Рассмотрим возможность создания отказоустойчивого кластера XSQUARE - PGHS с Angie.
Angie доступен в виде платной и бесплатной версии, в бесплатной версии отсутсвует upstream_probe, поэтому переключение возможно только в случае отказа сервера, с платной версией также возможно переключение в случае отказа сервиса.
Варианты создания кластера:
1. Application failover.
На каждом узле находится приложение PGHS с базой XRAD. В случае отказа пользователю необходимо повторно ввести учётные данные.
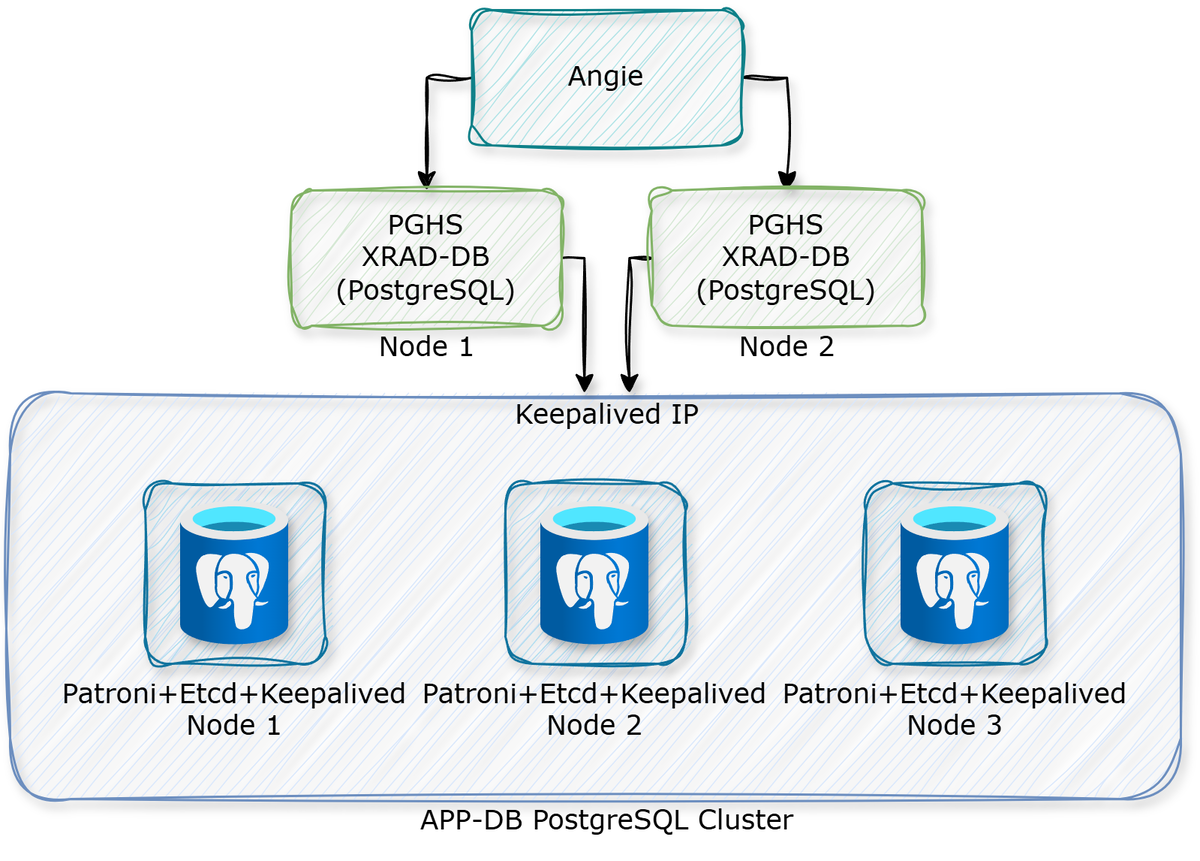
Failback application failover кластер является рекомендованным, т.к. позволяет создать неограниченное количество узлов PGHS и обеспечить более простой и предсказуемые CI/CD (простое копирование узлов)
2. Transparent application failover.
На каждом узле находится приложение PGHS, база XRAD вынесена в кластер PostgreSQL. В случае отказа сессии сохраняются, так как база находится в единственном месте, рядом с базой бизнес-приложения.
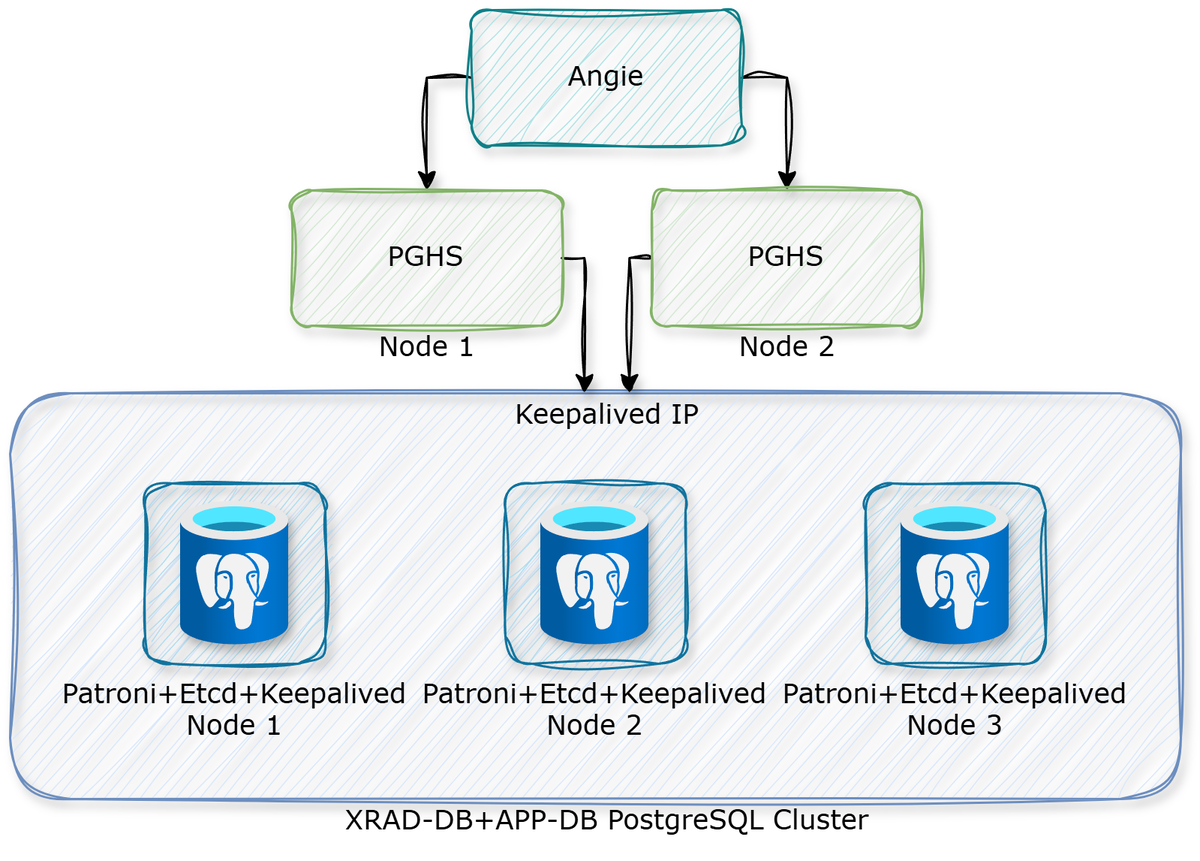
В обоих случаях база бизнес-приложения находится в кластере PostgreSQL, ниже также будет описано создание простого кластера postgres с keepalived и etcd на каждом узле.
Подготовка XSQUARE - PGHS
Каждый узел для тестирования можно подготовить с помощью скрипта установки на Debian 13.
apt-get update
apt-get dist-upgrade
apt-get clean all
apt-get -y install wget
cd /root/
wget https://lcdp.xsquare.ru/edu/files/pghs_xrad/6.4.5.5.5.5/xsquare.lcdp.6.4.5.5.5.5_release_full_installation.sh
chmod +x xsquare.lcdp.6.4.5.5.5.5_release_full_installation.sh
./xsquare.lcdp.6.4.5.5.5.5_release_full_installation.sh
Установка Angie
Процесс установки подробно описан на сайте разработчика Angie Software, там же можно найти информации по вопросам получения лицензии и документацию к продукту.
Актуальное описание установки открытой версии:
https://angie.software/angie/docs/installation/oss_packages/
Актуальное описание установки PRO версии:
https://angie.software/angie/docs/installation/pro_packages/
Конфигурация Angie
Файлы конфигурцации распологаются в /etc/angie/http.d
Для PRO версии доступен upstream_probe, с помощью этой директивы происходит проверка ответа страницы сервиса и в случае ответа отличного от 200, происходит переключение на другой доступный сервер. Т.е. переключение происходит как в случае отказа сервера целиком, так и в случае проблем с подключением к базе XRAD.
Сначала нужно описать upstream (# в начале строки означает, что параметр не задействован):
upstream pghs_backend {
zone pghs_backend 1m;
server pghs-node1:80 sid=pghs-node1 max_fails=3 fail_timeout=10s;
server pghs-node2:80 sid=pghs-node2 max_fails=3 fail_timeout=10s;
sticky cookie srv_id max-age=86400;
#sticky_secret my_secret.$remote_addr;
#sticky_strict on;
}
Название upstream и зоны разделяемой памяти здесь одинаковые, в server указан sid - необязательный параметр, который задаёт имя для srv_id в cookie, чтобы можно было понять, для теста, на каком узле мы находимся и смоделировав отказ увидеть, что значение изменилось на имя другого хоста. Если не указывать sid, то значение будет генерироваться случайно. Так же, можно указать параметр "sticky_secret my_secret.$remote_addr;", с его помощью sid шифруется в зависимости от удаленного адреса подключения.
max_fails=3 - колличество неудачных попыток связи с сервером.
fail_timeout - время в течении которого должен произойти max_fail.
sticky_strict on - жестко привязывает клиента к хосту из upstream и в случае отказа не переключает сессию, может использоваться в случае когда нужна только балансировка без отработки отказа.
sticky cookie - привязка сессии с помощью cookie, max-age - время жизни cookie.
Для upstream_probe нужно добавить map:
map $upstream_status $status_code {
200 "1";
}
В блоке server добавить location на upstream:
server {
...
location / {
proxy_pass http://pghs_backend;
upstream_probe pghs_backend_probe
uri=/pghs/showPage?page=1
interval=10s
method=GET
test=$status_code
fails=3
passes=1
mode=always
essential
persistent;
}
...
}
Подробнее про параметры upstream_probe можно прочесть в документации:
https://angie.software/angie/docs/configuration/modules/http/http_upstream_probe/
Примеры конфигурации Angie.
Angie PRO - /etc/angie/http.d/pghs.xsquare.conf:
upstream pghs_backend {
zone pghs_backend 1m;
server pghs-node1:80 sid=pghs-node1 max_fails=3 fail_timeout=10s;
server pghs-node2:80 sid=pghs-node2 max_fails=3 fail_timeout=10s;
sticky cookie srv_id max-age=86400;
#sticky_secret my_secret.$remote_addr;
#sticky_strict on;
}
log_format custom '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$upstream_addr" "$upstream_status"';
map $upstream_status $status_code {
200 "1";
}
server {
listen 80;
server_name pghs.xsquare;
#return 301 https://$server_name$request_uri;
server_tokens off;
access_log /var/log/angie/pghs.xsquare.access.log custom;
error_log /var/log/angie/pghs.xsquare.error.log;
location / {
proxy_pass http://pghs_backend;
upstream_probe pghs_backend_probe
uri=/pghs/showPage?page=1
interval=10s
method=GET
test=$status_code
fails=3
passes=1
mode=always
essential
persistent;
}
}
server {
listen 443 ssl;
server_name pghs.xsquare;
server_tokens off;
access_log /var/log/angie/pghs.xsquare.access.log custom;
error_log /var/log/angie/pghs.xsquare.error.log;
root /var/www/pghs.xsquare;
index index.html;
ssl_certificate /etc/angie/keystore/pghs.xsquare/pghs.xsquare.crt;
ssl_certificate_key /etc/angie/keystore/pghs.xsquare/pghs.xsquare.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305;
ssl_prefer_server_ciphers off;
location / {
proxy_pass http://pghs_backend;
upstream_probe pghs_backend_probe
uri=/pghs/showPage?page=1
interval=10s
method=GET
test=$status_code
fails=3
passes=1
mode=always
essential
persistent;
}
}
Angie OSS - `/etc/angie/http.d/pghs.xsquare.conf`:
upstream pghs_backend {
zone pghs_backend 1m;
server pghs-node1:80 sid=pghs-node1 max_fails=3 fail_timeout=10s;
server pghs-node2:80 sid=pghs-node2 max_fails=3 fail_timeout=10s;
sticky cookie srv_id max-age=86400;
#sticky_secret my_secret.$remote_addr;
#sticky_strict on;
}
log_format custom '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$upstream_addr" "$upstream_status"';
server {
listen 80;
server_name pghs.xsquare;
#return 301 https://$server_name$request_uri;
server_tokens off;
access_log /var/log/angie/pghs.xsquare.access.log custom;
error_log /var/log/angie/pghs.xsquare.error.log;
location / {
proxy_pass http://pghs_backend;
}
}
server {
listen 443 ssl;
server_name pghs.xsquare;
server_tokens off;
access_log /var/log/angie/pghs.xsquare.access.log custom;
error_log /var/log/angie/pghs.xsquare.error.log;
root /var/www/pghs.xsquare;
index index.html;
ssl_certificate /etc/angie/keystore/pghs.xsquare/pghs.xsquare.crt;
ssl_certificate_key /etc/angie/keystore/pghs.xsquare/pghs.xsquare.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305;
ssl_prefer_server_ciphers off;
location / {
proxy_pass http://pghs_backend;
}
}
В конфигурации используется custom log, с помощью $upstream_addr и $upstream_status в логе отображается на какой именно хост из upstream пришел запрос.
Кластер PostgreSQL
Организация отказоустойчивого кластера БД не относится к разработке приложения, но на это может быть интересно посмотреть. Поэтому ниже можно найти процесс установки и файлы конфигурации для сервисов кластера Patroni, для простоты etcd установливается рядом. Установка производится на каждом узле кластера, в некоторых местах отличаются только конфигурации. Команды для Debian 13.
Etcd
Установка:
sudo apt install etcd-server etcd-client python3-etcd
Создание отдельного каталога и удаление стандартного:
sudo systemctl stop etcd.service
sudo mkdir -p /data/etcd
sudo chown -R etcd:etcd /data/etcd
sudo rm -rf /var/lib/etcd/*
Создаем конфигурацию для каждого узла кластера:
sudo vim /etc/default/etcd
# node 1
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/data/etcd"
ETCD_LISTEN_PEER_URLS="http://<IP-ADDRESS-NODE-1>:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://<IP-ADDRESS-NODE-1>:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://pg-node1:2380"
ETCD_INITIAL_CLUSTER="etcd-1=http://pg-node1:2380,etcd-2=http://pg-node2:2380,etcd-3=http://pg-node3:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://pg-node1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_ENABLE_V2="true"
# node 2
ETCD_NAME="etcd-2"
ETCD_DATA_DIR="/data/etcd"
ETCD_LISTEN_PEER_URLS="http://<IP-ADDRESS-NODE-2>:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://<IP-ADDRESS-NODE-2>:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://pg-node2:2380"
ETCD_INITIAL_CLUSTER="etcd-1=http://pg-node1:2380,etcd-2=http://pg-node2:2380,etcd-3=http://pg-node3:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://pg-node2:2379"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_ENABLE_V2="true"
# node 3
ETCD_NAME="etcd-3"
ETCD_DATA_DIR="/data/etcd"
ETCD_LISTEN_PEER_URLS="http://<IP-ADDRESS-NODE-3>:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://<IP-ADDRESS-NODE-3>:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://pg-node3:2380"
ETCD_INITIAL_CLUSTER="etcd-1=http://pg-node1:2380,etcd-2=http://pg-node2:2380,etcd-3=http://pg-node3:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://pg-node3:2379"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_ENABLE_V2="true"
В файле службы указываем параметр с созданнной ранее директорией для данных:
sudo vim /etc/systemd/system/etcd2.service
Environment=ETCD_DATA_DIR=/data/etcd
Перезапускаем службу и проверяем статус:
sudo systemctl restart etcd.service
sudo systemctl status etcd.service
Проверка кластера:
etcdctl endpoint status --cluster
Patroni
Установка:
sudo apt -y install postgresql-17 postgresql-server-dev-17 patroni etcd-client etcd-python3 python3-psycopg2
Делаем симлинк для бинарных файлов postgres в /usr/sbin
sudo ln -s /usr/lib/postgresql/17/bin/* /usr/sbin/
Созадем каталог данных для PostgreSQL:
sudo mkdir -p /postgresql_data/17/data
sudo chown postgres:postgres -R /postgresql_data/17
На каждом узле создаем конфигурацию:
sudo vim /etc/patroni/config.yml
# node 1
scope: postgres-xsquare
namespace: /pghs-xrad/
name: pg-node1
restapi:
listen: pg-node1:8008
connect_address: pg-node1:8008
etcd:
hosts: pg-node1:2379,pg-node2:2379,pg-node3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby # or replica
hot_standby: "on"
wal_keep_segments: 8
max_wal_senders: 5
max_replication_slots: 5
max_connections: 100
max_worker_processes: 8
max_locks_per_transaction: 64
wal_log_hints: "on"
track_commit_timestamp: "off"
archive_mode: "on"
archive_timeout: 1800s
# Command to archive WAL files. This command creates a directory named 'wal_archive', checks if the file doesn't already exist, and then copies it
archive_command: mkdir -p ../wal_archive && test ! -f ../wal_archive/%f && cp %p ../wal_archive/%f
recovery_conf:
# Command used to retrieve archived WAL files during recovery. It copies files from the 'wal_archive' directory.
restore_command: cp ../wal_archive/%f %p
initdb:
- auth: scram-sha-256
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 scram-sha-256
- host replication replicator pg-node1 scram-sha-256
- host replication replicator pg-node2 scram-sha-256
- host replication replicator pg-node3 scram-sha-256
- host all all 0.0.0.0/0 scram-sha-256
postgresql:
listen: 0.0.0.0:5432 # This can remain as is for local connections
connect_address: pg-node1:5432 # or Point to PgBouncer if you have it externally
data_dir: /postgresql_data/17/data
authentication:
replication:
username: replicator
password: xsquare
superuser:
username: postgres
password: xsquare
parameters:
unix_socket_directories: '/var/run/postgresql'
max_connections: 100
shared_buffers: 512MB
wal_level: replica
hot_standby: "on"
max_wal_senders: 5
max_replication_slots: 5
password_encryption: 'scram-sha-256'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
# node 2
scope: postgres-xsquare
namespace: /pghs-xrad/
name: pg-node2
restapi:
listen: pg-node2:8008
connect_address: pg-node2:8008
etcd:
hosts: pg-node1:2379,pg-node2:2379,pg-node3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby # or replica
hot_standby: "on"
wal_keep_segments: 8
max_wal_senders: 5
max_replication_slots: 5
max_connections: 100
max_worker_processes: 8
max_locks_per_transaction: 64
wal_log_hints: "on"
track_commit_timestamp: "off"
archive_mode: "on"
archive_timeout: 1800s
# Command to archive WAL files. This command creates a directory named 'wal_archive', checks if the file doesn't already exist, and then copies it
archive_command: mkdir -p ../wal_archive && test ! -f ../wal_archive/%f && cp %p ../wal_archive/%f
recovery_conf:
# Command used to retrieve archived WAL files during recovery. It copies files from the 'wal_archive' directory.
restore_command: cp ../wal_archive/%f %p
initdb:
- auth: scram-sha-256
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 scram-sha-256
- host replication replicator pg-node1 scram-sha-256
- host replication replicator pg-node2 scram-sha-256
- host replication replicator pg-node3 scram-sha-256
- host all all 0.0.0.0/0 scram-sha-256
postgresql:
listen: 0.0.0.0:5432 # This can remain as is for local connections
connect_address: pg-node2:5432 # or Point to PgBouncer if you have it externally
data_dir: /postgresql_data/17/data
authentication:
replication:
username: replicator
password: xsquare
superuser:
username: postgres
password: xsquare
parameters:
unix_socket_directories: '/var/run/postgresql'
max_connections: 100
shared_buffers: 512MB
wal_level: replica
hot_standby: "on"
max_wal_senders: 5
max_replication_slots: 5
password_encryption: 'scram-sha-256'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
# node 3
scope: postgres-xsquare
namespace: /pghs-xrad/
name: pg-node3
restapi:
listen: pg-node3:8008
connect_address: pg-node3:8008
etcd:
hosts: pg-node1:2379,pg-node2:2379,pg-node3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby # or replica
hot_standby: "on"
wal_keep_segments: 8
max_wal_senders: 5
max_replication_slots: 5
max_connections: 100
max_worker_processes: 8
max_locks_per_transaction: 64
wal_log_hints: "on"
track_commit_timestamp: "off"
archive_mode: "on"
archive_timeout: 1800s
# Command to archive WAL files. This command creates a directory named 'wal_archive', checks if the file doesn't already exist, and then copies it
archive_command: mkdir -p ../wal_archive && test ! -f ../wal_archive/%f && cp %p ../wal_archive/%f
recovery_conf:
# Command used to retrieve archived WAL files during recovery. It copies files from the 'wal_archive' directory.
restore_command: cp ../wal_archive/%f %p
initdb:
- auth: scram-sha-256
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 scram-sha-256
- host replication replicator pg-node1 scram-sha-256
- host replication replicator pg-node2 scram-sha-256
- host replication replicator pg-node3 scram-sha-256
- host all all 0.0.0.0/0 scram-sha-256
postgresql:
listen: 0.0.0.0:5432 # This can remain as is for local connections
connect_address: pg-node3:5432 # or Point to PgBouncer if you have it externally
data_dir: /postgresql_data/17/data
authentication:
replication:
username: replicator
password: xsquare
superuser:
username: postgres
password: xsquare
parameters:
unix_socket_directories: '/var/run/postgresql'
max_connections: 100
shared_buffers: 512MB
wal_level: replica
hot_standby: "on"
max_wal_senders: 5
max_replication_slots: 5
password_encryption: 'scram-sha-256'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
Собираем расширение http:
sudo apt install make gcc libcurl4-openssl-dev -y
wget https://lcdp.xsquare.ru/files/pgsql-http/v1.7.0.tar.gz
tar -xzf v1.7.0.tar.gz
cd pgsql-http-1.7.
make
sudo make install
Отключаем службу postgresql и включаем patroni:
sudo systemctl disable --now postgresql.service
sudo systemctl start patroni.service
sudo systemctl status patroni.service
Проверка статуса кластера:
patronictl -c /etc/patroni/config.yml list
Keepalived
Установка:
sudo apt install keepalived curl -y
На каждом узле создаем конфигурацию:
sudo vim /etc/keepalived/keepalived.conf
# node 1
global_defs {
script_user xsquare
enable_script_security
}
vrrp_script chk_patroni {
script "/home/xsquare/check_patroni.sh"
interval 5
timeout 3
fall 2
rise 1
}
vrrp_instance VRRP1 {
state BACKUP
interface ens192
virtual_router_id 101
priority 255
advert_int 1
authentication {
auth_type PASS
auth_pass xsquare
}
virtual_ipaddress {
<IP-ADDRESS-FOR-CLUSTER>/24
}
track_script {
chk_patroni
}
}
# node 2
global_defs {
script_user xsquare
enable_script_security
}
vrrp_script chk_patroni {
script "/home/xsquare/check_patroni.sh"
interval 5
timeout 3
fall 2
rise 1
}
vrrp_instance VRRP1 {
state BACKUP
interface ens192
virtual_router_id 101
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass xsquare
}
virtual_ipaddress {
<IP-ADDRESS-FOR-CLUSTER>/24
}
track_script {
chk_patroni
}
}
# node 3
global_defs {
script_user xsquare
enable_script_security
}
vrrp_script chk_patroni {
script "/home/xsquare/check_patroni.sh"
interval 5
timeout 3
fall 2
rise 1
}
vrrp_instance VRRP1 {
state BACKUP
interface ens192
virtual_router_id 101
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass xsquare
}
virtual_ipaddress {
<IP-ADDRESS-FOR-CLUSTER>/24
}
track_script {
chk_patroni
}
}
На каждом узле создаем скрипт мониторинга:
В данном случае, он расположен в папке пользователя xsquare и исполняется от его имени, script_user xsquare в файле конфигурации.
vim /home/xsquare/check_patroni.sh
# node 1
#!/bin/bash
curl -sf http://pg-node1:8008/master > /dev/null
exit $?
# node 2
#!/bin/bash
curl -sf http://pg-node2:8008/master > /dev/null
exit $?
# node 3
#!/bin/bash
curl -sf http://pg-node3:8008/master > /dev/null
exit $?
Делаем скрипт исполняемым:
chmod 744 /home/xsquare/check_patroni.sh
Перезапускаем службу и проверяем статус:
sudo systemctl restart keepalived.service
Можно определить состояние командой:
kill -USR1 $(cat /var/run/keepalived.pid) && sleep 1 && cat /tmp/keepalived.data | grep State
Основной узел:
State = MASTER
State = idle
Резервные:
State = FAULT
State = idle