С появлением искусственного интеллекта, который работает прямо на моём компьютере, я получил не только полную конфиденциальность, но и избавился от необходимости платить за API, подписки, переживать из-за интернета и лимитов в самый неподходящий момент. Раньше локальные ассистенты часто работали медленно и нестабильно, но сегодня новые модели не уступают облачным — главное, знать, как их использовать.
Особенно меня удивила свежая версия Qwen для программирования — я теперь половину времени работаю с ней на своей машине.
Qwen: наконец локальный AI для кода работает как надо
В паре с VSCodium — полностью открытое решение
Сейчас есть десятки локальных AI для кодинга, и качество быстро меняется от модели к модели. Признаюсь, раньше большинство были только прокачанным автодополнением — особо не выручали.
Теперь всё изменилось. Я протестировал разные версии Qwen, и они действительно шустро справляются с задачами даже на обычном ПК. Модель умеет дописывать код, помогать с рефакторингом и написанием тестов — причём делает это очень достойно. С ней можно обдумывать архитектуру и писать функции, но советую всё же формулировать задачи самому: пока до облачных флагманов она не дотягивает, и любит, чтобы ей подсказывали.
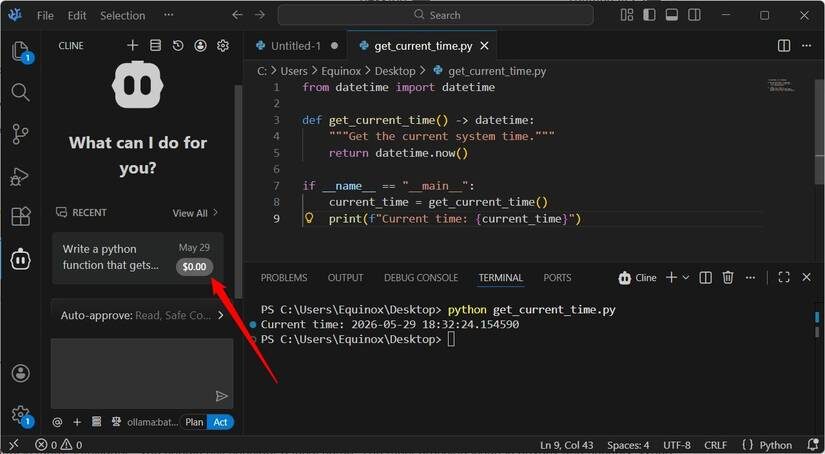
Свой AI я запускаю прямо в VSCodium через расширение Cline — появляется удобная боковая панель: можно отправлять запросы, подтверждать фрагменты кода и полностью контролировать контекст. Обычно я доверяю ИИ рутину, а сложные запросы и масштабный рефакторинг по-прежнему отправляю Claude — чтобы не тратить лимиты.
Вся эта система работает на Ollama, и теперь я легко подключаюсь к своему AI с любого устройства дома. Больше я не привязан к стационару — могу писать код и с ноутбука.
Имейте в виду: AI развивается очень быстро. Лидеры среди локальных LLM могут меняться каждый месяц, но даже сейчас эти модели стоят потраченного времени и усилий на настройку.
Облачные модели умней, но локальный AI — бесплатно и под полным контролем
Приватность, экономия, постоянный доступ — главные плюсы
Да, облачные модели зачастую мощнее, но локальный AI — это уровень приватности и безопасности, о котором облака могут только мечтать: весь код остаётся у вас, никто не подсмотрит ваши идеи, конфиденциальные проекты останутся только на вашем диске. Это особенно важно, если вы работаете с клиентскими или корпоративными задачами.
Экономия здесь тоже приятная. Сервисы вроде Claude, ChatGPT, Gemini обходятся примерно в 2000 рублей ежемесячно, и если не следить за лимитами, платёжка может неприятно удивить. Запустив своего AI на ПК, вы прощаетесь с подписками и сложными подсчётами токенов навсегда.
Claude
Claude — ассистент от Anthropic, который помогает с самыми разными задачами: писать тексты, кодировать, анализировать, искать информацию и многое другое. Главное — он не просто поисковик, а полноценный собеседник, который думает вместе с вами и предлагает настоящие решения по ходу диалога.
Ваши траты сведутся лишь к небольшому расходу электричества, если компьютер с видеокартой уже есть. Может показаться, что экономия небольшая, но годовая подписка на Claude Max — это минимум 10 000 рублей, а значит, за пару лет вы сэкономите на видеокарту класса RTX 5080 или даже 5090 (если, конечно, повезёт найти по нормальной цене).
Ещё один плюс — не зависите от сторонних серверов: бывало, хочу обратиться к Claude или Codex, а сервис то недоступен, то перегружен. А свой локальный AI всегда онлайн, если сам компьютер не выключен.
Локальный AI для кода: плюсы, минусы и компромиссы
Всё упирается в железо: видеопамять, квантизация и окно контекста
Минусы тоже есть, и главный из них — технические ограничения.
Если у вас видеокарта среднего сегмента, например GeForce 5070Ti (именно такая стоит у меня), могут возникнуть "узкие места". Главное — объём VRAM: он определяет, какую модель получится загрузить и сколько кода ассистент сможет анализировать за раз.
Здесь спасает квантизация — те самые Q4, Q5 или Q8 в описании модели. Это степень сжатия: Q8 (8 бит) — максимум качества, Q4 (4 бита) — чуть хуже, но позволяет запускать большие модели даже на карточках с небольшим VRAM. Мне лично удавалось на Q4 "протолкнуть" 27-миллиардные модели на 5070Ti — более тяжёлые уже не тянет.
Что такое LLM? Как искусственный интеллект общается на равных
LLM — это ультрасовременная технология, но как она действительно работает под капотом?
Стоит учитывать — локальный AI обычно медленнее облака, особенно на сложных задачах: не всегда большой объем кода помещается в контекст.
Локальные AI для кодинга — наконец стоит попробовать
Локальные LLM перестали быть лишь забавной игрушкой — теперь я полагаюсь на них каждый день. Многое зависит от правильной настройки и интеграции.
Попробуйте подключить такую модель к VSCodium или другому редактору — пусть локальный AI дополнит ваши облачные сервисы. Для тяжёлых задач пока лучше облачные гиганты, но свой бесплатный, полностью приватный и всегда готовый ассистент — отличная подмога любому разработчику.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru