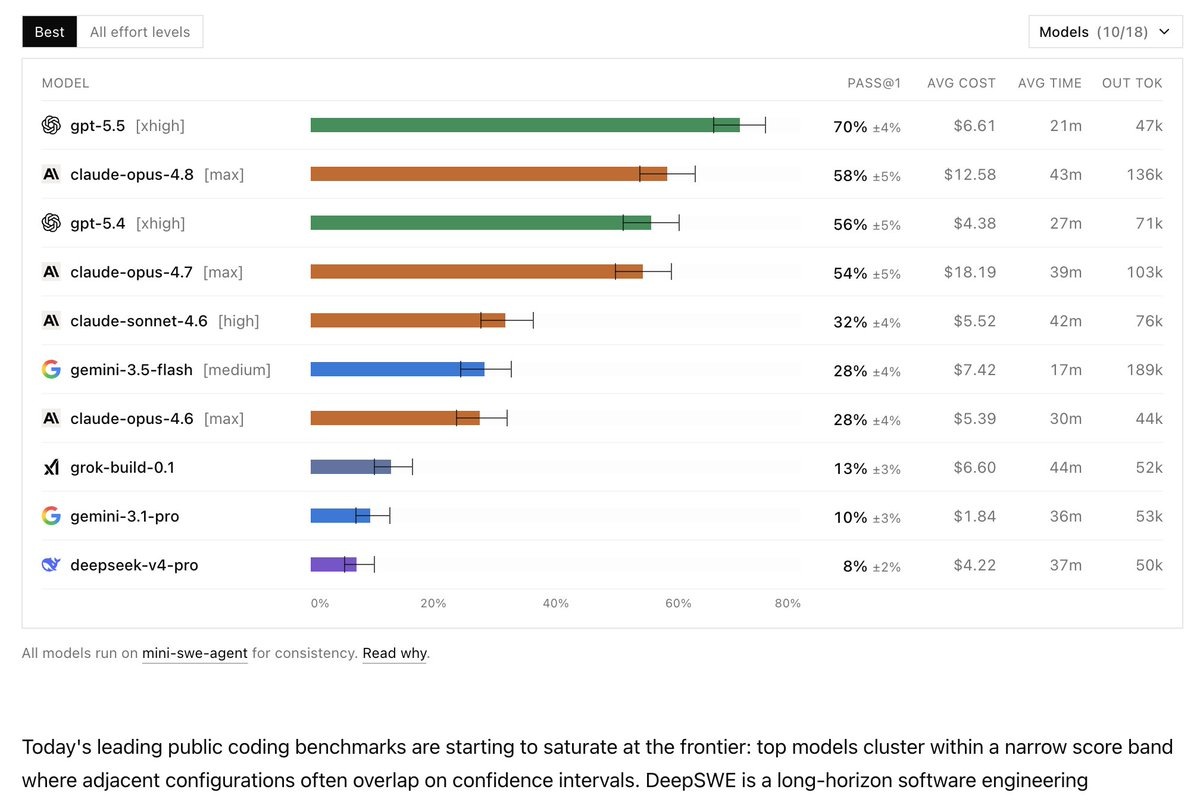
Модель GPT-5.5 заняла первое место в DeepSWE, сложном тесте на программирование с долгосрочной перспективой. Уровень успешности GPT-5.5 составил 70% при первом проходе, в то время как у Claude Opus 4.8 этот показатель равен 58%. GPT-5.5 демонстрирует примерно в два раза более быстрые результаты по сравнению с конкурентами. Стоимость использования GPT-5.5 составляет около половины от затрат на аналогичные решения. Кроме того, модель использует на треть меньше токенов для генерации выходных данных. Эти показатели свидетельствуют о более высокой эффективности GPT-5.5 в расчете на доллар, минуту и задачу. Источник @aichangelogs • @modelping • @modelping
✨ GPT-5.5 занимает первое место в DeepSWE
Модель GPT-5.5 заняла первое место в DeepSWE, сложном тесте на программирование с долгосрочной перспективой.
Уровень успешности GPT-5.5 составил 70% при первом проходе, в то время как у Claude Opus 4.8 этот показатель равен 58%.
GPT-5.5 демонстрирует примерно в два раза более быстрые результаты по сравнению с конкурентами.
Стоимость использования GPT-5.5 составляет около половины от затрат на аналогичные решения.
Кроме того, модель использует на треть меньше токенов для генерации выходных данных.
Эти показатели свидетельствуют о более высокой эффективности GPT-5.5 в расчете на доллар, минуту и задачу.
@aichangelogs • @modelping • @modelping