Добрый день. На этом научном канале мы говорим об актуальных проблемах в медицине, фармацевтике и сельском хозяйстве. И делаем мы это с точки зрения биоинформатики. Этот выпуск выходит в поддержку внутривузовского AI medtech стартапа OnSiteSeq, над которым я занят в свободное от основной работы время. И мы продолжаем тему эпидемии ВИЧ-инфекции.
«Каждая смерть человека с ВИЧ — это несправедливость, иногда нелепость.»
Это цитата из подкаста студии «Либо/Либо» — «Одни плюсы. Она очень любила жить: эпизод в память умерших от СПИДа». Подкаст повествует о судьбах пациентов, которые из-за отрицания ВИЧ отказались от антиретровирусной терапии (АРВТ) и трагически погибли. Ежегодно СПИД уносит жизни более 30 тысяч россиян - цифры, прозвучавшие в подкасте в 2020 году, справедливы и для 2026-го.
Но не все эти трагедии связаны с ВИЧ-диссидентством. Среди причин есть и неэффективность терапии, вызванная лекарственной устойчивостью (ЛУ) вируса.
Что, если бы мы могли уже на первичном приёме предсказать лекарственную устойчивость и сразу подобрать эффективную схему лечения? Разве это не реальный путь к сокращению числа жертв эпидемии ВИЧ/СПИД?
В предыдущих выпусках мы рассмотрели историю возникновения и развития эпидемии ВИЧ, а также молекулярную биологию вируса. В этом выпуске давайте разберём, какие биоинформатические инструменты позволяют изучать ВИЧ-инфекцию и какие данные они могут предоставить врачам-клиницистам.
Почему определение субтипа и резистентности ВИЧ — это важно?
Исследования, проведённые в России, рисуют удручающую картину. По данным многоцентрового российского исследования, охватившего 1888 пациентов из шести федеральных округов, частота выявления мутаций лекарственной устойчивости у пациентов с вирусологической неудачей АРВТ достигает 60–80%. Пилотное исследование в Орловской области (Кириченко и др., ЖМЭИ, 2024) подтверждает: МЛУ обнаруживаются у 52% пациентов с опытом АРТ. Иными словами, у большинства пациентов с вирусологической неудачей смена схемы без учёта профиля устойчивости заведомо обречена на провал.
Мониторинг МЛУ выявляет ключевые мутации, снижающие эффективность назначаемых препаратов. Схемы лечения различаются в разных странах, что приводит к изменению тенденций ЛУ в разных географических точках. В России, где доминирует субтип A6, также есть свои особенности эпидемиологии устойчивости.
Для достижения целей ЮНЭЙДС «95-95-95» к 2030 году надёжные, быстрые и экономически эффективные методы анализа лекарственной устойчивости имеют решающее значение.
Нанопоровое секвенирование: от молекулы к электрическому сигналу

Прежде чем разобрать конкретный пайплайн, скажем несколько слов о технологии, которая лежит в его основе.
Нанопоровое секвенирование — это метод чтения ДНК или РНК путём пропускания одиночной молекулы через белковую нанопору, встроенную в искусственную мембрану. Через мембрану пропускают слабый электрический ток. Когда молекула нуклеиновой кислоты проходит сквозь пору, каждый нуклеотид — A, T, C, G — по-своему изменяет проводимость канала. Эти крошечные флуктуации тока фиксируются с высокой частотой и записываются в виде непрерывного «сигнала». Графическое представление этих изменений называется squiggle.
Ключевые преимущества технологии:
- Портативность: самый компактный прибор (Нанопорус, Россия) весит менее 115 г и подключается через USB.
- Длинные прочтения: нанопоровые риды могут достигать десятков тысяч нуклеотидов — против сотен у классических методов. Это упрощает сборку вирусного генома.
- Скорость: результаты доступны уже через несколько часов после начала эксперимента.
Именно эти свойства делают нанопоровое секвенирование идеальным кандидатом для диагностики «у постели больного / у стола врача» (point-of-care).
От пробирки до секвенатора: подготовка образца
Прежде чем POD5-файлы окажутся на входе нашего пайплайна, образец проходит лабораторную подготовку. Сырьём служит плазма крови пациента.
- Экстракция РНК — из плазмы выделяют вирусную РНК.
- Обратная транскрипция (RT) — вирусная РНК переводится в комплементарную ДНК (кДНК) с помощью фермента обратной транскриптазы. Мы подробно разбирали этот фермент во второй части: именно он является мишенью для НИОТ и ННИОТ.
- ПЦР-амплификация — специфические праймеры «размножают» нужные участки вирусного генома: ген pol (зоны протеазы, обратной транскриптазы, интегразы) и ген env. Этот шаг необходим, поскольку количество вирусной РНК в образце невелико, а секвенатор требует достаточного количества материала. Для понимания этих особенностей молекулярной биологии вируса предлагаю еще раз посмотреть вторую часть цикла о ВИЧ.
- Подготовка библиотеки — полученные ПЦР-продукты лигируются со специальными адаптерами, необходимыми для захвата молекул нанопорой.
- Нанесение на flow cell — подготовленная библиотека наносится на чип прибора, и начинается секвенирование.
На выходе из прибора мы получаем файлы в формате POD5 — и именно с них начинается работа пайплайна.
Экосистема OnSiteSeq
Описанный далее пайплайн работает в рамках экосистемы OnSiteSeq - внутривузовского стартапа, реализующего концепцию секвенирования «на месте»: у стола врача СПИД-центра, у постели больного, в полевых условиях.
Основу составляют два компонента. OnSiteSeq Edge - программно-аппаратный комплекс на базе портативного нанопорового секвенатора «Нанопорус» (Россия) с вычислительным GPU-модулем и сенсорным экраном. OnSiteSeq Cockpit - система управления контейнеризированными биоинформатическими пайплайнами с вариантами для самого устройства (Edge), рабочей станции врача (Desktop) и облачных провайдеров — Yandex Cloud, Cloud.ru (версия Cloud).
Пайплайны распространяются через маркетплейс на базе open-source системы Harbor — по аналогии с тем, как приложения устанавливаются из App Store или Google Play.
В этом выпуске разберём пайплайн для определения субтипа и лекарственной устойчивости ВИЧ-1.
Архитектура пайплайна
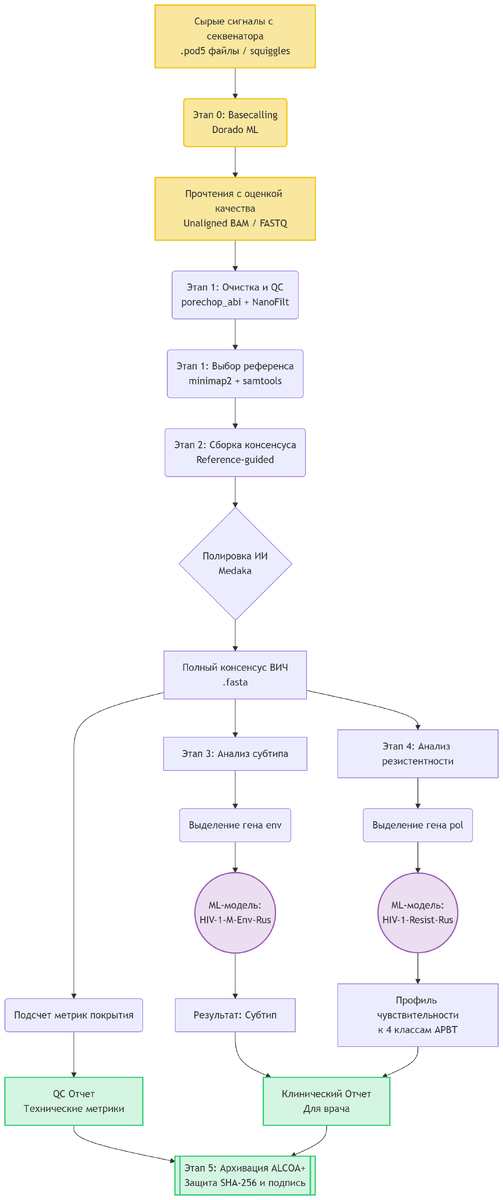
Давайте разберём каждый этап отдельно.
Этап 0: Basecalling - перевод сигнала в нуклеотиды
На выходе из нанопорового секвенатора мы получаем «сырые» данные в формате POD5. Эти файлы не содержат последовательность нуклеотидов: они хранят необработанные измерения электрического тока — те самые squiggle-сигналы.
Задачу перевода сигнала в последовательность решает Dorado — программа-бейсколлер от Oxford Nanopore Technologies:
- Входные данные: файлы .pod5.
- Анализ сигнала: нейросетевые модели анализируют «рисунок» тока для каждого прочтения (рида).
- Определение нуклеотидов: программа сопоставляет изменения тока с конкретными нуклеотидами и присваивает каждому основанию оценку качества (quality score).
- Выходные данные: файлы в формате unaligned BAM — сжатый бинарный формат с информацией о прочтениях и их качестве, пока без выравнивания на референсный геном.
Этап 1: Контроль качества и выбор референса
Очистка. Прочтения фильтруются от секвенаторных адаптеров и низкокачественных участков с помощью инструментов porechop_abi (ab initio — «с самого начала»: адаптеры определяются прямо из данных, без предварительного знания их последовательности) и NanoFilt.
Скрининг по базе. Очищенные риды выравниваются алгоритмом minimap2 на референсную базу геномов ВИЧ-1, охватывающую все известные субтипы.
Выбор лучшего референса. С помощью утилит samtools подсчитывается, к какому именно референсному геному выровнялось наибольшее количество ридов данного образца. Этот «победивший» геном становится опорной точкой для следующего этапа.
Этап 2: Сборка вирусного генома (reference-guided)
Точное выравнивание. Риды повторно выравниваются уже строго на выбранный лучший референс — это даёт значительно более высокое покрытие и точность по сравнению со скрининговым этапом.
Полировка нейросетью. Инструмент Medaka (разработан Oxford Nanopore Technologies) на основе нейросетей полирует черновую консенсусную последовательность: исправляет систематические ошибки нанопорового секвенирования, прежде всего в гомополимерных участках — местах, где один и тот же нуклеотид повторяется подряд несколько раз. Важно понимать: Medaka не собирает геном с нуля, а улучшает черновик, полученный из выравнивания.
Обрезка. Скрипт удаляет неопределённые участки (символы N) по краям сборки, чтобы они не нарушали рамки считывания генов на следующих этапах.
Этап 3: Определение субтипа ВИЧ (ML-модель 1)
Экстракция. Скрипт extract_env.py находит и вырезает ген env из собранного консенсуса.
Почему именно env? Ген env кодирует поверхностный гликопротеин gp120/gp41 — самый изменчивый регион генома ВИЧ-1, который мы разбирали во второй части. Именно здесь накапливается больше всего генетических различий между субтипами, что делает ген env наиболее информативным для их разграничения. В частности, это позволяет надёжно отделить субтип A6 — доминирующий в России и странах СНГ — от субтипа B, распространённого в Западной Европе и США, и от других мировых субтипов.
Анализ. Модель машинного обучения HIV-1-M-Env-Rus собственной разработки обрабатывает ген env и выдаёт предсказанный субтип вируса, а также степень уверенности модели в результате.
Этап 4: Анализ лекарственной устойчивости (ML-модель 2)
Экстракция. Скрипт extract_pol.py вырезает ген pol — точнее, три его функциональных зоны:
- PR (протеаза) — мишень ингибиторов протеазы (ИП),
- RT (обратная транскриптаза) — мишень НИОТ и ННИОТ,
- IN (интеграза) — мишень ингибиторов интегразы (ИИ).
Анализ. Модель HIV-1-Resist-Rus собственной разработки анализирует мутации в этих трёх зонах и выдаёт профиль чувствительности к четырём клинически приоритетным классам АРВТ: ингибиторам протеазы (ИП), нуклеозидным ингибиторам обратной транскриптазы (НИОТ), ненуклеозидным ингибиторам обратной транскриптазы (ННИОТ) и ингибиторам интегразы (ИИ). Именно эти четыре класса составляют основу большинства действующих схем терапии в России — остальные (ингибиторы входа, слияния, капсида), разобранные во второй части, применяются значительно реже и преимущественно в резервных схемах.
Этап 5: Финальные отчёты и принцип ALCOA+
Отчёты. Генерируются два HTML-документа:
- Технический отчёт (QC) — для биоинформатика или лаборанта: метрики качества секвенирования, покрытие генома, параметры сборки.
- Клинический отчёт — для врача: субтип вируса, профиль мутаций с цветовой индикацией (зелёный / жёлтый / красный), рекомендованные и нерекомендованные препараты.
Защита целостности данных — принцип ALCOA+. В медицинской и фармацевтической регуляторике существует стандарт целостности данных ALCOA+. Аббревиатура раскрывается так: Attributable (данные атрибутированы конкретному оператору), Legible (разборчивы), Contemporaneous (зафиксированы в момент получения), Original (не изменены), Accurate (точны); плюс Complete, Consistent, Enduring, Available — полны, согласованы, долговечны, доступны.
Для выполнения этих требований система автоматически вычисляет SHA-256 хэш итогового файла — уникальный «цифровой отпечаток» данных: если хотя бы один байт в файле изменится, хэш станет совершенно другим, что мгновенно сигнализирует о подделке. Система также фиксирует имя оператора, идентификатор устройства OnSiteSeq Edge и сохраняет неизменяемую копию в защищённый архив.
Вместо заключения
В самом начале этого выпуска прозвучала цитата: «Каждая смерть человека с ВИЧ - это несправедливость, иногда нелепость».
Биоинформатика не заменяет врача и не отменяет необходимость в АРВТ. Но она способна сделать лечение точнее. Вместо того чтобы методом проб и ошибок подбирать схему неделями, клиницист получает готовый профиль резистентности в день обращения пациента - и назначает именно ту схему, которая будет работать против конкретного штамма у конкретного человека.
Именно в этом смысл выражения «персонализированная медицина» применительно к ВИЧ. 30 тысяч смертей в год - это не абстрактная статистика эпидемии. Каждую из них можно попробовать предупредить, если поставить правильный диагноз вовремя.
В следующем выпуске разберём практическую часть работы, а также технические детали ML-моделей субтипирования и резистентности: как они устроены, на каких данных обучены и как валидированы.