Один длинный промпт не вытянет сложную задачу. Цепочка из 5–6 агентов – вытянет.
Anthropic замерила: связка Opus 4 + Sonnet 4 обходит одиночный Opus 4 на 90,2% на исследовательских задачах. Корнелльское исследование на бенчмарке TravelPlanner: координированные мульти-агенты дают 42,68% успеха, одиночный GPT-4 – 2,92%. Разрыв в 14 раз.
Секрет не в магии, а в обвязке: роли, контракты, изоляция контекста. Дальше – как это устроено и как собрать первую цепочку.
Где ломается «один большой промпт»
Знакомая сцена. Ты пишешь промпт на 2 000 слов: «будь исследователем, аналитиком, копирайтером, редактором, проверь факты, не забудь SEO, в конце добавь FAQ». Модель кивает и выдаёт усреднённую кашу.
Так оно и работает. Один промпт = один проход = один контекст. На простом вопросе – ок. На задаче из 5–7 шагов – модель теряет начальные требования под промежуточными результатами.
Команда Manus (которую забрала Meta) зафиксировала цифру: в реальной агентной работе модель делает в среднем около 50 вызовов инструментов. Инструкции из начала сессии «утопают» даже в больших контекстных окнах.
Вот где ломается одиночный промпт:
- Контекст переполняется. Чем длиннее проход – тем выше шанс, что модель забыла про начальные требования.
- Нет верификации. Один проход – одна попытка. Ошиблась на втором шаге рассуждения – ошибка уезжает в финал.
- Роли смешиваются. «Исследователь» и «редактор» думают по-разному. Когда обе персоны в одном промпте – модель усредняет их и теряет глубину обеих.
Цифры на сложных задачах планирования (Cornell, TravelPlanner, arXiv 2405.16510): одиночный GPT-4 даёт 2,92%, координированная мульти-агентная связка – 42,68%. Это не «чуть лучше», это другая лига.
Что такое цепочка агентов, если без воды
Цепочка ИИ-агентов (агентный пайплайн) – это конвейер из нескольких LLM-агентов, где выход одного шага становится входом следующего.
Каждый агент:
- имеет свой системный промпт и одну роль,
- видит только нужный фрагмент данных,
- отвечает за один измеримый результат,
- работает со своим набором инструментов.
IBM в документации по LangChain формулирует это так: «prompt chaining связывает несколько промптов в логическую последовательность, где выход одного служит входом следующего». То есть это не «длинный диалог», а спроектированный конвейер с чёткими стыками.
Аналогия простая. Сборочная линия вместо одного «универсала». Универсал делает всё подряд и устаёт. Линия делает каждый шаг быстро и точно, потому что специалист занят только своей операцией.
Анатомия пайплайна: 5 элементов, без которых это не цепочка
Любая рабочая связка стоит на пяти конструктивных элементах. Без любого из них «цепочка» превращается в хаотичный чат с галлюцинациями.
- Роли. Один агент = одна специализация. Исследователь, аналитик, стратег, копирайтер, редактор, контролёр. Если двое делают похожее – оркестратор не понимает, кому отдать данные.
- Системные промпты. Отдельная инструкция под каждый агент: что делает, чего не делает, в каком формате отдаёт результат.
- Контракт передачи. Жёстко зафиксированный формат «выход → вход». Обычно JSON, Markdown с фиксированной структурой или нумерованные блоки. Свободный текст на стыках – путь к развалу.
- Инструменты. Веб-поиск – у исследователя. База знаний – у аналитика. Шаблоны – у форматтера. Разделение прав снижает шум и стоимость.
- Оркестратор. Управляющий слой: запускает агентов по порядку, передаёт данные, ловит ошибки. В CrewAI и MetaGPT это паттерн Orchestrator/Gatekeeper, в LangGraph – граф состояний.
Не усложняй. Сначала контракты, потом промпты, потом запуск. Не наоборот.
Sequential chaining: как реально передавать данные между агентами
Sequential chaining – самая частая схема. Шаги линейны, каждый принимает результат предыдущего и обогащает его.
Возьмём обработку клиентского письма – классический пример из практики LangChain-команд:
- Шаг 1. Агент-аналитик читает письмо, вытаскивает структуру: проблема, тон, срочность.
- Шаг 2. Агент-композитор пишет черновик ответа по структурированному входу.
- Шаг 3. Агент-редактор проверяет тон, факты, уместность.
Один промпт «ответь клиенту» эту задачу делает хуже. Цепочка даёт стабильный результат, потому что каждый агент сфокусирован на одной подзадаче. Никакой магии, чистая дисциплина.
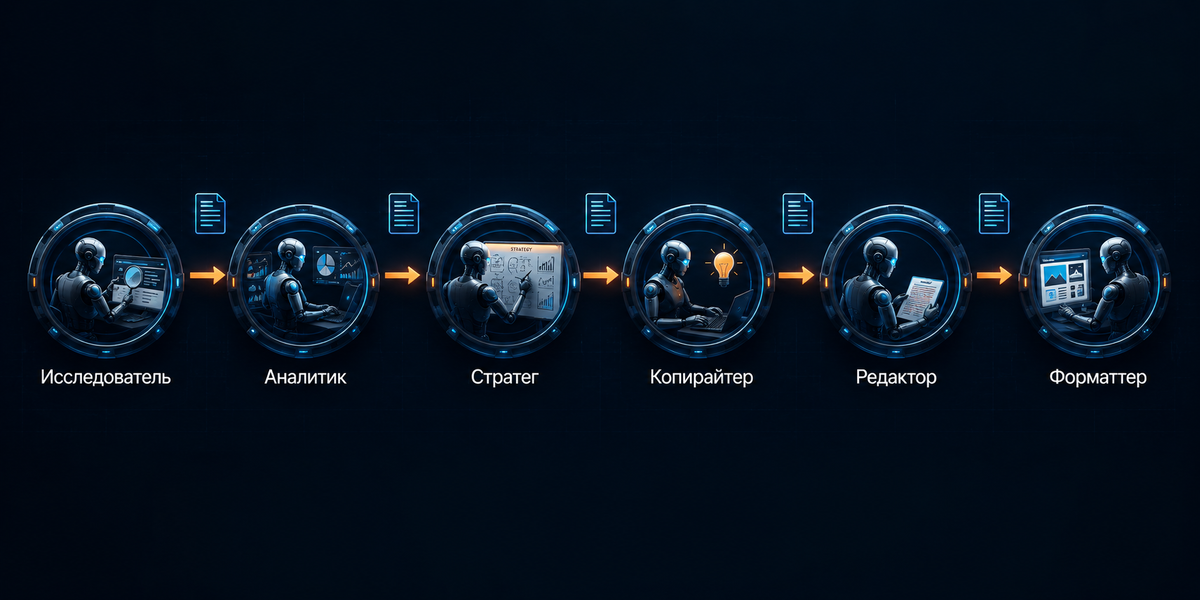
Конкретный пример: 6 агентов на задаче «лонгрид под запуск»
Покажу на типовой задаче. Запрос – «напиши лонгрид к запуску продукта». Один промпт даёт усреднённый текст «для всех». Цепочка из шести агентов даёт публикационный материал.
- Исследователь. Собирает источники, цифры, цитаты, ключевые тезисы. На выходе – пул фактов в JSON.
- Аналитик. Ранжирует тезисы по силе, выкидывает дубли, размечает приоритеты. На выходе – приоритизированное ядро.
- Стратег. Проектирует структуру: заголовок, TL;DR, последовательность H2, угол подачи. На выходе – план статьи.
- Копирайтер. Пишет текст по утверждённому плану, используя факты из шага 1. На выходе – черновик.
- Редактор. Чинит логику, ритм, длину предложений. Режет мусор. На выходе – чистовик.
- Форматтер/SEO. Расставляет H2/H3, списки, мета-данные, проверяет ключи и читаемость. На выходе – готовая публикация.
В чём сила? Ошибка пятого агента не съест работу первого, потому что данные уже зафиксированы на каждом стыке. Это и есть агентный пайплайн – тот принцип, на котором у меня в СОЗИДАЙ собраны связки под контент и аналитику.
Почему пайплайн объективно сильнее одного промпта
Превосходство мульти-агентов – не маркетинг, а измеренный факт. Anthropic в материале «How we built our multi-agent research system» прямо пишет: связка Claude Opus 4 (лидер) + Claude Sonnet 4 (саб-агенты) обогнала одиночный Opus 4 на 90,2% на внутреннем бенчмарке исследовательских задач.
Откуда такой скачок:
- Изоляция контекста. Каждый агент видит только нужный вход. Модель не «забывает» инструкции под потоком промежуточных данных.
- Параллелизм по природе задачи. Исследовательские запросы разбиваются на независимые подвопросы. Саб-агенты решают их одновременно, а не последовательно. Одиночный агент делает то же самое долго и в одну колонну.
- Критика «другим взглядом». Один агент проверяет работу другого. Это ловит класс ошибок, которые модель никогда не заметит в самопроверке.
- Специализированные промпты. Промпт исследователя и промпт редактора несовместимы по тону и логике. В цепочке каждый промпт оптимален под свой шаг.
Manus формулирует своё правило коротко: reduce, offload, isolate. Уменьшить контекст агента, вынести тяжёлое в саб-агентов, вернуть в основную ветку сжатый итог. Хорошее правило, забирай.
Когда цепочка избыточна, а когда без неё никак
Не каждая задача требует пайплайна. Microsoft в Cloud Adoption Framework пишет в лоб: начинай с одного агента, переходи к мульти-агентной архитектуре только тогда, когда тесты показали устойчивую деградацию точности или латентности.
Одного агента хватит, если:
- задача линейна и помещается в один проход,
- нет независимых подзадач для параллели,
- результат не требует проверки «вторым лицом»,
- данных мало, контекст не переполняется.
Цепочка нужна, если:
- задача разбивается на 3+ независимых шага,
- надо собрать факты из множества источников,
- нужен контроль качества «другим взглядом»,
- одиночный промпт даёт нестабильный результат при повторных запусках,
- задача регулярная и масштабируется – поточный контент, обработка обращений, аналитика.
Правило простое: если ты трижды переписал один промпт и всё ещё «не то» – задаче нужна цепочка, а не четвёртая попытка.
5 типичных провалов при сборке цепочки
Anthropic честно перечислили свои ранние ошибки: агенты порождали по 50 саб-агентов на простой запрос, искали несуществующие источники, отвлекали друг друга избыточными апдейтами. Из их отчёта и практики LangChain-команд выкристаллизовались типичные провалы.
- Размытые роли. Два агента делают похожее – оркестратор не понимает, кому передавать данные. Лечится строгим описанием зоны ответственности.
- Свободный формат стыков. Агент отдаёт текст в произвольной форме – следующий «дочитывает» его и теряет фокус. JSON или фиксированный Markdown – не каприз, а гигиена.
- Избыточная длина цепочки. Семь агентов там, где хватает трёх. Растёт стоимость, латентность и риск ошибки на каждом шаге.
- Нет финальной проверки. Цепочка без QA-агента отдаёт первый попавшийся результат как итог. Дешёвый и больной баг.
- Игнор стоимости. Каждый агент = дополнительные токены. Без бюджета цепочка из 6 шагов на топовых моделях может стоить в 5–10 раз дороже одного запроса.
Лечится это проектированием «сверху вниз»: сначала контракт между агентами, потом промпты, потом запуск.
Как собрать первую цепочку: алгоритм без боли
Минимальный путь – взять рабочую цепочку, разобрать её по шагам и адаптировать под свою задачу. Это короче, чем строить с нуля и натыкаться на ошибки, которые отрасль уже описала.
Делай так:
- Опиши конечный результат. Не «помоги с контентом», а «лонгрид 2 000 слов с FAQ и мета-данными».
- Разбей на 3–6 шагов. Меньше – не хватит специализации, больше – избыточность и переплата.
- Зафиксируй формат передачи между шагами. Markdown-структура или JSON. Без свободного текста на стыках.
- Напиши системный промпт для каждого агента – отдельно, проверяемо, без «и ещё ты редактор».
- Прогони цепочку на 3 разных входах. Если результат стабильный – цепочка рабочая. Нестабильный – чини контракты, не промпты.
Если хочешь увидеть готовую цепочку из шести агентов в действии – её механика разобрана в бесплатном курсе «6 готовых ИИ-агентов» от СОЗИДАЙ.