«Объясни как ребёнку», — пишем мы в чат ChatGPT, и через секунду получаем понятный ответ. Кажется, что внутри сидит маленький умник, который всё знает. На самом деле никакого «знающего» внутри нет. Есть только триллион чисел и математика. Сейчас расскажу, как это работает — без единой формулы.
НАЧНЁМ С САМОГО СЛОВА — «НЕЙРОСЕТЬ»
В 1940-х учёные посмотрели на человеческий мозг и удивились: 86 миллиардов клеток-нейронов, и каждая получает сигналы от тысяч соседей, обрабатывает их и передаёт дальше. Так мы думаем, помним, узнаём лица.
А что, если повторить эту схему в компьютере? Идея простая до наглости.
Программный «нейрон» — это крошечный кусочек кода, который получает несколько чисел на вход, умножает их на свои внутренние «коэффициенты», складывает, и если результат больше какого-то порога — отправляет сигнал дальше. Всё.
Один такой нейрон почти ничего не умеет. Но если собрать миллион... миллиард... 175 миллиардов (столько в GPT-3) — получится нечто, что пишет стихи, переводит языки и сдаёт экзамены.

ГЛАВНЫЙ ФОКУС — ОБУЧЕНИЕ!!!
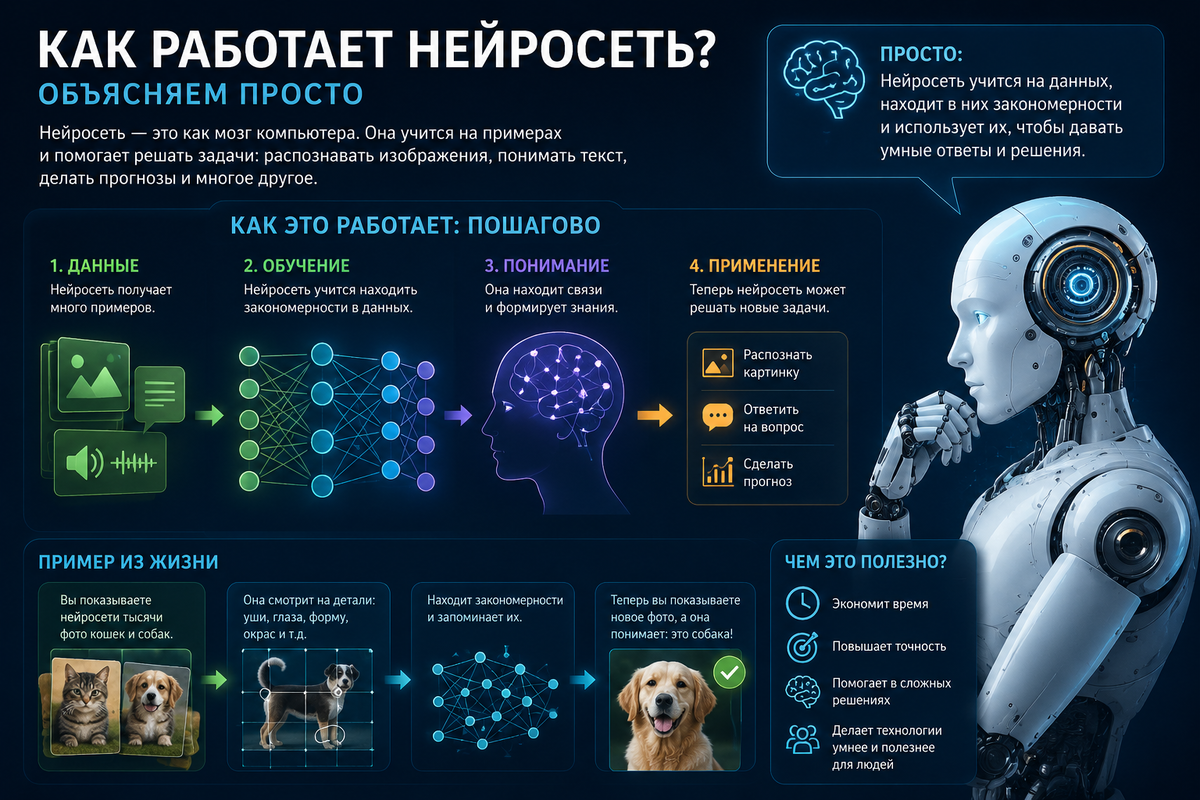
Представьте, что вы учите трёхлетнего ребёнка отличать кошку от собаки. Вы не объясняете ему: «у кошки уши треугольные, лапки мягкие, мяукает». Вы просто показываете картинки и говорите: «это кошка», «это собака», «это снова кошка».
После сотен примеров ребёнок начинает узнавать кошек на новых картинках, которые раньше не видел. Как? Никто толком не знает. Что-то щёлкает у него в голове, и связь устанавливается.
С нейросетью ровно так же. Только примеров не сотни, а миллионы. Возьмём упрощённую сеть для распознавания кошек. Подаём картинку — сеть выдаёт ответ: «кошка с вероятностью 30%, собака с вероятностью 70%». Сравниваем с правильным ответом («это была кошка»). Сеть ошиблась. Программа аккуратно подкручивает все внутренние коэффициенты, чтобы в следующий раз ответ был ближе к правильному. Повторяем — миллион раз, на миллионе картинок.
Постепенно коэффициенты приходят к таким значениям, что сеть начинает уверенно отличать кошек от собак. Никто эти коэффициенты не задавал — они «нашлись сами» в процессе обучения. Это и называется «обучением нейросети».
ПОЧЕМУ «ГЛУБОКАЯ» СЕТЬ
Один слой нейронов — слабак. Большая сила появляется, когда нейроны собирают в слои, и каждый слой передаёт сигнал следующему. Это как сборочный конвейер на заводе.
Первый слой смотрит на картинку и замечает простые штуки: вертикальная линия, пятно цвета, граница между светлым и тёмным. Второй слой собирает из этого фигуры посложнее: треугольник, круг, изгиб. Третий слой — части объектов: ухо, глаз, лапа. Последний слой выдаёт: «всё вместе это кошка».
Когда таких слоёв много — десять, сто, тысяча — сеть называют глубокой. Отсюда и «глубокое обучение» (deep learning), о котором все говорят с 2012 года.
А КАК ЖЕ ChatGPT?
С текстом всё устроено похоже, только сложнее. Языковая модель обучается на одной невыносимо простой задаче: дан кусок текста — угадай следующее слово. Вот и всё. Серьёзно.
«Москва — столица...» → «России» (правильно). «Я выпил чашку...» → «кофе» или «чая» (оба хороши). «Гарри Поттер учился в...» → «Хогвартсе» (потому что в обучающих данных это слово стояло после такого начала миллионы раз).
ChatGPT не «знает», что Москва — столица России. Он знает, что когда в тексте идёт «Москва — столица...», следующим словом чаще всего идёт «России». Это статистика, доведённая до сверхъестественного уровня.
Когда вы задаёте вопрос, модель просто угадывает слово за словом, постепенно складывая ответ. Каждое новое слово выбирается с учётом того, что было раньше — и в вашем вопросе, и в её собственном уже сгенерированном ответе.
ОТКУДА БЕРУТСЯ «ГАЛЛЮЦИНАЦИИ»
Раз нейросеть — это машина, которая угадывает следующее слово, а не «знает факты» — она будет иногда выдумывать. Особенно когда тема узкая или редкая.
Спросите её про вашего двоюродного дядю Петю — она с уверенностью расскажет его биографию. Полностью вымышленную. Потому что про дядю Петю в её обучающих данных ничего не было, но выдать связный текст она обязана. Так она устроена.
Это не злой умысел и не сбой. Это побочный эффект самой архитектуры: предсказание следующего слова не отличает «правда» от «правдоподобно». Запомните этот тезис — он объясняет 90% странностей в поведении нейросетей.
РАЗМЕР ИМЕЕТ ЗНАЧЕНИЕ
Главное открытие последних десяти лет — нейросети масштабируются. Чем больше нейронов, чем больше данных для обучения, чем мощнее железо — тем умнее результат. Цифры впечатляющие: GPT-2 (2019) — 1,5 миллиарда параметров; GPT-3 (2020) — 175 миллиардов; GPT-4 (2023) — оценочно 1,7 триллиона; Современные модели 2026 года — десятки триллионов.
Каждый «параметр» — это один из тех коэффициентов, что подкручиваются при обучении. Триллион коэффициентов — это число с двенадцатью нулями. Они хранят в себе всё, что модель «выучила» из интернета, книг и кода.
Чтобы обучить такую модель, нужны тысячи специальных чипов, работающих месяцами без остановки. Одно только обучение GPT-4 обошлось OpenAI, по разным оценкам, в более 100 миллионов долларов. И это только электричество и аренда оборудования.
МАЛЕНЬКИЙ СЛОВАРЬ, ЧТОБЫ НЕ ТЕРЯТЬСЯ В НОВОСТЯХ
Дообучение / файнтюнинг — когда готовую модель чуть-чуть подкручивают на специальных данных (например, медицинских или юридических).
Контекстное окно — сколько текста модель может «видеть» одновременно. У современных моделей — целая книга.
Температура — насколько разнообразно модель выбирает слова: низкая = предсказуемо, высокая = креативно (и больше «галлюцинаций»).
Промпт — ваш запрос к нейросети. Чем точнее промпт — тем лучше ответ.
Токен — кусок слова, на которые модель «нарезает» текст. Примерно 1 токен ≈ 0,75 слова на русском.
Теперь, когда вы понимаете, как работает «коробочка», в следующей статье возьмём микроскоп и посмотрим, чем именно отличаются ChatGPT, Claude, Gemini, GigaChat и YandexGPT. У каждой свой характер. Почему одна лучше пишет код, а другая — стихи.
Автор: ЧЕНГАЕВ Максим
Серия «Разбираемся в ИИ» • Статья 2 из 9