому скромная модель с погрешностью ±10 руб. весит 80% против 20% у яркого отчёта с погрешностью ±20 руб. — хотя интуитивно кажется что разница должна быть меньше.
3. Математически похожий принцип лежит в основе нейросетей
Механизм внимания (attention) — на котором построены GPT, Gemini и другие языковые модели — использует похожую математическую форму: нормированное взвешивание сигналов.
Когда вы задаёте модели вопрос, она не читает контекст с равным вниманием ко всем словам. Каждое слово «спрашивает»: какие другие слова наиболее важны для меня прямо сейчас? Для каждой пары слов вычисляется оценка релевантности — через скалярное произведение двух векторов: «запроса» (что ищу) и «ключа» (что предлагаю). Затем оценки нормируются через softmax — превращаются в веса от 0 до 1 с суммой равной 1.
Форма та же: взвешенная сумма сигналов с нормировкой. Но критерий весов разный. В байесовском подходе вес отражает статистическую надёжность источника (1/σ²). В attention — релевантность токена для текущей задачи (QKᵀ). Именно поэтому GPT может дать огромный вес слову «не» — не потому что оно надёжнее других, а потому что оно критично для смысла.
Инвестор который взвешивает точный фундаментальный анализ выше зашумлённого отчёта реализует родственный принцип: важность определяется качеством сигнала, а не его новизной или громкостью.
4. Два шумных сигнала лучше одного точного
Парадокс: объединив модель (±10) и зашумлённый отчёт (±20) мы получаем оценку точнее исходной модели (±8,9). Каждый дополнительный независимый сигнал — даже слабый — снижает неопределённость. Именно поэтому диверсификация источников информации имеет математическое обоснование.
5. Последняя новость важнее ста предыдущих — и это ошибка
Большинство инвесторов переоценивают последнюю яркую новость и недооценивают накопленную информацию. Это recency bias — смещение в пользу недавней информации — один из самых распространённых когнитивных искажений в инвестициях. Усиливает его якорный эффект: последнее число которое видит инвестор невольно становится точкой отсчёта для всех последующих суждений. Байесовское обновление — математическая защита от обеих ловушек.
Пожалуйста, ставьте лайки, комментируйте и делитесь этой статьей, если она вам понравилась!
=========
Читайте также:
и еще десятки полезных публикаций в нашем канале Telregram и в MAX. Вот тут есть полный гид по каналу.