Предыдущая статья
* * *
Как правильно «обучить» ИИ под свои задачи
Когда компания или обычный пользователь решает внедрить ИИ в свою работу, возникает главный вопрос: как сделать так, чтобы робот знал именно мои данные? Например, подробности ваших документов, ваши медиа (фото, видео), или специфический для вашей компании или семьи процесс учета доходов и расходов.
Существует два пути: RAG и Fine-tuning. Чтобы понять разницу, представьте, что ИИ — это студент, которому нужно сдать экзамен по истории вашей компании.
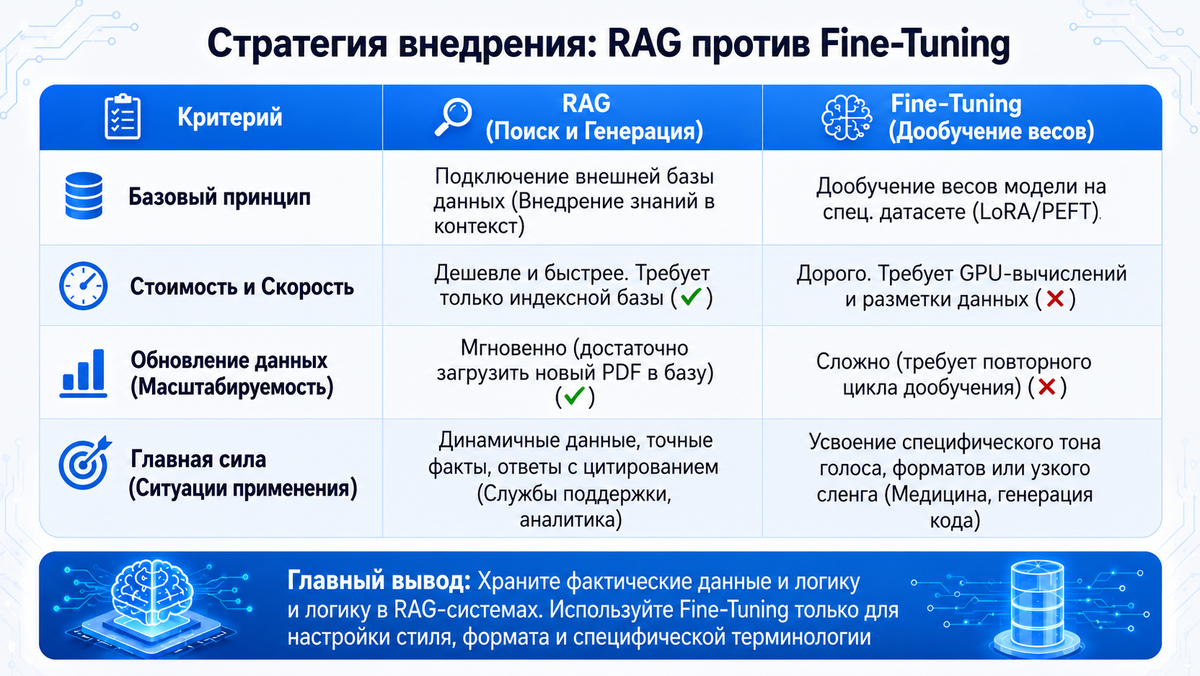
1. RAG: Экзамен с открытой книгой
RAG (Retrieval-Augmented Generation) — это метод, при котором мы не меняем сам «мозг» ИИ, а просто даем ему доступ к огромной библиотеке ваших документов.
Как это работает
Когда вы задаете вопрос, система за доли секунды обегает вашу базу данных, предоставленную ему в понятном виде (подробно в предыдущей статье рассмотрели), находит нужные кусочки текста и «подкладывает» их роботу прямо в чат вместе с вашим вопросом.
В чем прелесть
- Это дешево и быстро. Вам не нужно переучивать саму модель, достаточно просто создать индексную векторную базу данных
- Обновление данных — мгновенное. Загрузили новый приказ в базу или свежие письма из почты — и через секунду ИИ уже знает обо всем этом
- Точность и ссылки. ИИ не выдумывает факты, а читает их в документе и может даже дать ссылку: «Я взял это из пункта 5 вашего регламента»
Для чего подходит
В бизнесе: Службы поддержки, аналитика, работа с постоянно меняющимися законами и правилами компании.
2. Fine-tuning: Получение «узкого» диплома
Fine-tuning (дообучение весов) — это процесс изменения внутренних настроек модели. Мы буквально «вдалбливаем» новые знания в нейронные связи робота.
Как это работает
Модель проходит повторный цикл обучения на специальном наборе данных. Она начинает «чувствовать» стиль речи или специфическую логику на уровне инстинктов
В чем сложность
- Это затратно. Чтобы дообучить даже среднюю модель, нужны мощнейшие видеокарты, а один цикл может длиться 4-5 дней непрерывной работы
- Сложно обновлять. Если данные изменились (например, поменялся формат отчетности), вам придется заново запускать весь дорогостоящий процесс дообучения
Для чего подходит
Когда нужно привить ИИ специфический тон голоса (Tone of Voice, ToV – например, чтобы он общался как ваш бренд-бук), научить его узкому сленгу (медицина, юриспруденция) или сложному/специфическому кодированию (например, языку 1С, про который практически никакая западная модель не знает).

Почему даже гиганты (Сбер и Яндекс) не всегда дообучают модели?
Есть мнение, что крупнейшие российские игроки, вложившие миллиарды рублей в «железо», часто отказываются от постоянного дообучения своих топовых ИИ-моделей. Почему? Потому что мировые лидеры (вроде OpenAI) вкладывают миллиарды долларов в этот процесс. Затраты просто несопоставимы.
Реальность сегодня такова
Проще взять мощную готовую модель и «обложить» ее набором правил и контекстов через технологию RAG. Это позволяет модели понимать локальную специфику (например, что такое «Родина» в нашем контексте), не тратя месяцы на переучивание.
Пример из жизни: 1С против обычного текста
Если вам нужно, чтобы ИИ понимал ваши письма — используйте RAG. Но если вы хотите научить его программировать на языке 1С, простого «подкладывания документов» (RAG) не хватит. ИИ не поймет общую логику системы из разрозненных кусков. Именно поэтому фирма 1С уже 3 года строит свой центр обработки данных для Fine-tuning своего «помощника» — это тот редкий случай, когда глубокое дообучение оправдано.
💡 Лайфхаки для руководителя и пользователя
- Стратегия 90/10: Для 90% ваших задач и задач вашего бизнеса (документы, фотки, справки, отчеты, поиск информации) идеально подходит RAG. Оставьте Fine-tuning только для тех 10% случаев, где критически важен уникальный стиль или сверхсложная логика – возможно вы никогда не дойдете до этих 10%. А если дойдете – привлечете специалиста и он вам все настроит
- Миф об обучении: Помните: когда вы загружаете документ в обычный чат с ChatGPT, модель не учится на нем навсегда. Она просто использует его как «справку» для текущего разговора (контекст текущего чата). Удалили чат и LLM всё забудет
- Гибридный подход: Лучшие системы сегодня работают так: маленькая модель (Fine-tuned) следит за безопасностью и стилем, а большая база знаний (RAG) поставляет актуальные факты
Главный совет: Не пытайтесь «переизобрести мозг» нейросети, если вам просто нужно, чтобы она помнила содержание ваших документов. Начните с RAG — это путь, который экономит деньги, время и нервы.
* * *
А как вы считаете, что важнее для сотрудника: знать всё назубок или уметь быстро найти информацию в справочнике? ИИ сейчас стоит перед тем же выбором!
* * *
Следующая статья – ссылка скоро появится