История разработчика, который каждый день пишет код, ловит баги и общается с ИИ 😁

Привет 👋 Меня зовут Дима, 9 лет в бэкенде, сейчас я Senior Backend в продуктовой компании + пара пет-проектов на фрилансе. Не блогер, не IT-евангелист, просто человек, который пишет код 6 дней в неделю.
Расскажу, как я перестроил свой workflow с ИИ, без «нейросети заменят джунов», без «топ-10 промптов, которые взорвут вашу продуктивность» и прочего.
Две вещи, которые реально достали
1. ИИ выдаёт устаревший код. Стандартная история: подтягиваю свежую библиотеку, спрашиваю ChatGPT — он выдаёт красивый код, который падает с ошибкой, потому что в новой версии этот метод выпилили полгода назад.
Час-два уходит на то, чтобы перепроверить каждую строчку, открыть GitHub, найти актуальный док и понять, что поменялось.
2. Копипаст рабочего кода в чужие облака. У нас в компании NDA, серьёзные клиенты и чувствительные данные. Когда я копирую кусок кода для разбора в ChatGPT, бывает, что в голове щёлкает: «А это вообще законно?»)))
Например, согласно политике OpenAI запросы хранятся минимум 30 дней. Я не параноик и понимаю, что мой кусок воркера никому не нужен. Но «никто не будет читать» и «технически невозможно прочитать» — это две разные вещи. Особенно когда речь про прод-код, в котором мелькают названия внутренних сервисов и схем БД.
Что я пробовал до того, как нашёл нормальное решение?
Последние полгода я тестил всё подряд:
🔸 GitHub Copilot — хорош в IDE, но у нас в компании он не подключён
🔸 Локальная LLM (Ollama + DeepSeek Coder) — работает, но довольно медленно, актуальные issue тоже не подтягивает
🔸 Perplexity — хорош для ресерча, но платить из РФ — это отдельный геморрой
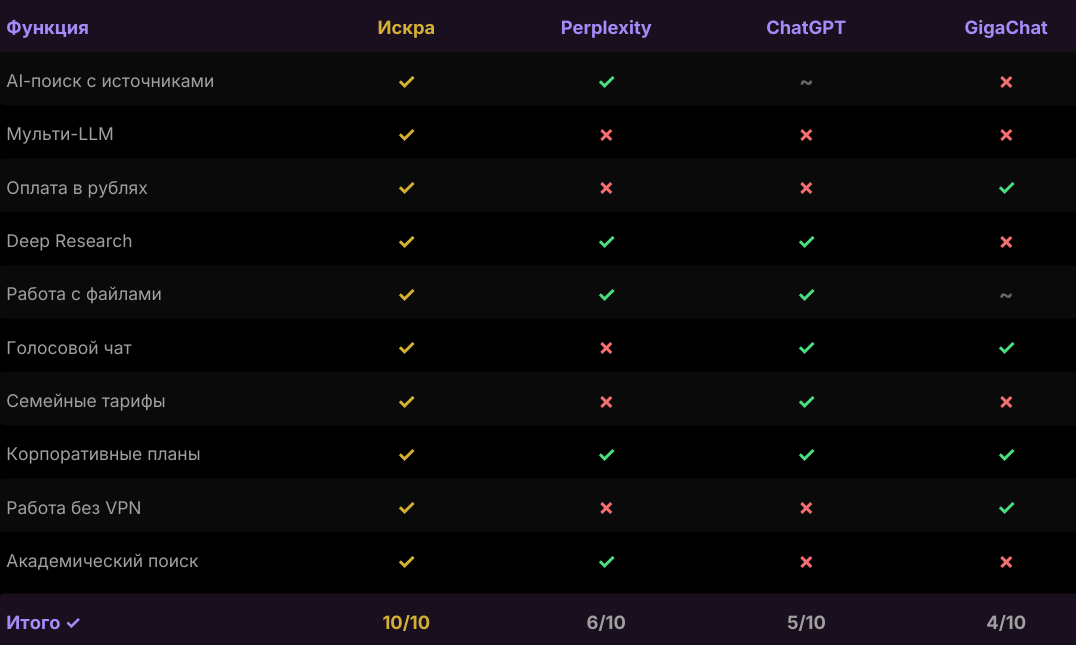
Знакомство с Искрой
Знакомый из соседней команды недели две назад затащил меня в Искру. Я зашёл скептиком — за последние пару лет навидался «российских аналогов чего-то», и почти все оказывались сырыми клонами без идеи. Но тут зацепило не интерфейсом (он минималистичный и без вау-эффектов), а тем, как у них устроена приватность.
🔍 Объясню как понял:
1. Между мной и LLM стоит «слой Искры». Когда я пишу запрос, он сначала идёт на серверы Искры. И только потом — в Claude, GPT, Gemini или другие модели. Причём в LLM уходит только обезличенный текст моего запроса. А вот мой email, IP, ID, история других чатов — не уходит никуда.
2. Чаты в базе зашифрованы. Расшифровать их можно только моим ключом сессии — то есть когда я сам залогинен. Без меня в базе лежит набор байтов.
3. Есть режим инкогнито. Включаешь — и история не пишется вообще нигде. Ни на сервере, ни локально. Это для случаев «вообще не хочу следов». Я в этом режиме работаю с рабочим кодом по умолчанию.
4 кейса из реальной работы
🔧 Кейс 1: Плавающий баг, который я ловил неделю
У нас был баг: воркер периодически падал с RuntimeError: Event loop is closed. Локально не воспроизводился. ChatGPT (когда ещё пользовался) выдавал общие советы из 2024 года.
Включаю в Искре режим инкогнито и собираю нормальный контекст для запроса — это, кстати, главное, что отличает «ИИ ответил по делу» от «ИИ галлюцинировал». Дал: кусок воркера, полный traceback из логов (~30 строк) и версии всех зависимостей по интересующим пакетам.
Закидываю промпт:
В асинхронном воркере (Python 3.11, FastAPI, asyncpg) периодически валится RuntimeError: Event loop is closed при graceful shutdown. Найди свежие issue в GitHub за последние 6 месяцев по этой проблеме. Дай прямые ссылки. Если есть workaround — опиши с примером кода.
Получаю свежий issue, открытый месяц назад, с обсуждением мейнтейнеров и рабочим workaround. На неделе наблюдал в проде, за 200+ рестартов — ни одного падения.
🔧 Кейс 2: Не парюсь из-за внутренних имён в трейсах
Часто в стектрейсах у нас всплывают внутренние названия модулей, которые не хочется светить. Раньше я заменял их на абстрактные module_a / module_b, потом обратно — теряется контекст, ИИ хуже понимает суть.
Сейчас просто кидаю стектрейс как есть в инкогнито. Сколько часов в месяц это экономит — точно не считал, но субъективно «обфускация трейсов» как задача исчезла из моей рутины полностью.
🔧 Кейс 3: Свежие гайды и доки
Искра ходит в веб прямо сейчас и приносит живые ссылки. Это решает главную боль других ИИ с их устаревшими данными.
Промпт наподобие:
Какие сейчас рекомендуемые подходы для миграции с SQLAlchemy 1.4 на 2.0 в больших проектах? Нужны:
- свежие гайды (не старше 6 месяцев);
- известные подводные камни;
- ссылки на официальную доку.
И мне приходит свежая информация, которую руками я бы искал часа 2-3.
🔧 Кейс 4: Архитектурный «спарринг»
Иногда нужен второй мозг по архитектурному решению. С коллегами обсудить — не всегда вариант (NDA на проект, или просто никто не свободен), на StackOverflow такое не вынесешь.
В Искре есть штука, которую они называют «агенты» — по сути, заранее настроенные системные промпты под роль. Есть «Программист», «Аналитик данных» и другие. Не надо в начале каждого чата писать «представь, что ты Senior с 15-летним опытом» — агент уже в роли, и отвечает в стиле архитектурного ревью.
Пишу:
Выбираю между Redis + Celery и RabbitMQ для очереди задач с приоритетами. Нагрузка ~50k задач/час, латентность критична для топ-приоритета (<100мс). Что надёжнее под мои условия? Дай аргументы и ссылки на бенчмарки.
И получаю развернутый ответ со ссылками. Не как «истину в последней инстанции», но как отличного спарринг-партнёра.
5 промптов, которые гоняю постоянно
Делюсь тем, что работает с любым ИИ:
🔥 Промпт №1. Разбор stacktrace
Вот мой stacktrace: [вставить]
Задача:
1. Определи root cause (не симптом).
2. Объясни, почему эта ошибка возникает.
3. Дай минимальный воспроизводимый пример.
4. Предложи 2-3 варианта исправления.
5. Приложи ссылки на актуальные issues / документацию.
🔥 Промпт №2. Обновление библиотеки
Я использую [библиотека] версии [X]. Хочу обновиться до последней. Дай:
1. Список breaking changes.
2. Code-snippets «было / стало» для критичных изменений.
3. Известные баги в новой версии.
4. Ссылку на официальный migration guide.
🔥 Промпт №3. Сравнение библиотек
Мне нужно решить задачу: [описание].
Условия: [нагрузка, стек, ограничения].
Сравни 3-4 актуальные библиотеки. Для каждой:
- пример кода под мой стек;
- плюсы/минусы под мою задачу;
- статус мейнтейнинга;
- ссылки на доку.
В конце — рекомендуй один вариант с обоснованием.
🔥 Промпт №4. Архитектурная критика
Я планирую: [описание решения].
Будь критичным архитектором-ревьюером. Найди:
1. Технические риски.
2. Что плохо масштабируется или сложно поддерживать.
3. Альтернативы, которые я мог упустить.
Не будь вежливым. Если решение плохое — скажи прямо.
🔥 Промпт №5. Разбор непонятного поведения
Вот код: [код]
Поведение, которое не понимаю: [описание]
Что я ожидал: [описание]
Объясни:
1. Почему код ведёт себя именно так (со ссылками на спецификацию).
2. Какой механизм языка/библиотеки за это отвечает.
3. Как это исправить.
Что в итоге?
Через полгода я пришёл к такой схеме, делюсь:
Я не предлагаю никому менять весь workflow. Если у вас всё работает — окей. Но если вы ищете адекватный способ работать с нейросетями из РФ без VPN — попробуйте 😉
У Искры есть бесплатный пробный период — возьмите любой из 5 промптов выше, прогоните в Искре и в ChatGPT. Сравните актуальность ссылок, как минимум) Я именно так и проверял.
Ссылка: iskra-ai.tech
Пишите в комментарии свои вопросы, особенно интересно мнение тех, кто работает с чувствительными данными (банки, финтех, медицина) 👇