Перевод статьи I Spent 6 Months Tuning Claude Code. Here's the Exact Setup That Finally Worked. с Medium.
CLAUDE.md, subagent, hook, skill, worktree и пять MCP-серверов, которые оправдывают своё место
Откройте терминал. Перейдите в свой основной ИИ-проект. Выполните tree .claude
Для большинства инженеров, использующих Claude Code прямо сейчас, ответ — «command not found» или один файл с расплывчатой инструкцией писать чистый код. Это нормально. Но это также оставляет примерно 80% возможностей продукта неиспользованными.
Вот как выглядит та же команда в репозитории, настроенном опытным пользователем.
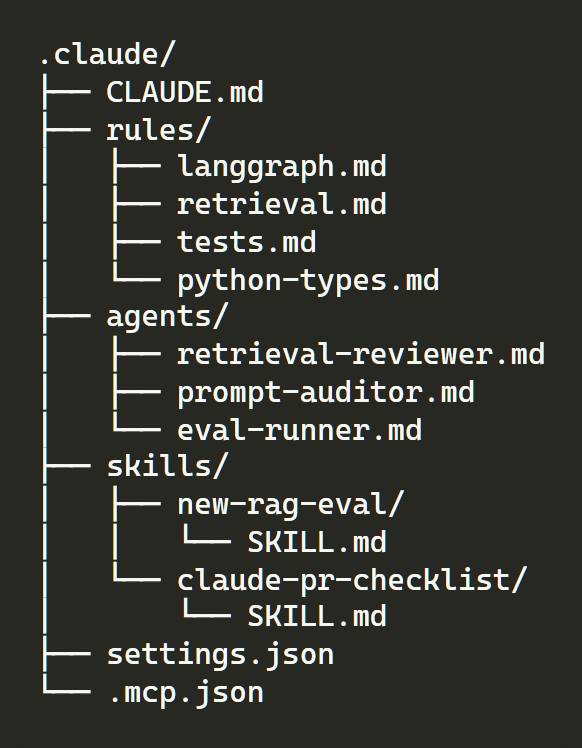
Ни один из этих файлов не является длинным. Основной файл памяти намеренно содержит менее 500 токенов. Каждый файл правил — это короткое поведение, ограниченное путём. Каждый subagent — возможно, тридцать строк. Конфигурация хуков в файле настроек — один pre-tool gate и один post-tool formatter. Конфигурация серверов содержит пять серверов вместо пятнадцати.
Представьте двух инженеров, выполняющих одну и ту же задачу. Им нужно добавить генерацию ответов с цитированием в существующий сервис поиска. Им также нужно написать оценки и открыть PR в основную ветку.
У одного инженера пустая папка. У другого — дерево выше и настроенный headless-режим. Первый инженер тратит вторую половину дня на функцию, которая сдаётся вечером. Второй инженер сдаёт pull request за тридцать минут. Разница не в том, какие промпты они вводят. Разница в стеке конфигурации, который никто не удосужился настроить.
Начните с файла памяти, потому что каждый следующий слой становится дешевле, когда этот короткий.
Слой 1: Иерархия памяти
Claude Code использует пятиуровневую иерархию памяти. У вас есть личные предпочтения в домашней директории, корневой файл проекта, правила, ограниченные путём, локальные незафиксированные переопределения и автоматические записи памяти для каждой сессии.
Корневой файл проекта загружается при каждом запуске сессии. Он постоянно расходует токены. Многие команды сбрасывают в этот файл всю свою инженерную вики, используя его как векторную базу данных вместо горячего кэша.
В моих рабочих нагрузках частота попаданий в кэш заметно падает после ~500 токенов. Новый токенизатор Opus 4.7 отображает существующие промпты примерно в 1.0–1.35x больше токенов, что означает, что та же рабочая нагрузка теперь дороже, если вы строго не контролируете свой окружающий контекст.
Держите файл менее 200 строк. Делайте его императивным. Не пишите описательные рекомендации вроде «пишите чистый код». Пишите буквальные правила, например «все функции должны иметь аннотации типов TypeScript». Каждая строка должна реально менять поведение.
Вот минимальный файл для нашего RAG-сервиса.
Это сообщает агенту, что делают директории. Определяет строгий контракт цитирования между узлом поиска и узлом ответа. Устанавливает жёсткие ограничения для тестового набора, предотвращающие галлюцинирование сетевого мока моделью.
Слой 2: Правила, ограниченные путём
Как только вы дисциплинируете корневую память, у вас всё ещё остаются инструкции для конкретных файлов. Вы помещаете их в правила, ограниченные путём.
Шаблон использует YAML frontmatter. Вы определяете массив glob-путей. Инструмент загружает файл правил только тогда, когда он касается соответствующего файла. В остальное время это не расходует токены. Если агент редактирует скрипты миграции базы данных, ему не нужно читать соглашения по стилю фронтенда.
(Примечание: хотя paths: является документированным ключом схемы, текущие версии иногда его пропускают из-за известной ошибки. Использование globs: или CSV-формата работает более надёжно на практике, если вы замечаете, что ваши правила молча игнорируются).
Вот файл правил для нашего сервиса поиска.
Три или четыре коротких файла правил превосходят один большой корневой файл. Экономия токенов накапливается на каждом шаге разговора.
Слой 3: Plan Mode
Большинство людей никогда не используют Plan Mode в продакшене. Они вводят промпт и сразу наблюдают изменения файлов.
Plan Mode разделяет мышление и действие. Он удерживает исследование вне основного контекста выполнения и создаёт явный документ плана, который вы можете просмотреть и изменить до того, как произойдут какие-либо деструктивные действия.
Claude Code предлагает три уровня планирования. Simple Plan обрабатывает короткие задачи в одном файле. Visual Plan отображает многофайловые изменения, где важна структура. Deep Plan обрабатывает изменения в нескольких сервисах и рискованные рефакторинги.
Deep Plan использует subagent для оценки рисков и архитектурного обзора. Планирующий subagent по замыслу доступен только для чтения. Ему явно запрещены права на запись и редактирование. Он не может случайно изменить вашу кодовую базу, пока отображает зависимости.
В нашем примере с RAG-сервисом мы используем Deep Plan для отслеживания существующего пути генерации ответов. Исследовательский subagent извлекает соответствующие файлы в короткий контекст. Планировщик выводит явный список правок, перечисляет дополнения к оценкам и составляет описание pull request. Вы просматриваете план и фиксируете его. Фактические изменения происходят только после выхода из Plan Mode.
Слой 4: Пользовательские subagent
Subagent — самая недооценённая функция в инструменте.
Инструмент поставляется со встроенными subagent. Исследовательский агент обрабатывает поиск по кодовой базе только для чтения. Агент общего назначения обрабатывает многошаговую работу, требующую чистого контекста. code-reviewer и code-architect выполняют специализированные роли.
Вы пишете пользовательский subagent, когда у вас есть задача, которую вы часто повторяете, когда вам нужна роль с определёнными ограничениями инструментов или когда определённый системный промпт конфликтует с вашей основной конфигурацией.
Инженер нашего RAG-сервиса использует три пользовательских агента. prompt-auditor проверяет изменения промптов на соответствие правилам. eval-runner запускает тестовую среду и выдаёт структурированные результаты. retrieval-reviewer проверяет код реранжировщика с доменно-специфичными критериями.
Вот retrieval-reviewer.
Посмотрите на frontmatter. Строка tools — это узкий белый список, предоставляющий доступ на чтение и ограниченное выполнение bash. Строка model понижает агента до Sonnet. Основной цикл остаётся на дорогой модели для сложных рассуждений, в то время как subagent работает дёшево в фоне.
Слой 5: Skills
Skills упаковывают рабочий процесс, чтобы вы могли запускать его по имени.
Skill — это папка, содержащая markdown-файл с YAML frontmatter. Она может включать Python-скрипты, bash-команды и тестовые фикстуры.
Архитектура основана на прогрессивном раскрытии. Метаданные загружаются при запуске сессии. Фактические инструкции загружаются только при активации skill. Встроенные ресурсы загружаются только когда агент на них ссылается. Это позволяет поддерживать низкую стоимость токенов, даже если вы установите пятьдесят skills.
Мы создали skill под названием new-rag-eval. Он создаёт новый сценарий оценки из шаблона, подключает его к тестовой среде, запускает его против текущего пайплайна и записывает сводку результатов.
Разрешённые инструменты детерминированно ограничивают skill. Он может запускать скрипт оценки и добавлять файлы в staging. Он не может пушить в продакшен. Он направляет агента ко второму skill для процесса pull request.
Слой 6: Хуки и детерминизм
Хуки делают агента безопасным для запуска с меньшим количеством надзирателей. Они добавляют детерминированные ограждения в вероятностную систему.
Вы настраиваете хуки в файле настроек. События включают начало сессии, отправку пользовательского промпта и использование инструмента. Релиз апреля 2026 года добавил специальный хук для отклонений классификатора безопасности, чтобы вы могли аудитить запрещённые операции.
Самое важное дополнение — Deferred Permissions. Pre-tool хук теперь может возвращать решение defer, которое приостанавливает агента на середине выполнения в headless-режиме. Вы проверяете сессию и одобряете действие вне полосы. Агент возобновляет работу ровно с того места, где остановился. До отложенных разрешений ночной запуск, которому нужно было запушить в main, либо имел включённый --dangerously-skip-permissions, либо задание падало в 3 часа ночи.
Мы настраиваем два практических хука для RAG-сервиса. Post-tool хук запускает наш форматтер кода незаметно после каждой операции записи. Pre-tool хук откладывает любой git push, направленный в ветку main.
Вот сопутствующий shell-скрипт для шлюза.
Post-tool хук намеренно скучен. Однострочные хуки форматирования — это самая высокая окупаемость инвестиций, которую вы можете получить. Агент пишет грязный файл, а хук запускает линтер. Таким образом файл чист до следующего шага. Агент никогда не путается из-за собственных плохих отступов.
Слой 7: Стек серверов
Model Context Protocol подключает агента к внешним инструментам. Многие разработчики устанавливают пятнадцать серверов и удивляются, почему агент путается.
Каждый установленный сервер предоставляет схемы инструментов. Эти схемы потребляют токены контекста на каждом шаге. Документация Anthropic по Tool Search отмечает, что без ленивой загрузки 50 инструментов могут потреблять от 10 000 до 20 000 токенов за шаг. Ленивая загрузка Tool Search снижает это примерно на 85%, но меньшее количество серверов всё равно является лучшей стратегией.
Вам нужно ровно пять серверов для серьёзной инженерной настройки.
Вам нужен сервер графа кода с постоянной памятью сессии, сервер GitHub для управления ветками и коммитами, файловый сервер для доступа между директориями, сервер живого веб-поиска для актуальной документации и выделенный контекстный сервер для получения версионно-специфичных библиотек.
Если вы ИИ-инженер, напрямую запрашивающий продакшен-формы, вы можете добавить шестой сервер для вашей базы данных. Держите список маленьким. Один только сервер vexp обеспечивает сокращение токенов на 65–70% в долго работающих настройках агентов, согласно опубликованным бенчмаркам vexp.
Релиз апреля 2026 года также добавил тонкую серверную функцию, которую стоит искать в инструментах документации. Серверы теперь могут устанавливать аннотацию anthropic/maxResultSizeChars в поле _meta своего инструмента. Это позволяет держать большие выдержки из библиотечной документации встроенными, вместо того чтобы заставлять агента читать их с диска, полностью обходя старые обходные пути с записью файлов.
Слой 8: Параллельные worktree и headless-автоматизация
Worktree — это то, как вы перестаёте ждать, пока агент закончит печатать.
Вы выполняете одну команду, и инструмент создаёт ветку, worktree и изолированную сессию. Каждый worktree сохраняет собственное состояние редактора и запущенные процессы. Вы управляете ими в параллельных панелях.
Наш инженер распараллеливает задачу цитирования. Одна панель реализует основное изменение генерации. Вторая панель переписывает тестовую среду. Третья панель добавляет трассировку в новый путь поиска, а четвёртая панель составляет pull request. Каждая панель запускает свою собственную сессию со своим контекстом. Перекрывающиеся задачи приводят к перекрывающимся правкам, но если вы ограничиваете задачи разными доменами — например, оценки в одной панели, а основная логика в другой — на практике вы редко сталкиваетесь с конфликтами слияния.
Последняя часть — headless-режим. Вы запускаете агента неинтерактивно в вашем пайплайне непрерывной интеграции. Вы заносите в белый список конкретные инструменты и удаляете локальную конфигурацию для воспроизводимого поведения.
Вот ночное задание оценки, работающее в GitHub Actions.
Разрешённые инструменты взаимодействуют с хуками, которые мы создали ранее. Задание запускает оценку. Оно составляет исправление и пытается запушить в ветку main. Хук перехватывает push и откладывает разрешение. Пайплайн парсит JSON-лог, устанавливает выходную переменную и приостанавливается. Человек проверяет структурированный лог и одобряет его. Команда resume подхватывает точный ID сессии и завершает задание.
Повтор
У нас есть стек. Давайте посмотрим на девяностоминутную сдачу, используя реальные артефакты.
Сессия начинается. Инженер открывает проект и создаёт worktree для функции. Файл памяти и правила загружаются автоматически. Пять серверов подключаются.
Инженер входит в режим Deep Plan. Исследовательский subagent отображает текущие пути поиска, а планировщик выводит конкретный документ.
Инженер проверяет план и фиксирует его. Реализация выполняется в основном worktree. Когда агент заканчивает модификацию логики поиска, он вызывает subagent retrieval-reviewer. Subagent возвращает жёсткий блокиратор на основе правил, ограниченных путём.
Агент исправляет самодельный ID и отсутствующий декоратор. Post-tool хук поддерживает чистоту форматирования после каждой операции записи.
Начинается параллельная работа. Второй worktree использует skill new-rag-eval для перезаписи оценок. Headless-запуск выполняет финальную тестовую среду и генерирует diff.
Отложенное разрешение приостанавливает push. Инженер одобряет его. Pull request открывается через сервер GitHub с полным набором изменений и приложенным diff оценок.
Это предполагает, что задача хорошо ограничена, а стек уже построен. Первый раз, когда вы это настраиваете, это занимает вторую половину дня. Каждая последующая задача накапливается.
Нижняя и верхняя границы
Вы можете очень быстро испортить эту настройку. Не пишите большой файл памяти и не устанавливайте пятнадцать серверов. Схемы инструментов не бесплатны.
Не используйте основную сессию там, где нужен subagent. Исследование и проверка должны выполняться в изолированных контекстах.
Если вы не будете делать всё, вы должны хотя бы сделать минимум. Создайте короткий императивный файл памяти в корне проекта. Напишите два файла правил, ограниченных путём, для директорий, с которыми работаете чаще всего. Добавьте один хук форматирования. Установите три сервера для вашего репозитория, файловой системы и библиотечной документации. Заставьте себя использовать Plan Mode для любой задачи, где есть риск ошибиться.
Добавляйте subagent, когда задача повторяется. Добавляйте skills, когда рабочий процесс достаточно стабилен для упаковки. Добавляйте worktree, когда ловите себя на переключении веток чаще двух раз в час. Добавляйте headless-режим, когда хотите, чтобы агент сдавал код, пока вы спите.
Наш агент теперь может идеально навигировать по кодовой базе. Он всё ещё испытывает трудности с долго работающими задачами, где контекстное окно медленно заполняется устаревшими наблюдениями. В следующем посте мы рассмотрим продвинутый трек, изучая Context Rot, Compaction и Tool-Result Clearing, чтобы предотвратить утопление долго работающих агентов в собственной памяти.
Стек — это рабочий процесс. Рабочий процесс — это множитель. Промпт — это всего лишь последние пять процентов.