Глубокой ночью 28 мая Anthropic выпустила последнюю версию своей флагманской модели Opus — Opus 4.8.
По сравнению с Opus 4.7, основное внимание этого обновления уделяется не только бенчмаркам модели, но и добавлению двух возможностей, непосредственно ориентированных на рабочий процесс разработчиков вокруг Claude Code: динамические рабочие процессы и более дешевый быстрый режим.
Динамические рабочие процессы позволяют Claude писать скрипты для оркестрирования задач, планирования и запуска десятков или сотен параллельных субагентов. В одном запуске максимальная одновременность субагентов составляет 16, а общее ограничение — 1000.
Быстрый режим в основном предназначен для сценариев, более чувствительных к скорости и пропускной способности. Он позволяет Opus работать с выходной скоростью в 2,5 раза выше, сохраняя при этом ту же качество; на Opus 4.8 цена быстрого режима снизилась до одной трети от предыдущей цены, однако перед использованием требуется активировать usage credits.
Тестирование показало, что Opus 4.8 не только превосходит предыдущее поколение моделей, но и опережает GPT-5.5 и Gemini 3.1 Pro. Однако в категории agentic terminal coding модель OpenAI по-прежнему сохраняет лидерство. В день выпуска обычная цена режима Opus 4.8 была такой же, как у Opus 4.7 — по 5 долларов за миллион входных токенов и 25 долларов за миллион выходных токенов.
Три ключевых момента обновления Claude Opus 4.8
Это обновление Opus 4.8 можно охватить тремя ключевыми словами: динамические рабочие процессы, контроль интенсивности мышления и более дешевый быстрый режим. Первые два напрямую влияют на масштаб задач, которые может обрабатывать Claude Code, и способ их выполнения; последний связан с задержкой и стоимостью.
Сначала рассмотрим динамические рабочие процессы.
Динамические рабочие процессы по сути представляют собой скрипт JavaScript, используемый для крупномасштабной оркестрации субагентов. После описания задачи пользователем Claude напишет для этой задачи скрипт, который затем выполняется средой выполнения в фоновом режиме. Одновременно с этим текущий сеанс пользователя может оставаться отзывчивым и не зависнет, пока агенты работают в фоне.
Ключевое изменение заключается в том, что планирование задач переместилось в код вместо того, чтобы оставаться в контекстном окне Claude. Промежуточные результаты также сохраняются в переменных скрипта. Таким образом, контекст Claude содержит только финальный ответ. Это главное отличие динамических рабочих процессов от субагентов и навыков.
Эта функция требует использования Claude Code v2.1.154 или более поздней версии. Она может работать в CLI, Desktop и плагине VS Code и доступна для планов Max, Team и Enterprise. В планах Max и Team она включена по умолчанию; в плане Enterprise её необходимо включить администратору. Она также может работать на Claude API, Amazon Bedrock, Vertex AI и Microsoft Foundry.
Пользователи могут запустить рабочий процесс двумя способами. Первый — включить слово workflow в любом месте prompt. Второй — включить параметр под названием ultracode. Ultracode объединяет уровень推理xhigh с автоматической оркестрацией рабочих процессов. Claude Code также имеет встроенный deep-research, который сам по себе является предустановленным рабочим процессом.
Когда рабочий процесс запускается, Claude динамически планирует задачи на основе пользовательского prompt. Она разбивает задачу на подзадачи и распределяет работу между параллельно работающими субагентами. Эти агенты обрабатывают проблему с независимых точек зрения, в то время как другие агенты пытаются опровергнуть эти выводы. Весь процесс выполнения постоянно повторяется, пока ответ постепенно сходится. Прежде чем результат будет включен в финальный результат, он проходит проверку.
Среда выполнения применяет явные жесткие ограничения. Она позволяет одновременно запускать максимум 16 агентов, с общим лимитом агентов в одном запуске составляющим 1000. Сам скрипт рабочего процесса не может получить доступ к файловой системе или оболочке; только агенты могут читать, писать файлы и выполнять команды.
По мере хода выполнения прогресс сохраняется. Если задача прерывается в процессе, её можно возобновить в том же сеансе. Уже завершённые агенты вернут кэшированные результаты при возобновлении. Поскольку координация происходит вне разговора, план задач легче остаётся стабильным и не будет постоянно разбавляться или отвлекаться контекстом сеанса.
Anthropic подробно продемонстрировала крупный пример. Jarred Sumner использовал динамические рабочие процессы для портирования Bun, миграции Bun с Zig на Rust. Эта версия портирования прошла 99,8% существующего набора тестов, сгенерировала примерно 750 000 строк кода Rust, от первого коммита до окончательного слияния потребовалось 11 дней.
Один рабочий процесс отвечал за правильное отображение времени жизни Rust для каждого поля struct; следующий рабочий процесс преобразовал каждый файл .rs в соответствующую версию портирования. Сотни агентов работали параллельно, и у каждого файла было двое рецензентов. Впоследствии цикл исправлений постоянно управлял построением и набором тестов, пока всё не было очищено. Однако этот результат, хотя уже объединён, в настоящее время не попал в производственную среду.
Второй ключевой момент — теперь пользователи могут контролировать интенсивность мышления Claude.
Новый элемент управления означает, что пользователи могут увеличить или уменьшить ресурсы рассуждения, которые Claude инвестирует в задачу. Anthropic в объявлении в блоге объясняет, что когда пользователь просит Claude полностью справиться с задачей, он "будет думать чаще и глубже, чтобы дать лучший ответ". И наоборот, при более низкой интенсивности мышления Claude будет реагировать быстрее, в то время время потребления пользовательского rate limit также будет замедлено.
Для пользователей, которые уже чувствуют, что услуги AI повышают цены за счёт сокращения квот, и беспокоятся, что квоты закончатся быстрее, чем ожидается, это может быть хорошей новостью.
Третий ключевой момент — снижение цены быстрого режима.
Anthropic значительно снизила цены быстрого режима Opus 4.8. В быстром режиме модель генерирует токены примерно в 2,5 раза быстрее, чем обычно; цена быстрого режима Opus 4.8 снизилась до 10 долларов за миллион входных токенов и 50 долларов за миллион выходных токенов, что ниже, чем у Opus 4.7 с 30 долларов / 150 долларов.
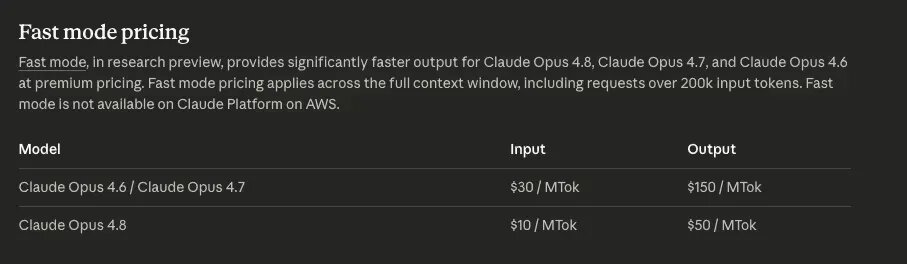
Это эквивалентно снижению цены быстрого режима предыдущей модели в 3 раза, что также делает высокопроизводительный вывод более близким к рабочим нагрузкам, чувствительным к задержке.
Быстрый режим уже можно использовать в Claude Code с помощью команды /fast; доступ API в настоящее время всё ещё ограничен и требует регистрации на ожидание по адресу claude.com/fast-mode.
В обычном режиме Claude Opus 4.8 по-прежнему остаётся одной из дорогих передовых моделей, но его цена всё ещё ниже, чем у основного конкурента OpenAI GPT-5.5.
Однако помимо скорости, стоимости и возможностей кодирования, Opus 4.8 на этот раз также пытается ответить на другой вопрос: может ли ИИ быть более честным.
В современной конкуренции больших языковых моделей становится всё труднее избежать одного момента: на самом деле очень сложно найти по-настоящему "честный" ИИ. У древнегреческого философа Диогена есть знаменитая легенда: он однажды днём брал зажженную лампу и ходил по улицам Афин в поисках, говоря, что он ищет честного человека. Если применить эту историю к сегодняшнему дню, то люди ищут, вероятно, не только честного человека, но и честный ИИ.
Модель может быть умнее, быстрее и лучше писать код, но может ли она признать, что что-то не знает, может ли она обнаружить, что написала неправильно, может ли она оставаться честной, когда пользователю больше всего нужен суд, - это становится более редкой способностью. Это также направление, которое Anthropic хочет подчеркнуть на этот раз. Opus 4.8 описывается Anthropic как более поддерживающий пользователя и менее обманывающий пользователя.
Команда Alignment компании Anthropic в объявлении в блоге сообщила, что эта модель "достигла новых вершин по нашим показателям просоциального поведения". В частности, Anthropic утверждает, что Opus 4.8 улучшился в поддержке автономии пользователя и действиях в соответствии с наилучшими интересами пользователя.
Ещё одно позитивное изменение заключается в том, что Anthropic сообщает, что уровень обмана в Opus 4.8 и доля соответствия злоупотреблениям запросов "значительно ниже", чем в предыдущей модели. Это, похоже, означает, что она уже догнала Claude Mythos Preview. Anthropic ранее назвала Claude Mythos Preview "моделью с наивысшей степенью выравнивания, которую мы когда-либо обучали".
Anthropic также заявляет, что Opus 4.8 "примерно в четыре раза менее вероятно игнорировать недостатки в коде, который он написал, без объяснений" по сравнению с предыдущей моделью. Anthropic утверждает, что это также подтвердили ранние тестеры, описав Opus 4.8 как "более надёжный и более проницательный в суждениях" при выполнении agentic задач. Другими словами, Opus 4.8 пытается решить не только то, может ли модель выполнить задачу, но и готова ли она указать на риски, признать проблемы и, если необходимо, наоборот напомнить пользователю.
Бенчмарки: "серьёзная стратегическая ошибка"?
Судя по результатам бенчмарков, как Opus 4.8 работает по сравнению с другими моделями? Anthropic заявляет, что Opus 4.8 превосходит предыдущее поколение во всех бенчмарках. Хотя бенчмарки, опубликованные в день выпуска, не обязательно всегда соответствуют реальному опыту использования, эти цифры действительно показывают определённый потенциал.
Самым примечательным является то, что Opus 4.8 достигает 69,2% в agentic coding, что явно выше, чем Opus 4.7 с 64,3%, а также превышает GPT-5.5 с 58,65% и Gemini 3.1 Pro с 54,2%. Его показатель в agentic compute use составляет 83,4%, что по сравнению с 78,7% у GPT-5.5 и 76,2% у Gemini 3.1 Pro также достойно внимания. Однако в agentic terminal coding Opus 4.8 всё ещё проигрывает GPT-5.5, отставая на 3,6 процентных пункта от модели OpenAI.
Однако именно это сравнение также вызвало дискуссию в сообществе о надёжности бенчмарков.
Особенно в сообществе разработчиков впечатление от кодирования GPT-5.5 получает очень позитивные отзывы. DHH сегодня выразил это на X, сказав, что со времён Opus 4.5 ни одна модель не заставляла его повторно испытывать момент "я не верю, что это уже так хорошо" как GPT-5.5.
Именно в этом контексте автор Redis antirez критикует способ представления Anthropic бенчмарков. Он считает, что Anthropic совершила "серьёзную стратегическую ошибку": в прошлом производители обычно больше подчеркивали улучшения новой модели по сравнению со старой, но на этот раз, когда многие люди уже почувствовали сильные возможности кодирования GPT-5.5, Anthropic поместила GPT-5.5 в один и тот же набор сравнений, что фактически позволило клиентам увидеть, что между бенчмарками и реальным опытом использования может быть несоответствие.
Кто-то в комментариях возразил, разве это не прозрачность? Ответ antirez состоит в том, что проблема не в прозрачности, а в том, что если Anthropic знает, что GPT-5.5 намного сильнее, чем Opus 4.7 в кодировании, даже если последний получает более высокие баллы в некоторых бенчмарках, но по-прежнему представляет эти цифры как доказательство "модель сильнее", это запутает пользователей.
Другой пользователь указывает, что главные модели обычно размещают последние флагманские модели Big Three в сравнительных диаграммах при выпуске, и Anthropic не является исключением. antirez затем отметил, что это не меняет основную проблему: пользователи видят несоответствие между заявлением производителя и реальным опытом.
Пользователь Chubby прокомментировал, что Opus 4.8 явно очень сильная модель, но его впечатление состоит в том, что Anthropic всё больше похожа на преследование OpenAI, а не на продолжение определения темпа.
По его мнению, GPT-5.5, похоже, снова поднял планку; если OpenAI будет поддерживать такой темп продвижения, GPT-5.6, вероятно, станет целостно более мощной моделью.
Opus за этот год: от "получения королевской власти" к спорам о скрытом повышении цен
В мае 2025 года Anthropic выпустила Opus 4 на своей первой конференции для разработчиков Code with Claude и назвала его "лучшей моделью кодирования в мире". В то время компания обещала установить новые стандарты в кодировании, расширенном рассуждении и ИИ агентах. Эта модель принесла значительный прогресс в кодировании и долгоконтекстном рассуждении, особенно выдающимся было то, что она могла обрабатывать долгосрочные задачи и сохранять контекст в "тысячах шагов", как тогда утверждала Anthropic.
Вскоре в августе 2025 года выпустили Opus 4.1, что принесло некоторые улучшения в возможностях agentic задач, кодирования и рассуждения. Но это было только небольшое обновление. Тогда Anthropic также предупредила, что "в ближайшие недели мы внесём гораздо большие улучшения в модель".
В ноябре 2025 года высокопрофильно выпустили Opus 4.5. Anthropic снова назвала его "лучшей моделью в мире для кодирования, агентов и computer use". Точно так же они снова затанцевали в воздухе, утверждая, что Opus 4.5 — это только "предпросмотр гораздо больших изменений в способе выполнения работы". Для самого предпросмотра Opus 4.5 действительно принес некоторые улучшения способностей, позволяя модели лучше справляться с неоднозначностью и решать ошибки, связанные с несколькими системами. Со многих сторон, после того как GPT-5.1-Codex-Max компании OpenAI и Gemini 3 компании Google завоевали популярность на рынке, Opus 4.5 помог Anthropic вернуть корону кодирования.
Спустя ещё три месяца Anthropic выпустила Opus 4.6. Opus 4.6 "вызвал скачкообразное изменение в использовании больших языковых моделей для рабочих процессов предприятия, потому что он может обрабатывать более сложные задачи и лучше доставлять результаты". Opus 4.6 продолжает улучшать возможности планирования, кодирования и отладки, став первой моделью Anthropic с использованием adaptive thinking и достигла впечатляющих результатов бенчмарков. Особенно примечательно, что она имеет контекстное окно в 1 миллион токенов.
Однако противоречия Opus 4.6 быстро появились. После выпуска Anthropic быстро подверглась критике за корректировку цен: хотя модель технически поддерживает запрос, близкий к 1 миллиону токенов, как только запрос превышает примерно 200 000 токенов, весь запрос будет включён в более высокий ценовой уровень "долгого контекста".
Opus 4.7 также столкнулся с некоторыми проблемами. Она была выпущена в апреле 2026 года, как прямое обновление Opus 4.6, приносящее лучшие зрительные способности, лучшую память и лучшее соблюдение инструкций. Однако после выпуска некоторые пользователи сообщили, что Claude Opus 4.7 будет давать противоречивые ответы, и производительность также снизилась, что вызвало обсуждения в сообществе о качестве модели, компромиссах безопасности и скрытом повышении цен услуг ИИ. Ещё более неловко, что сама Anthropic сказала, что Opus 4.7 "целостно не так мощна", как обсуждаемый в то время Claude Mythos Preview. Судя по внешним отчётам, Opus 4.7 в некоторой степени была похожа на тестирование новых механизмов кибербезопасности сети Mythos.
Теперь Opus 4.8 официально выпущена. Для Anthropic, которая недавно неоднократно разочаровывала пользователей, это действительно важная точка. С одной стороны, ей нужно доказать, что серия Opus может продолжать продвигаться в кодировании и agentic задачах; с другой стороны, ей также нужно ответить на постоянное недовольство пользователей относительно квот, цен, стабильности моделей и опыта продукта.
Ранее в этом месяце Claude Code agent view, представленный Anthropic, не купил разработчиков. Некоторые люди оценили это как "уменьшение некоторых трений, но не изменение основных проблем". Той же неделей Anthropic также объявила, что с 15 июня она начнёт раздельное выставление счётов за использование Agent SDK. Для пользователей, которые уже привыкли включать программное обеспечение и интерактивное использование в одну квоту подписки, это явно не приветствуемое изменение.
Конечно, Opus 4.8 может быть не единственной картой, которую Anthropic разыграет в дальнейшем. В том же сообщении об утечке ранее также упоминались Sonnet 4.8 и Mythos 1; если эти два имени также будут последовательно высадиться, Anthropic действительно вступит в следующий цикл обновления продукта.
Справочные ссылки:
- https://www.anthropic.com/news/claude-opus-4-8
- https://www.marktechpost.com/2026/05/28/anthropic-ships-claude-opus-4-8-alongside-dynamic-workflows-and-cheaper-fast-mode-with-workflows-capped-at-1000-subagents/
Александр — сооснователь RockAPI, эксперт в области ИИ и разработки API. RockAPI предоставляет неограниченный доступ к передовым моделям ИИ, таким как DeepSeek, GPT-4o, Claude и Gemini, с простой интеграцией и гибкими способами оплаты. Зарегистрируйтесь на https://www.rockapi.ru/ и получите бесплатный стартовый кредит для новых пользователей — начните свое путешествие в мир ИИ уже сегодня!