MiniMax M3: 1М контекста, Sparse Attention и конец китайской халявы ☹️
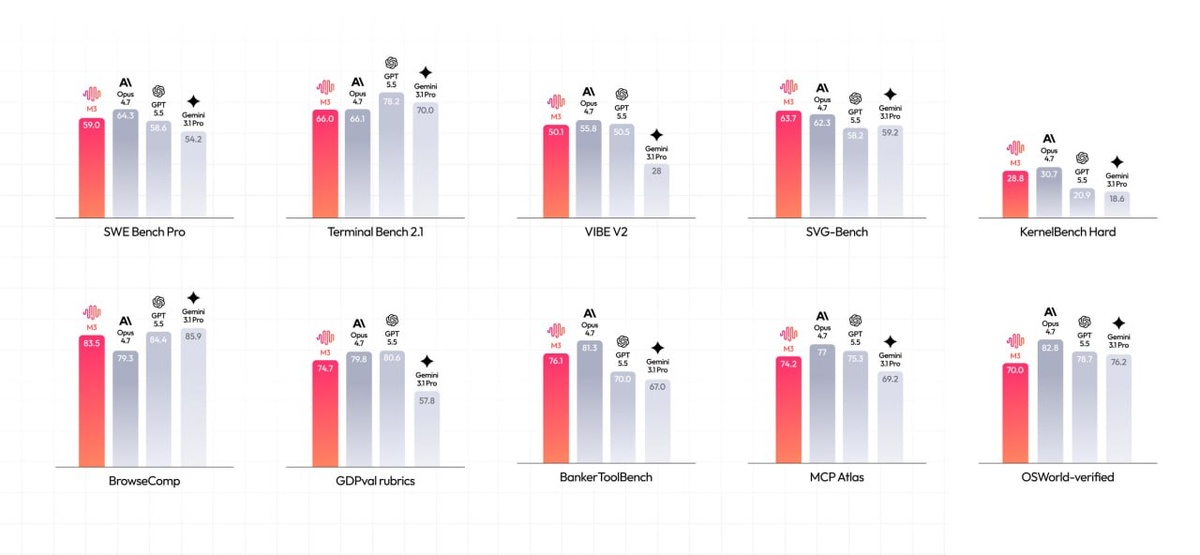
Выкатили MiniMax M3. По заявленным бенчмаркам (SWE-Bench Pro 59.0%) они бьют Gemini 3.1 Pro, GPT-5.5 и дышат в спину Claude Opus 4.7. Но мы с вами знаем реальную цену синтетическим пузомеркам. Намного интереснее то, что у модели под капотом, и как разработчики решили монетизировать этот праздник интеллекта.
Инженерно ребята сделали очень крутую вещь — замахнулись на честный и рабочий 1M контекст. Чтобы избежать проклятия квадратичной сложности классического attention, они выкатили свою архитектуру — MSA (MiniMax Sparse Attention).
Суть в умной предварительной фильтрации: KV бьется на блоки, читается ровно один раз, а память запрашивается непрерывно.
👉🏻 На практике это означает, что на контексте в 1M вычисления на токен стали в 20 раз дешевле, чем у их прошлой модели.
Второй важный момент — фокус на долгосрочных агентских задачах.
Большинство текущих тестов кодеров — это одноразовая генерация бойлерплейта. MiniMax же обучали модель на интерактивном симуляторе многошаговой коллаборации.
Они заставили M3 оптимизировать FP8 GEMM CUDA-ядро под архитектуру Hopper. С нуля, без референсов, только документация и неработающий скелет. Модель долбилась сутки, сделала 1959 вызовов тулзов и прошла через кучу плато. Там, где другие модели (даже хваленый Opus) упирались в стену и отваливались, M3 продолжал искать новые пути оптимизации и на 145-й попытке выдал результат, подняв утилизацию железа с 7.6% до 71.3%. Способность модели держать в памяти огромную простыню логов, метрик и неудачных кусков кода — вот где 1M контекста реально окупается.
Из приятных мелочей: режим "thinking" для сложных задач можно включать и выключать в API без изменения тарификации, а их десктопная приложуха MiniMax Code теперь нативно работает с мультимодальностью и может шариться по вашему компу (например, переносить данные из Excel в ERP).
А теперь опустимся на землю 🛬
Я сам недавно сел на их Token Plan. Главная причина — это было тупо дешевле. На рынке подписок почти вымерли тарифы за $10, а у MiniMax он был, и для многих повседневных задач его хватало за глаза.
Но законы юнит-экономики не обманешь. Вместе с релизом новой модели аттракцион невиданной щедрости закрылся. Тариф за $10 просто выпилили. Теперь порог входа — классические $20 в месяц, а лимиты использования стали ощутимо жестче.
Сначала демпингуем, прикармливаем аудиторию, а как только выкатываем реально конкурентную флагманскую модель — закрываем лавочку и начинаем стричь базу. Эх.