
Когда речь заходит об AI-проектах, то чаще всего главным героем всей истории называют именно модель. Но ведь самое важное – это не архитектуры или нейросети, а сам процесс обучения данных. В этой статье подробно разберем, как это происходит и от каких нюансов зависит.
Разметка данных – ключевой момент, благодаря которому вообще работает система машинного обучения. И если уже на этом этапе корректно наладить все процессы, то получится избежать ошибок уже на начальной стадии и добиться успеха.
Что такое разметка в контексте AI
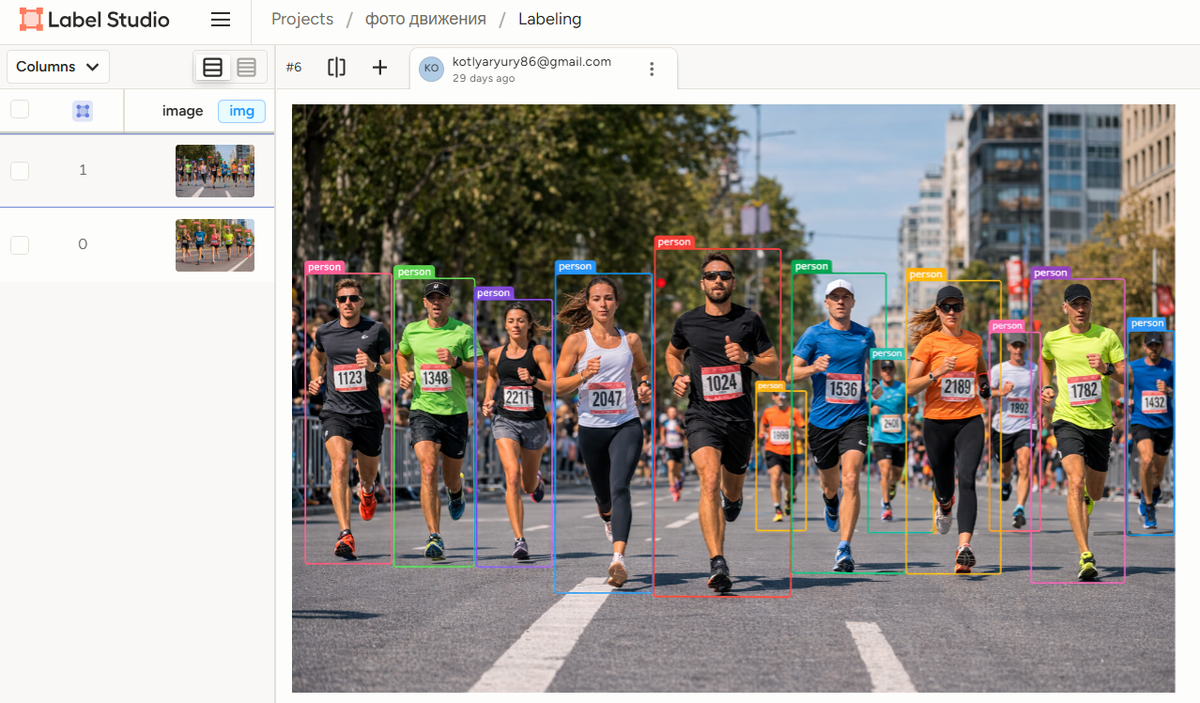
Разметка – процесс обучения модели, при котором данным добавляются метки, тэги или аннотации. Этот этап критически важен для алгоритмов машинного обучения. Ведь именно здесь модель учится принимать решения и понимать информацию.
В зависимости от типа задачи бывают следующие виды разметки:
● Классификация. В этом случае каждому объекту присваивается один или несколько классов.
● Object detection (обнаружение объектов) с помощью bounding boxes (ограничивающих рамок). Основная цель – не только отметить объект, но и определить его местоположение и обвести рамками.
● Сегментация или pixel-level разметка. Более точная разметка, где каждый пиксель относится к определенному объекту или фону.
● Keypoints и landmarks. Другими словами – ключевые точки и ориентиры. В этом случае отмечаются ключевые точки на объекте.
● Текстовая разметка. Здесь работа ведется в тексте различными форматами, например:
- NER или распознавание сущностей, при котором технология находит в тексте и классифицирует объекты – имена, города, компании или даты. В итоге рандомный текст превращается в структурные данные.
- Sentiment или анализ тональности, благодаря которому AI может определить настроение текста и с какими эмоциями он был написан. Например, под каким настроением был написан комментарий в соцсети – позитивным или негативным, а может нейтральным.
- Intent – в этом случае искусственный интеллект способен определить намерение или цель пользователя, когда он пишет боту или в поисковой запрос вне зависимости от формулировки.
В результате изначальные данные постепенно превращаются в датасет. Принцип работы не меняется даже от вида разметки, так как самое главное – это полученный результат.
Почему качественная разметка так важна для работы модели
Любая ML-модель обучается на примерах, которые и являются гарантией отличного результата в будущем. И если подобранные материалы размечены с ошибками, предоставляют противоречивую информацию или имеют недостоверные или неполные данные, то модель также будет выдавать некорректные сведения.
Например, при реальных проблемах в данных модель начнет работать хуже: точность снизится, результы при проверку постоянно будут разными, а на реальных данных качество будет сильно хуже. Ведь в процессе работы данные могут заметно отличаться от тех, на которых модель обучалась.
Важно понимать, что модель не умеет сама исправлять ошибки или как-то корректировать данные. Она просто масштабирует и обрабатывает то, что ей дается. И изначально плохие вводные могут привести к неожиданному результату.
ТОП-5 проблем в разметке
Можно выделить целый пласт нюансов, которые встречаются в процессе разметки. Но есть проблемы, которые возникают чаще всего. На них стоит обратить максимальное внимание:
- Неконсистентность, когда различные аннотаторы распознают правила по-разному. Например, в этом случае объект может быть включен в нужный класс, а другой быть распределен в противоположный. В результате датасет получается неоднородным.
- Субъективность. Если не установлены конкретные критерии под определенные задачи, то разметка зависит от человека. Любая ошибка может стоить дорого, особенно в таких задачах, как классификация изображений и NLP (тональность, intent).
- Ошибки и шум – еще одна часто встречающаяся проблема. Даже при хорошей подготовке и корректных инструкциях аннотаторы устают и ошибаются, пропускают объекты, хоть и случайно. Это в итоге ухудшает обучение и создает label noise.
- Нехватка данных, когда все сценарии не отработаны. Чаще всего это встречается, если редкий случай и сложные условия. Тогда модель просто не может правильно обобщать информацию.
Дешево и быстро — это не про качественную разметку
Разметка почти полностью проводится в ручную, а это огромное количество часов работы. Да, конечно, существуют специальные инструменты, типа CVAT. Но даже тогда каждый объект требует внимания человека.
Также происходит и со сложными типами разметки. В любом случае они занимают большое количество времени, а контроль качества заметно увеличивает затраты на проспект. И при масштабировании проекта или переделках стоимость повышается.
Ошибки в ML-проектах, которые встречаются чаще всего
● Непонятные и слабые инструкции. В итоге легко попасть в ловушку: если гайдлайн составлен для галочки, то это может привести к некорректным трактовкам и, соответственно, к плохому датасету.
● Отказ от QA. Без непрерывного контроля качества ошибки будут накапливаться на каждом этапе обучения.
● Попытки «допилить модель». Если команда работает только над оптимизацией архитектуры, полностью игнорируя качество данных, то итоговый результат не будет представлять из себя что-то хорошее.
● Желание сэкономить на разметке. Такая стратегия может привести сначала к повторяющимся ошибкам, потом к переделкам и, в итоге, к росту бюджета.
Как все сделать правильно
Для хорошего результата практически в любом AI-проекте можно придерживаться одного и того же подхода.
- Конкретные и четкие руководства по разметке. Важно сразу установить описания классов, добавлять правила и примеры, а также позаботиться об edge-кейсах.
- Контроль качества на всех этапах. Советуем проводить выборочную проверку, что наблюдать за ходом работ. Также стоит использовать gold dataset, чтобы максимально проверять, как хорошо модель справляется с задачами. Еще один способ – двойная разметка, чтобы минимизировать человеческие ошибки.
- Управление процессами. Это «база» для любого проекта: поставить задачи ответственным, проконтролировать дедлайны, далее давать постоянную обратную связь аннотаторам.
- Выбор инструмента под задачу. Решение должно полностью соответствовать проекту. Например, поддерживать определенные типа аннотации, иметь комфортный интерфейс для командной работы.
Возможно ли сэкономить на разметке
Сэкономить и при этом не потерять в качестве – практически нереально. Учитывая то, что ошибки с большей вероятностью приведут к необходимости переразметки, то в итоге дешевая услуга превратится в действительно дорогую.
Важно понимать, что в стоимость разметки входит не только цена за сам объект, но и качество модели, цены за переделки и ошибки.
Делаем выводы
Нельзя воспринимать разметку просто как дополнительный или вспомогательный этап. Ведь это ключевой момент всей работы, от которого зависит качество данных. И вся проделанная работа в рамках разметки в итоге ведет к качественной модели.
Инвестирование в разметку можно назвать первой и действительно необходимой задачей, чтобы получить хороший результат в будущем.
Качественная ML-модель начинается не с алгоритма, а с данных. Разметка, гайдлайны и контроль качества помогают превратить сырые изображения, тексты, видео и аудио в датасеты, на которых AI действительно может учиться. Подробнее о разметке данных для машинного обучения — на сайте US-DATA: https://usdataml.com/.