Большинство ИИ-агентов сливают не потому, что модель тупая. Они сливают, потому что им подсунули системный промпт в духе «ты умный помощник, отвечай хорошо». Дальше начинается театр: длинные «конечно, давайте разберёмся», выдуманные цифры, формат ответа гуляет от запроса к запросу. И всё это – не вина модели. Это вина того, кто писал промпт.
Погнали разбираться, как собрать рабочий системный промпт – по шести блокам, с примерами и проверяемыми правилами. Без магии и без «правил трёх».
Что такое системный промпт и почему он решает 80% качества
Системный промпт – это не вступительная фраза. Это конфигурационный файл агента. Модель получает его до пользовательского сообщения и держит на протяжении всей сессии.
В API OpenAI он передаётся через роль developer (раньше – system), и в документации прямо сказано: developer-сообщения приоритетнее пользовательских. То есть всё, что ты пропишешь в системе, перебивает то, что напишет юзер. У Anthropic – параметр system, у Gemini – systemInstruction. Логика одна.
Wharton Generative AI Labs в техническом отчёте «Prompt Engineering is Complicated and Contingent» показал любопытную штуку: одна и та же модель на идентичных запросах даёт разные ответы, а мелкие изменения форматирования промпта разносят точность на десятки процентных пунктов. То есть твой агент может выдавать 80% правильных ответов или 30% – и единственная разница будет в том, как ты структурировал инструкцию.
Вывод простой: если относишься к системному промпту как к «вступительному абзацу» – ты платишь качеством за лень.
Принцип правильной высоты. Главный критерий промпта
Инженеры Anthropic в гайде «Effective context engineering for AI agents» сформулировали ключевую идею: системные промпты должны быть на правильной «высоте» (altitude). Это баланс между двумя крайностями.
Делай так: начинай с минимального промпта на самой сильной модели, которая тебе доступна. Лови реальные ошибки в логах. Дописывай инструкции только под них. Не пиши абзацы «на всякий случай» – это и есть промпт-мусор, который раздувает контекст и топит важные правила.
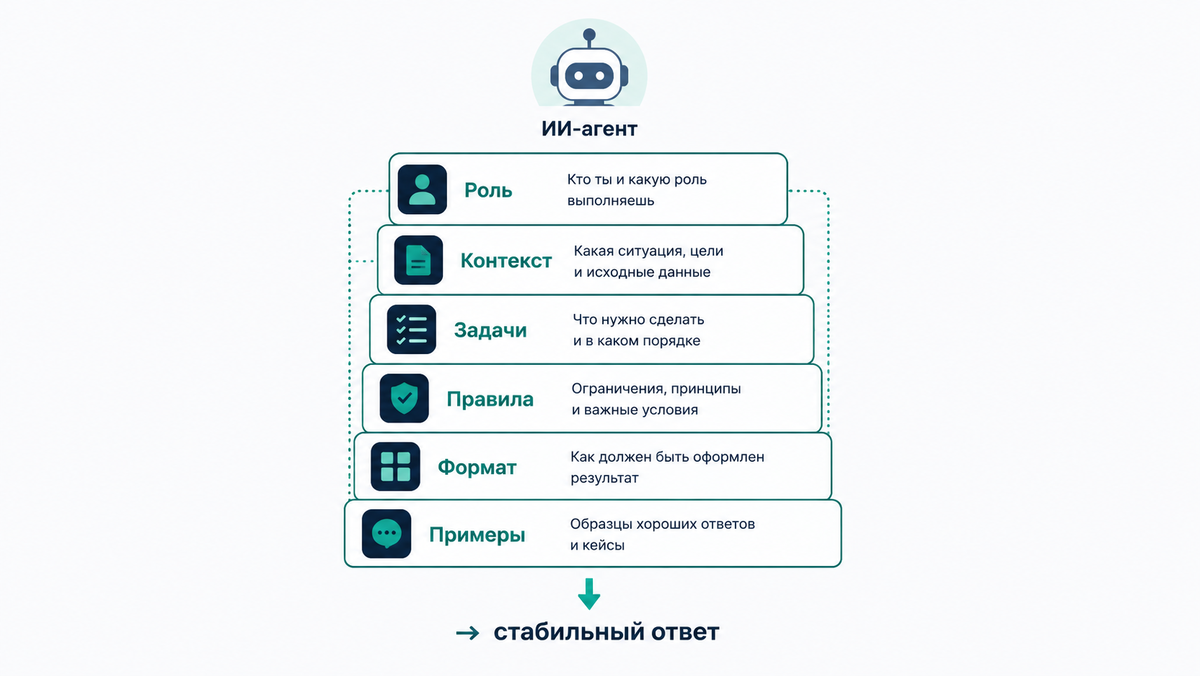
Шесть блоков рабочего системного промпта
Я разобрал публичные системные промпты Vercel v0, Claude Code, Cline, Manus и десятка других агентов. Структура везде одна. Anthropic в своём гайде даёт 10 элементов, но рабочий минимум сводится к шести блокам. Без них промпт стабильно не работает.
Блок 1. Роль и идентичность
Первая строка отвечает на вопрос «кто ты и в какой системе живёшь». У Vercel v0 это сделано буквально одной строкой: You are v0, Vercel's AI-powered assistant. Никаких метафор, никакого пафоса.
Чем уже роль – тем меньше шансов на «творчество». Сравни:
- «Ты помощник» – агент уйдёт в любые темы.
- «Ты юридический ассистент. Проверяешь договоры аренды коммерческой недвижимости в РФ. Работаешь только с предоставленным текстом» – десятки нерелевантных тем отсекаются сразу.
Делай так: домен, аудитория, явные границы. В трёх строках максимум.
Блок 2. Контекст и инструменты
Здесь описываешь среду: кто пользователь, какие у агента инструменты, какие данные доступны, на каком языке разговор. Команда Augment Code приводит пример двух строк, которые «драматически улучшили работу агента»: You are an AI assistant, with access to the developer's codebase. You can read from and write to the codebase using the provided tools.
Без описания инструментов модель либо не использует их вообще, либо галлюцинирует несуществующие функции. Видел такое сто раз: агент уверенно зовёт search_database(), которой в системе нет.
Делай так: перечисли инструменты, опиши, что они делают, укажи язык, формат входных данных и среду.
Блок 3. Задачи и алгоритм
Это блок «делай так, по шагам». Не пиши сплошным текстом «помогай пользователю решать его задачи». Это бесполезно.
Дай нумерованный алгоритм:
- Уточни цель пользователя одним вопросом.
- Предложи план из 3–5 пунктов.
- Жди явного подтверждения. Без подтверждения – не действуй.
- Выполняй по плану.
- После каждого шага – короткий статус.
У Cline это сделано в виде двух режимов – Plan и Act. В Plan-режиме агент собирает контекст и предлагает стратегию. В Act – исполняет. По данным самих разработчиков Cline, такое разделение режимов резко снижает количество мусорных правок: модель сначала фиксирует план, а потом его реализует, а не «думает руками».
Блок 4. Формат вывода
Если формат важен – он должен быть указан явно. JSON со схемой, маркдаун с заголовками H2/H3, таблица из трёх колонок, ответ не длиннее 200 слов. Microsoft в гайде по системным сообщениям для Azure OpenAI прямо говорит: скрытые требования к формату – типичная причина того, что вывод «плывёт».
Делай так:
- Опиши формат словами.
- Покажи один пример идеального вывода.
- Размести этот блок ближе к концу промпта. Anthropic подтверждает: модель лучше «помнит» инструкции по формату, когда они стоят рядом с моментом генерации.
Блок 5. Ограничения и guardrails
Это правила того, что агент не делает. Запреты, формулы отказа, поведение при недостатке данных.
У Vercel v0 явно прописана единая формула отказа и запрет извиняться и объяснять отказ. Никаких «к сожалению, я не могу помочь, потому что…». Сухо: «Sorry, I can't help with that.» Точка. Это убирает «творческие» отказы, которые путают пользователей.
Что должно быть в этом блоке:
- Запретные темы и действия.
- Чёткая формула отказа.
- Поведение при отсутствии данных («если данных нет – отвечай: «Недостаточно данных, нужны поля: …»»).
- На каждое «не делай» – одна формулировка «вместо этого делай». Иначе агент парализуется отказами.
Блок 6. Few-shot примеры
Один-два эталонных диалога «запрос – правильный ответ» работают лучше, чем тридцать строк правил. Anthropic в инженерном блоге называет примеры «картинками, которые стоят тысячи слов».
Но есть и другая крайность – «прачечный список» из 30 edge-cases. Рабочее правило:
- 2–4 канонических примера разной природы.
- Один пример – обязательно с ответом «недостаточно данных, не могу ответить». Это самый недооценённый приём против галлюцинаций.
- Не пиши примеры в виде «вот хороший ответ» и «вот плохой ответ» в одном блоке. Модель путается, какой именно подражать.
Слабый и сильный промпт. Один кейс
Возьмём задачу: агент помогает руководителю отдела продаж готовить отчёты по сделкам из CRM.
Слабый промпт:
«Ты – умный ассистент по продажам. Помогай готовить отчёты, отвечай профессионально и подробно.»
Что здесь сломано:
- Нет роли с границами.
- Нет описания данных.
- Нет формата вывода.
- Нет правил при отсутствии полей.
- Нет языка ответа.
Что получишь на выходе: лотерею. Иногда длинный отчёт, иногда коротенький список, иногда выдуманные цифры, иногда английский вместо русского.
Сильный промпт по шести блокам:
Ты ассистент руководителя отдела продаж B2B SaaS-компании. Работаешь только с данными, которые пользователь явно приложил в сообщении или загрузил файлом. Язык ответов – русский.Задача: по запросу формировать отчёт о сделках за период.Алгоритм:определи период и сегмент;
проверь, есть ли в данных поля «сумма», «этап», «дата», «ответственный»;
если какого-то поля нет – задай один уточняющий вопрос и остановись;
собери отчёт.
Формат: маркдаун. Разделы «Итоги», «Топ-5 сделок», «Риски», «Следующие шаги». Не больше 400 слов.Запрещено: придумывать суммы, ФИО и даты, которых нет в исходных данных; давать прогнозы без явной пометки «гипотеза».Если данных не хватает – отвечай: «Недостаточно данных для отчёта, нужны поля: …»
Разница не в длине. Разница в проверяемости каждой строки: для любого пункта понятно, как протестировать его выполнение.
Семь типичных ошибок при написании системного промпта
Wharton отдельно бьёт по слабому месту индустрии: переоценивать однократный «удачный прогон» нельзя. Нужны повторные тесты на десятках запросов. Вариативность модели маскирует реальную надёжность инструкции – и ты можешь думать, что промпт рабочий, пока он не сломается в проде на пользователях.
Структурная разметка. XML, заголовки, иерархия
Для длинных промптов важна не только формулировка, но и разметка. Anthropic в документации прямо рекомендует оборачивать разные типы содержимого в XML-теги: <instructions>, <context>, <examples>, <input>. Это уменьшает шанс, что модель перепутает инструкцию с данными.
Для моделей OpenAI лучше заходят маркдаун-заголовки и нумерация. У Gemini – свои нюансы. Но идея общая: ставь жёсткие визуальные границы между смысловыми блоками.
Рабочая иерархия:
- Идентичность и роль (1–3 строки).
- Контекст и инструменты (что доступно, на каком языке, какие данные).
- Алгоритм действий (пронумерованные шаги).
- Правила и ограничения (что запрещено, как отказывать).
- Формат вывода (с примером).
- Few-shot примеры (2–4 канонических пары).
- Финальное напоминание (повтор 2–3 самых критичных правил в конце).
Приём с «напоминаниями в конце» (например: «Отвечай только если уверен. Не выдумывай данных, которых нет во входе») работает потому, что когда контекст заполняется, модель сильнее опирается на последние инструкции. Это не магия, это особенность того, как трансформеры распределяют внимание.
Чек-лист перед запуском агента в прод
Пройдись перед выкаткой:
- Роль агента сформулирована в 1–2 предложениях. Указан домен и границы.
- Описаны доступные инструменты и данные.
- Алгоритм действий разбит на шаги.
- Указан язык, формат и максимальная длина ответа.
- Есть формула отказа и поведение при недостатке данных.
- Дан хотя бы один few-shot пример эталонного диалога.
- Нет противоречивых инструкций (проверка попарно).
- Промпт прогнан минимум на 20 реальных запросах.
- Прогнан на 5 adversarial-запросах (попытки сбить роль, инъекции).
- Самые критичные правила продублированы в конце.
- Версия промпта зафиксирована (Git или система управления промптами).
Если хотя бы один пункт не закрыт – это потенциальный источник нестабильного поведения. Не выкатывай.
Если хочешь готовые системные промпты, которые можно сразу засунуть в работу – забирай бесплатный курс «СОЗИДАЙ».