
Представьте, что вы приходите в офис (или открываете ноутбук дома), и ваша главная задача на сегодня — сломать то, над чем сотни других инженеров трудились месяцами. Не по ошибке. А специально. И за это вам платят зарплату, причём очень хорошую.
Звучит как сюжет фильма про вредителя? На самом деле это вполне реальная и очень уважаемая профессия — инженер хаоса.
В то время как обычные разработчики и DevOps-инженеры стараются сделать системы максимально стабильными, инженер хаоса делает ровно наоборот: он намеренно устраивает сбои, чтобы проверить, выдержит ли система настоящий удар. Это как быть профессиональным провокатором в мире IT.
Кто такой инженер хаоса и чем он занимается
Инженер хаоса (Chaos Engineer) — это специалист по проверке устойчивости больших распределённых систем через контролируемые катастрофы.
Его работа не в том, чтобы «всё починить», а в том, чтобы заранее понять: что сломается, если всё пойдёт не так.
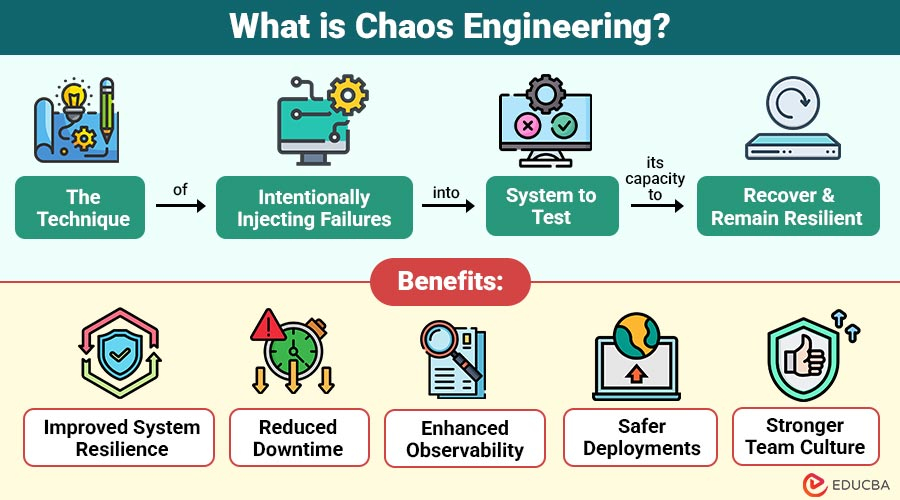
Что он делает на практике:
- Планирует и проводит «хаос-эксперименты».
- Выключает серверы, базы данных или целые дата-центры.
- Создаёт искусственную высокую нагрузку.
- Наблюдает, как система реагирует и восстанавливается.
- Находит слабые места, о которых никто даже не догадывался.
Простыми словами: это человек, который устраивает контролируемый апокалипсис, чтобы компания была готова к настоящему.
История профессии: от Chaos Monkey в Netflix до сегодняшнего дня
Профессия появилась не так давно. В 2011 году компания Netflix столкнулась с серьёзной проблемой. У них была сложная облачная инфраструктура на Amazon AWS, и периодически происходили сбои, которые никто не мог предсказать.
Тогда инженеры Netflix решили: вместо того чтобы ждать, когда что-то сломается само, будем ломать всё сами. Так появился инструмент Chaos Monkey — программа, которая в рабочее время случайным образом выключала виртуальные серверы.
Название выбрали с юмором: «Представьте стаю обезьян, которые бегают по дата-центру и выдергивают кабели из серверов».
Эксперимент оказался настолько успешным, что Netflix открыл исходный код инструмента и начал делиться принципами. Постепенно идея распространилась. Крупные компании (Google, Amazon, Microsoft, Uber, LinkedIn, Capital One) начали создавать целые команды Chaos Engineering.
Сегодня Chaos Engineering — это уже не экспериментальная практика, а важная часть культуры надёжности (Site Reliability Engineering) в технологических гигантах.
Как выглядит обычный рабочий день инженера хаоса
Утро начинается не с кофе и код-ревью, а с вопроса: «Что мы сегодня сломаем?».
Обычный день инженера хаоса может выглядеть так:
- Утро: Планирование эксперимента. Команда обсуждает, какой сценарий запускать — «убить» главный дата-центр в Европе или отключить базу данных PostgreSQL на 30 минут.
- День: Подготовка «предохранителей» — механизмов, которые быстро вернут систему в норму, если эксперимент пойдёт слишком плохо. Затем — запуск хаоса.
- Ключевой момент: Внимательное наблюдение в реальном времени. Инженер следит за метриками, графиками и поведением системы.
- Вечер: Разбор полётов. Что сломалось? Почему? Какие скрытые зависимости мы нашли? Команда составляет отчёт и рекомендации.
Важно: эксперименты почти никогда не запускают «вслепую». Всё тщательно готовится, часто в непиковые часы или на staging-окружении, прежде чем перейти в продакшен.
Самые интересные и страшные хаос-эксперименты (реальные кейсы)
- Netflix и Chaos Monkey: Самый известный пример. Программа случайно выключала серверы во время пиковой нагрузки. Однажды это помогло компании пережить реальный крупный сбой AWS без заметных проблем для пользователей.
- Uber: Инженеры проводили эксперимент под названием «Chaos Kong» — имитировали полный выход из строя целого региона (например, всего Восточного побережья США). Это позволило выявить критические проблемы в архитектуре.
- Кейс крупного банка: Во время теста «выключили» основной центр обработки данных в разгар торгового дня. Система должна была автоматически переключиться на резервный, но обнаружилась серьёзная задержка в синхронизации. Благодаря эксперименту банк успел исправить проблему до реальной аварии.
- Самый экстремальный: Одна компания намеренно отключила сразу 70% своих серверов во время Black Friday. Сервис продолжал работать, а пользователи ничего не заметили. После этого доверие к системе сильно выросло.
Почему эта профессия считается одной из самых странных в IT
Потому что она полностью противоречит обычной логике IT:
- Все вокруг пытаются сделать так, чтобы ничего не ломалось.
- Инженер хаоса приходит и говорит: «Давайте специально всё сломаем».
Это профессия-парадокс. Она сочетает в себе:
- Глубокий технический уровень (распределённые системы, облака, Kubernetes)
- Креативность и нестандартное мышление
- Смелость (нужно убедить руководство «поломать» продакшен)
- Психологию (умение работать с командой, которая часто боится экспериментов)
В то время как большинство IT-специалистов — «строители», инженер хаоса — это «разрушитель-исследователь». И именно поэтому профессия такая редкая и притягательная.
Какие навыки и качества действительно нужны
Чтобы стать инженером хаоса, недостаточно просто хорошо кодить. Здесь требуются особые навыки и склад ума:
Технические навыки:
- Глубокое понимание распределённых систем и микросервисов.
- Опыт работы с Kubernetes, Docker, облачными платформами (AWS, GCP, Azure).
- Знание мониторинга и observability (Prometheus, Grafana, Jaeger).
- Понимание принципов Site Reliability Engineering (SRE).
Личные качества:
- Системное мышление — умение видеть всю картину целиком
- Смелость и стрессоустойчивость — нужно быть готовым «ломать» критически важные системы
- Коммуникация — умение объяснить руководству и команде, почему хаос-эксперименты безопасны и полезны
- Креативность и «катастрофическое» мышление (постоянно придумывать, что может пойти не так)
Самое важное качество — это ответственность. Инженер хаоса должен уметь останавливаться вовремя и всегда иметь план «отката».
Сколько зарабатывают инженеры хаоса
Профессия относится к высокооплачиваемым даже по меркам IT:
- США: $160 000 – $280 000 в год (senior и lead)
- Европа (Германия, Великобритания, Нидерланды): €90 000 – €160 000 в год
- Россия / СНГ (в международных компаниях и крупных продуктах): $4 500 – $9 000+ в месяц
- Remote для зарубежных компаний: часто от $6 000 до $10 000+ в месяц
Зарплаты выше среднего среди DevOps и SRE-инженеров, потому что специалистов с реальным опытом Chaos Engineering очень мало.
Как войти в профессию: пошаговый путь
- База — станьте сильным DevOps/SRE инженером. Освойте Kubernetes, Terraform, облака.
- Теория — изучите принципы Chaos Engineering. Обязательно прочитайте книгу «Chaos Engineering» (Netflix) и документацию Gremlin.
- Практика — начните проводить небольшие эксперименты в своём текущем проекте (даже во время стажировки).
- Инструменты — освоите Chaos Mesh, Litmus Chaos, Gremlin или Steadybit.
- Опыт — ищите компании, где уже есть культура надёжности (финтех, крупные маркетплейсы, стриминговые сервисы).
- Портфолио — документируйте проведённые эксперименты и их результаты. Это ваш главный козырь при трудоустройстве.
Многие нынешние инженеры хаоса пришли из обычных SRE или DevOps.
Будущее Chaos Engineering — будет ли спрос расти
С каждым годом системы становятся всё сложнее: сотни микросервисов, мультиоблачные архитектуры, огромные объёмы данных и миллионы пользователей одновременно. В таком мире случайные сбои неизбежны.
Именно поэтому Chaos Engineering перестаёт быть «крутой фишкой» и превращается в необходимость. Крупные компании уже понимают: лучше самим устроить катастрофу в контролируемых условиях, чем ждать, когда она случится в самый неподходящий момент.
В ближайшие 5–7 лет ожидается:
- Рост числа выделенных команд Chaos Engineering
- Интеграция хаос-экспериментов в стандартные CI/CD-пайплайны
- Появление более умных, AI-поддерживаемых инструментов для автоматического хаоса
- Спрос на инженеров хаоса в финтехе, e-commerce, геймдеве и государственных системах
Профессия из редкой и экзотической постепенно становится одной из ключевых в области надёжности систем.
Заключение: Почему такие «безумцы» очень нужны
Инженер хаоса — это действительно одна из самых странных профессий в IT. Здесь ты официально получаешь зарплату за то, что ломаешь работу других людей.
Но за этой странностью стоит очень важная миссия: делать цифровой мир надёжнее. В эпоху, когда от работы приложений и сервисов зависит жизнь миллионов людей, нужны те, кто готов посмотреть в лицо хаосу и сказать: «Мы к тебе готовы».
Если вы любите сложные системы, не боитесь ответственности, обладаете системным мышлением и немного авантюрным характером — возможно, профессия инженера хаоса создана именно для вас.
В конце концов, иногда чтобы построить по-настоящему крепкий дом, нужно сначала попытаться его разрушить.