MiniMax выкатила M3 — coding‑модель под длинные агентные сессии, а не просто очередной чат для автокомплита.
⠀
Главное: M3 поддерживает контекст до 1 млн токенов через новую архитектуру MiniMax Sparse Attention. Модель мультимодальная: работает с текстом, изображениями, видео и computer use. В API, AI Arena и MiniMax Code она уже доступна, а веса и технический отчёт MiniMax обещает выложить в течение 10 дней.
Хорошая замена для рабочей лошадки MiniMax 2.7. И тоже есть high speed режим, только не забудьте включить reasoning high, чтобы увеличить лимит токенов по каждому обращению.
⠀
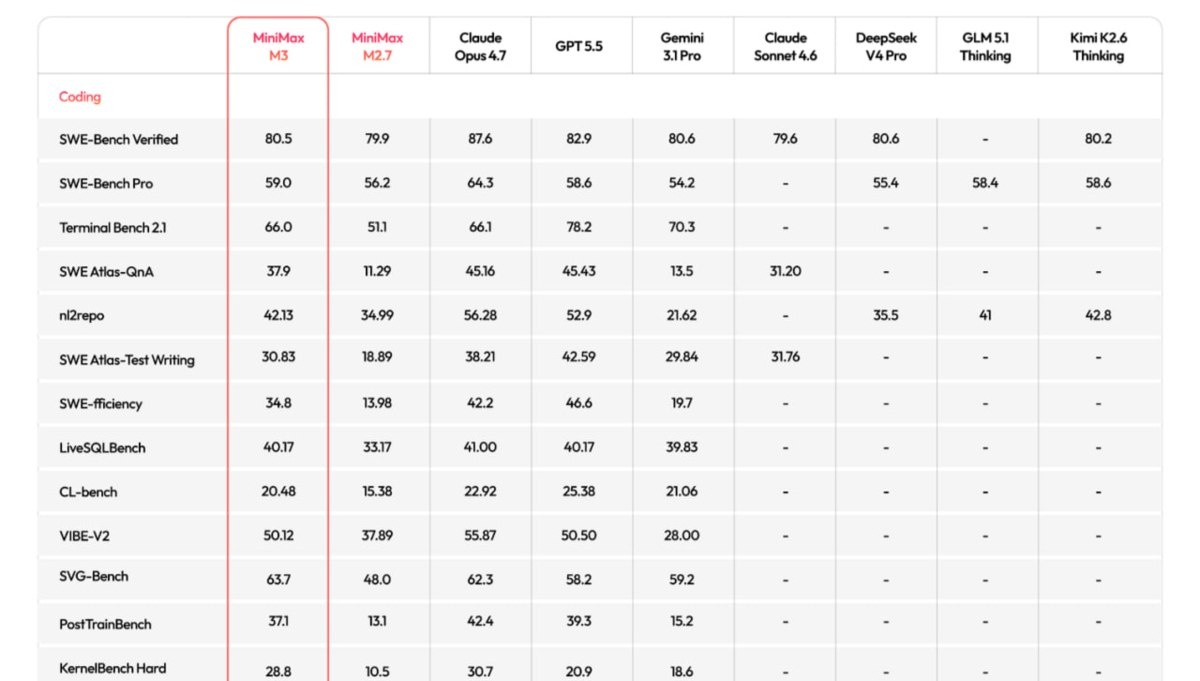
По таблице бенчмарков выглядит сильно. MiniMax заявляет 59.0% на SWE-Bench Pro, 66.0% на Terminal-Bench 2.1, 80.5% на SWE-Bench Verified. На SWE-Bench Pro M3, MiniMax пишет, обходит GPT-5.5 и Gemini 3.1 Pro, но уступает Claude Opus 4.7. В SVG-Bench M3 уже выше Opus 4.7.
⠀
С этими цифрами хочется кричать «новый лидер рынка». Но это внутренние тесты MiniMax, часть сравнений неполная, у некоторых моделей в таблице стоят прочерки. Но китайская лаборатория вытащила coding‑модель в диапазон топовых закрытых систем и сразу упаковывает её в агентный продукт.
⠀
MiniMax Code теперь построен вокруг M3. Там есть Agent Team: модель делит большую задачу на параллельные подзадачи, запускает субагентов, проверяет результат и корректирует план по ходу работы. Это уже ближе к «агент ведёт проект», чем к «модель пишет функцию по промпту».
⠀
В релизе MiniMax приводит два показательных сценария. В первом M3 почти 12 часов автономно воспроизводила исследовательскую работу ICLR 2025 про finetuning dynamics, сделала 18 коммитов и 23 экспериментальные фигуры. Во втором 24 часа оптимизировала FP8 GEMM kernel под Nvidia Hopper: 147 benchmark submissions и 1959 tool calls.
⠀
Это тот класс задач, где обычный coding‑чат ломается. Нужна длинная память, умение держать логи/код/статью/ошибки в одном контексте, плюс привычка не останавливаться после первого неудачного запуска.
⠀
Если веса реально откроют в ближайшие дни, M3 станет интересной не только как API‑модель, но и как база для локальных/частных coding‑агентов. Особенно если MSA даст обещанную экономику длинного контекста: MiniMax пишет, что на 1M context per-token compute примерно в 20 раз ниже, чем у предыдущего поколения.
⠀
Слабые места: независимых прогонов пока мало, методика бенчей частично внутренняя, веса ещё не опубликованы. Релиз всё равно выглядит хорошо: MiniMax догоняет чат‑модели и одновременно собирает связку «модель + агентный coding‑инструмент + длинный контекст + computer use».
Я использую MiniMax на множестве задач, не требующих GPT. В частности, бот нашего воркшопа работает на этой модели и все мои кроны на основном боте. Лимиты за 40 долларов просто бездонные. Поделюсь результатами в ближайшие дни.
🧩📣🔥💡🪄
⠀
Источник: https://www.minimax.io/blog/minimax-m3
Инструменты и кейсы: @human20
Внедрение: human20.app