Что сочетается с конкретным ингредиентом? Ответ зависит от того, ищете ли вы компаньона по поиску рецептов или того, кто понимает по вкус. Предыдущие модели ИИ сочетали эти два компонента. Стартап Kaikaku.ИИ разделяет обе точки зрения в новом исследовании.

Фото создано моделью Nano Banana 2 через сервис от KolerskyAI
В "Epicure" Якуб Радзиковски и Джозеф Чен представляют три почти идентичные модели ИИ. Они отличаются только данными обучения. Первая модель, "Cooc", видит только то, какие ингредиенты присутствуют вместе в реальных рецептах. Вторая, "Chem", видит только то, какие вкусовые молекулы у ингредиентов общие, опираясь на химическую базу данных FlavorDB. Третье, "Ядро", сочетает в себе и то, и другое.
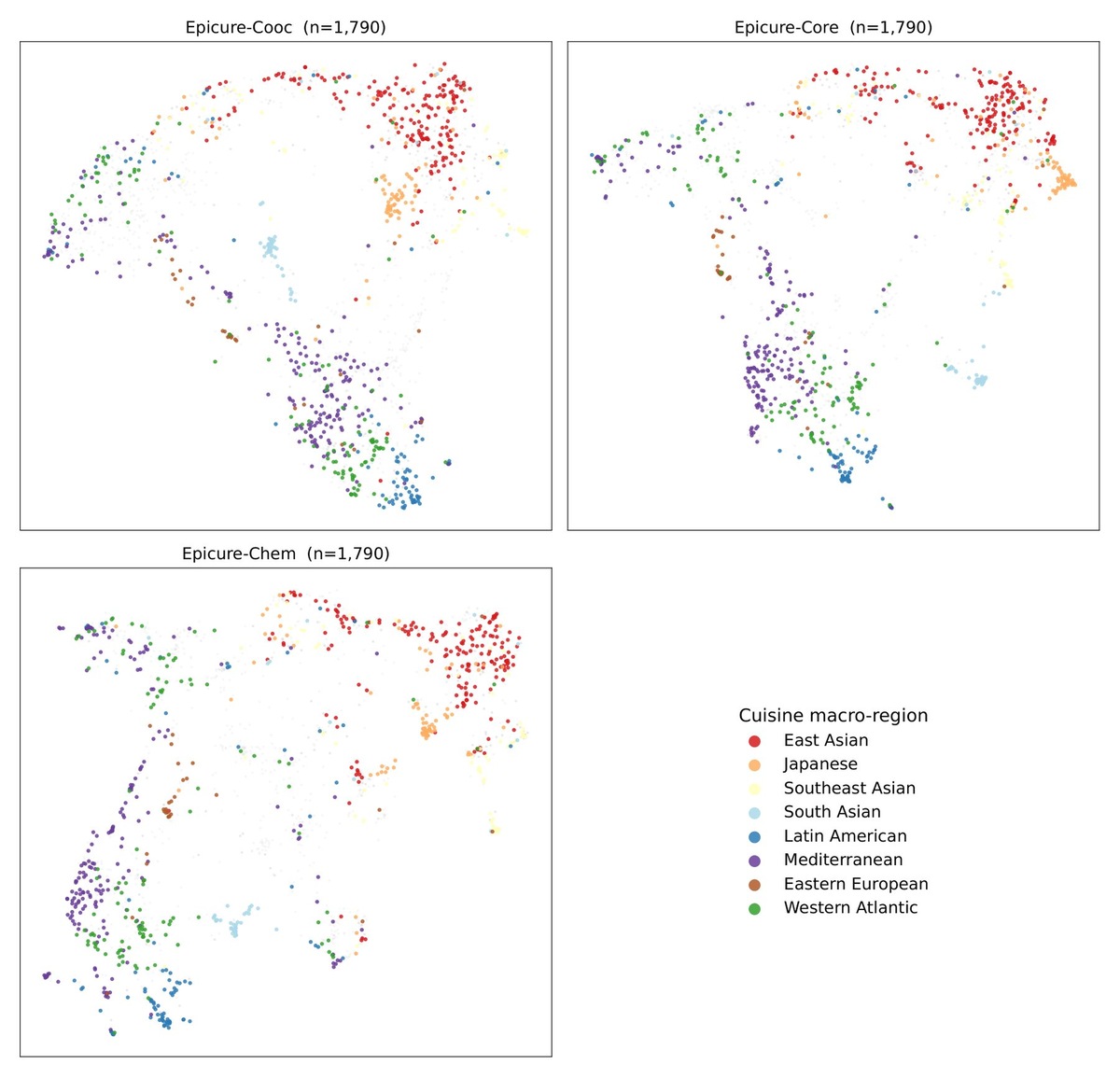
Один и тот же вопрос, три варианта ответа
Разница проявляется в конкретных запросах. Введите "курица", и Cooc вернет чеснок, лук и черный перец - ингредиенты, которые часто появляются рядом с ними в рецептах. Chem предлагает говядину или свинину, ингредиенты с похожими вкусовыми качествами. К "базилику" в Cooc подают петрушку, оливковое масло и пармезан - типичную пасту из макаронных изделий. В Chem подают орегано, эстрагон и розмарин, родственные травы.
По мнению авторов, модель, основанная на химии, также лучше работает в областях, где у нее не должно быть никакой информации. Вкусы, такие как сладкий, кислый или горький, и пищевая ценность, такая как содержание белка или жира, напрямую не кодируются в данных обучения. Тем не менее, Chem классифицирует ингредиенты по этим осям более четко, чем в других вариантах. Химические взаимосвязи, по-видимому, действуют как ярлык, который также настраивает модель на другие кулинарные концепции.
Многоязычный корпус вместо английского-много данных
Фото создано новой моделью gpt-image-2 через сервис от KolerskyAI
Самая полная общедоступная модель ингредиентов на сегодняшний день, FlavorGraph, построена на англоязычном сборнике рецептов. Epicure, напротив, обрабатывает 4,14 миллиона рецептов из одиннадцати источников на семи языках. К ним относятся китайский, русский, вьетнамский, турецкий, индонезийский и немецкий языки. Конвейер, построенный на внедрениях Claude и Gemini, переводит и очищает около 200 000 необработанных терминов, таких как варианты написания, названия брендов и инструкции по приготовлению, в 1790 чистых ингредиентов.
Тем не менее, корпус по-прежнему распределен неравномерно. Примерно половина материала взята из восточноазиатских источников, в то время как доля блюд латиноамериканской, восточноевропейской и южноазиатской кухонь составляет однозначные проценты. Только около трети ингредиентов напрямую закреплены в химической базе данных. Остальные улавливают химический сигнал косвенно, через родственные ингредиенты.
Набирайте направление
В готовой модели предусмотрено два режима работы. Первый - это простой поиск по соседству: какие ингредиенты наиболее близки к заданному? Второй позволяет пользователям сдвигать начальный ингредиент на регулируемый угол в заданном направлении. При нулевой температуре оригинал остается нетронутым. При шестидесяти градусах преимущество переходит к целевому району.
Слегка поверните "рис" в сторону Южной Азии, и появятся листья карри, урад дал, чана дал и семена пажитника. Используйте слово "курица" в большей степени для приготовления блюд западноатлантической кухни, и вы получите куриный суп-пюре, роллы "полумесяц" и заправку "ранчо" - типичные продукты домашней кухни США.
Выбор модели может даже решить, из какой культуры получен ответ. Замените "шоколад" на "сладкую выпечку", и Cooc и Core будут использовать западные ингредиенты для выпечки, такие как какао, ваниль и разрыхлитель. Chem предлагает восточноазиатский десертный кластер с пастой из красной фасоли, порошком матча и фиолетовым сладким картофелем. Выбор модели также определяет культурную принадлежность ответа.
Авторы создают рестораны-роботы
За исследованием стоит стартап ресторанных технологий. Kaikaku была основана в Лондоне в 2023 году и управляет собственным роботизированным рестораном Common Room, в центре Брансуика, с планами расширить его до сети.
Компания использует собственные системы машинного обучения для взвешивания и порционирования ингредиентов. Ее машина под названием "Fusion" теоретически может выдавать 360 мисок в час. Система также включает в себя управление запасами на основе ML и 3D-печатные компоненты, безопасные для пищевых продуктов. Компания собрала около 1,8 миллиона долларов в ходе предварительного отбора в 2024 году.
Учитывая этот опыт, интерес к машиночитаемой карте мира ингредиентов имеет смысл. Модель, которая переключается между сопутствующими рецептами и вкусовыми аналогами по запросу, переводит ингредиенты в разных кухнях или сдвигает их по таким осям, как "жирный" или "ферментированный", была бы полезна в нескольких местах. Это может помочь в разработке меню в ресторане bowl, предложить замены при нехватке поставок или помочь при перемещении в новые места.
Работает ли это на практике, еще предстоит выяснить. Веса моделей и наборы данных теперь доступны на Hugging Face, что в принципе делает возможной независимую проверку. Но примеры, приведенные в статье, подобраны вручную. В малопредставленных регионах, таких как Южная Азия или Латинская Америка, ответы, вероятно, гораздо менее стабильны, чем для доминирующих восточноазиатских и западных кухонь.
Очистка словарного запаса также зависит от результатов языковых моделей, которые несут в себе свои культурные предубеждения. Тот факт, что шоколад оказывается рядом с маття в направлении "сладкая выпечка" в одном из вариантов модели, является приятным эффектом. Но это мало что говорит о том, насколько надежно работают такие ротации, за исключением примеров с отбором вишни.
Соавтор Джозеф Чен продвигает модель на X как "самую большую многоязычную модель питания, когда-либо созданную", говоря, что "вся готовка человека сжата в 2 мегабайта". Более старая версия модели доступна в виде демо-версии на epicure.kaikaku.ai.