🔥 Kwai выпустила Keye-VL-2.0-30B-A3B
Kwai-Keye открыла веса Keye-VL-2.0-30B-A3B на Hugging Face и ModelScope. Это мультимодальная модель на 31 млрд параметров для работы с изображениями, видео, кодом, инструментами и агентными задачами.
Главный упор сделали на длинные видео. В модели используется DSA — DeepSeek Sparse Attention, за счёт чего заявлен контекст до 256K и более дешёвая обработка длинных последовательностей.
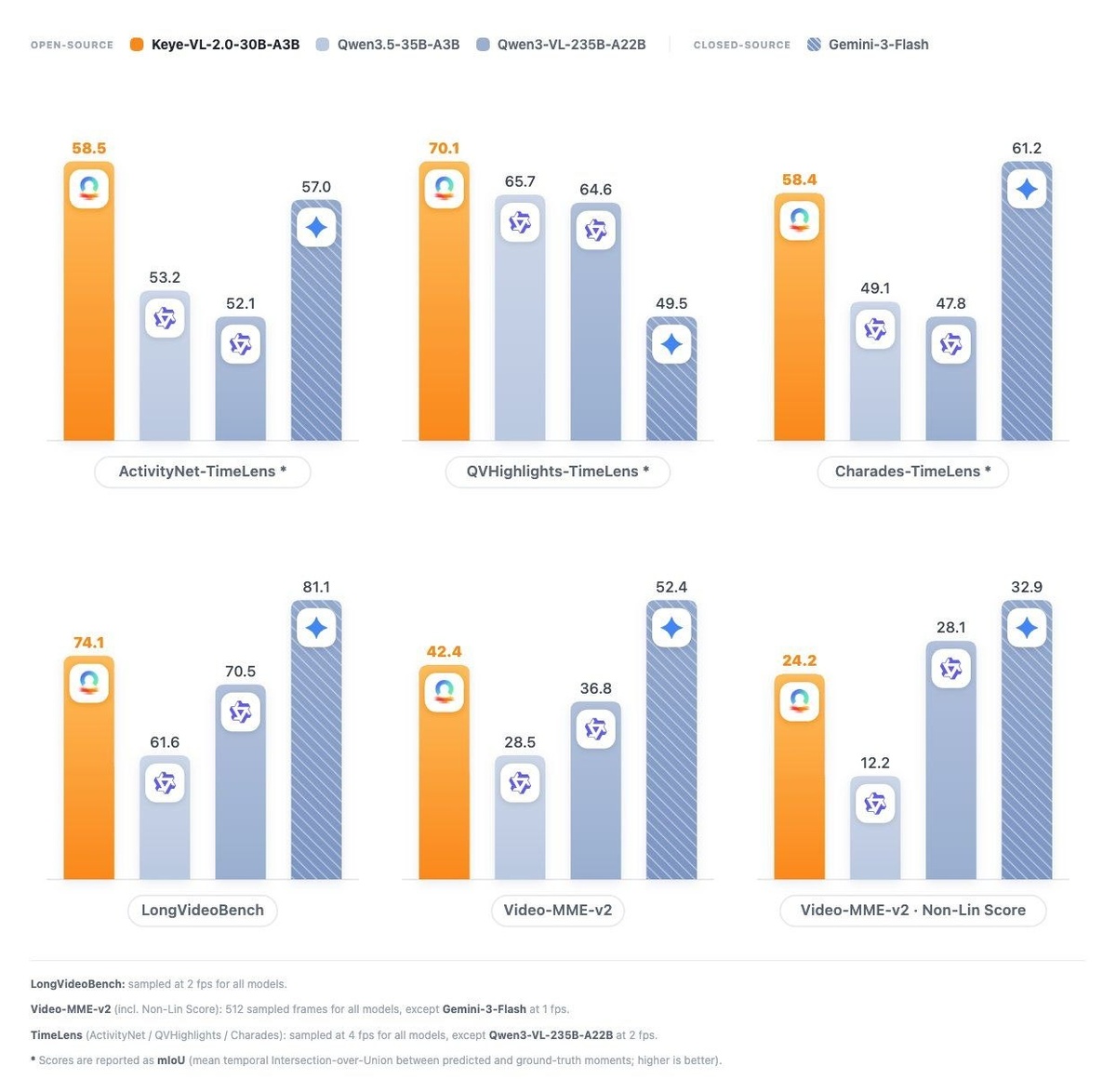
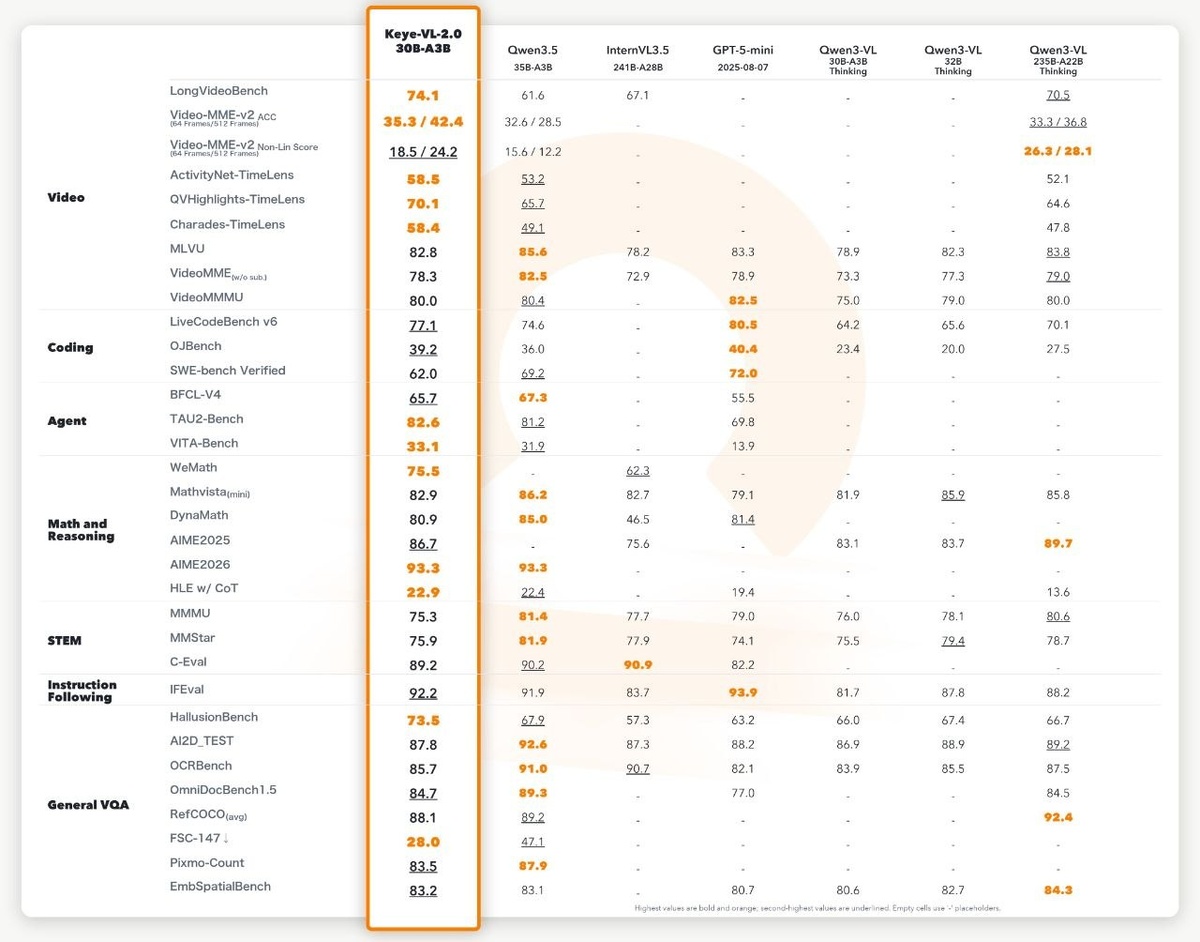
По тестам Kwai, Keye-VL-2.0-30B-A3B набрала 74.1 на LongVideoBench, 58.5 на ActivityNet-TimeLens и 70.1 на QVHighlights-TimeLens. На VideoMME-v2 точность при расширении входа с 64 до 512 кадров выросла с 35.3% до 42.4%.
Статус: веса доступны под Apache-2.0, но модель пока не развёрнута у inference-провайдеров на Hugging Face. Для запуска заявлены Transformers, vLLM, SGLang и Docker.
#AI #Kwai #KeyeVL #MultimodalAI #OpenSource #HuggingFace #VideoAI #LLM