
Школьнику с интересом к молекулам и клеткам открыт прямой путь в IT: химия и биология здесь дополняют код, а не мешают ему. Любопытство легко превратить в востребованный навык, если сделать ставку на стык наук.
Индустрии нужны специалисты, которые применяют машинное обучение в протеомике, используют Data Science в клинических исследованиях и развивают вычислительную биологию, хемоинформатику и биоинформатику. Базой для этого становятся язык Python для биологов, анализ геномных данных (NGS pipelines) и язык R для анализа микробиомов.
Изученное быстро станет первой работой, если вовремя подключить практику и портфолио. В этой статье я разложу по полочкам, какие треки реально освоить школьнику или первокурснику. Вы узнаете, где брать задачи, на чём писать код и как превратить любовь к биологии в карьеру в ИТ без ловушек и обидных потерь времени.
Если вы пока сомневаетесь между чистой биологией и информационными технологиями, посмотрите материал Биотехнология: твой билет в профессию будущего — там есть отличный разбор пересечений.
Искусственный интеллект в биологии: AlphaFold, генеративные модели и большие языковые модели
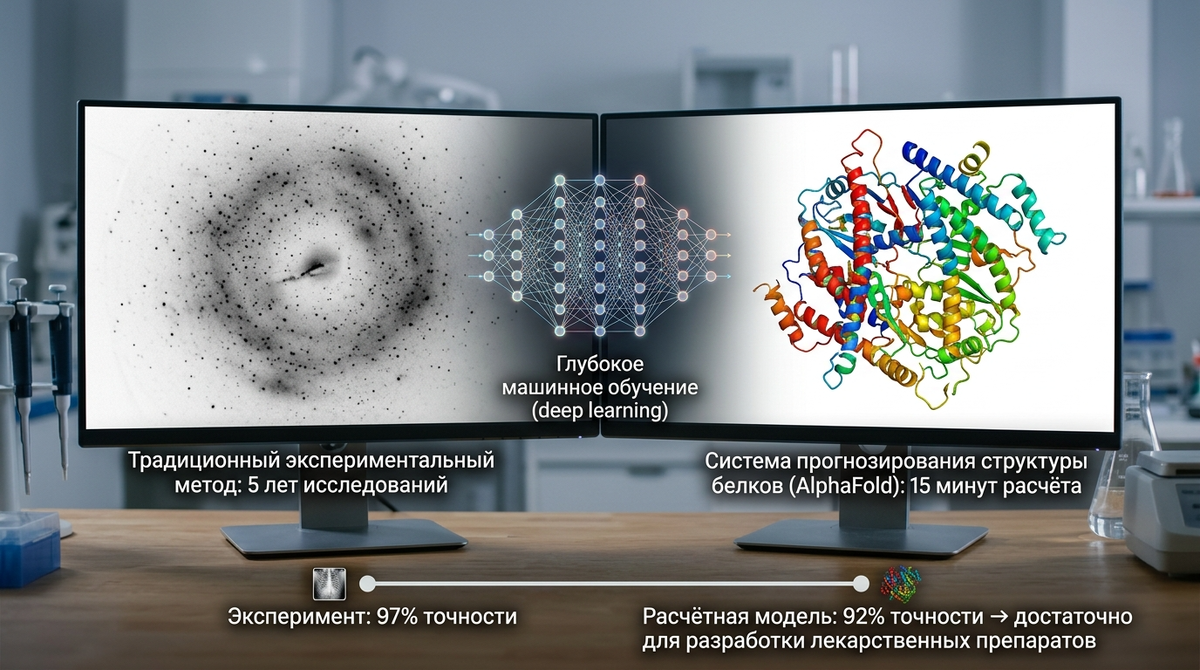
Искусственный интеллект перестал быть магией: он уже проектирует молекулы, читает статьи и предсказывает свёртку белка. Три опоры — система предсказания структуры белков / платформа молекулярного моделирования Розета (AlphaFold / Rosetta) и большие языковые модели для биологических текстов (LLM) — образуют практичную карту входа в тему. Если вы хотите соединить естествознание с промышленностью, вам также пригодится материал Промышленная экология на взлёте: кого ищут металлурги, химики и энергетики прямо сейчас.
Прорыв в предсказании структуры белков дал инструмент не только учёным в академии, но и студентам, которые хотят «пощупать» крупную науку на обычном ноутбуке. Пакет AlphaFold стал рабочей лошадкой: в паре с программой визуализации трёхмерных структур белков (PyMOL, Chimera) он превращает последовательность аминокислот в картинку, с которой можно работать дальше — от гипотез до учебных постеров.
Что такое анализ геномных данных (NGS pipelines)? Это последовательность вычислительных шагов, которые превращают сырые данные, полученные с секвенаторов нового поколения (Next Generation Sequencing, NGS), в интерпретируемые результаты — например, список мутаций или экспрессию генов. Такой конвейер включает выравнивание чтений на референсный геном, удаление дубликатов, перекалибровку качества и вариантное детектирование. Именно здесь и пригождаются системы Nextflow и Snakemake, о которых мы поговорим ниже.
Вторая опора — генеративный искусственный интеллект в поиске лекарств (generative AI в Drug Discovery). Это диффузионные подходы, которые обучаются на базах молекул и предлагают новые кандидаты с нужными свойствами. Чтобы такие молекулы не остались «красивыми картинками», рядом идут ИТ в токсикологии с моделями «структура-активность» (QSAR): они предсказывают токсичность и другие параметры. Здесь на первый план выходит хемоинформатика: работа с графовым представлением молекул и проверка по базам информации химических соединений (PubChem, ChEMBL).
Третья опора — большие языковые модели (LLM), обученные на корпусе медицинских публикаций PubMed, уже умеют извлекать связи «ген — болезнь — препарат» и помогать в разметке наборов показателей. Для школьника это шанс потренироваться на реальных текстах: взять пару сотен аннотаций, разметить сущности и научиться строить простой конвейер для извлечения фактов из статей.
Как нейросети предсказывают структуру белков
Сердце подхода — моделирование контактов между аминокислотами с учётом эволюционной истории и физики, после чего сеть сводит последовательность в устойчивую трёхмерную форму.
Если разобрать процесс без формул, логика такая. Модель «смотрит» на множественные выравнивания похожих белков, угадывает вероятности контактов между парами остатков и постепенно строит картину сворачивания. В версиях после AlphaFold 2 усилили модуль работы с комплексами и лигандами — обзор новой версии в журнале Nature описывает улучшения во взаимодействиях белка с ДНК и РНК [Nature, 2024].
В практической работе это дополняется платформой молекулярного моделирования Rosetta (Rosetta), которая даёт альтернативные варианты посадки молекул и локальные перестройки. После предсказания всегда полезно «пощупать» модель руками в программе визуализации трёхмерных структур белков (PyMOL, Chimera) и сравнить с аналогами в архиве RCSB PDB, где экспериментальных структур уже больше 210 тысяч.
Где здесь место начинающему:
- Возьмите интересный фермент, прогоните его через AlphaFold, сравните участки каталитического центра в PyMOL.
- Попробуйте накинуть идею молекулы-ингибитора с опорой на генеративный ИИ в поиске лекарств (generative AI в Drug Discovery).
- Добавьте проверку токсичности первичных кандидатов с опорой на ИТ в токсикологии.
Это не заявка на Нобелевскую премию, но честный проект для портфолио и тема для разговора на собеседовании. А если вас привлекает работа с водой и инфраструктурой, читайте наш материал Санкции, импортозамещение и канализация: как водный инженер оказался на пике востребованности?
Инженерия данных в биологии: BioOps
BioOps — это культура, где конвейер биологических воспроизводим, упакован в контейнер и считается на кластере без ручной магии. Три кита: системы управления био-вычислениями Nextflow и Snakemake (Nextflow / Snakemake), контейнеризация (Docker / Singularity) и высокопроизводительные вычисления (HPC).
Системы Nextflow и Snakemake превращают исследование геномов (NGS pipelines) в прозрачный сценарий: описали правила — и поток запускается хоть на ноутбуке, хоть на кластере. В Nextflow процессы связываются каналами; в Snakemake вы задаёте цели и правила, а движок сам отслеживает зависимости. Такой конвейер не ломается после обновления библиотек и не «теряет» параметры между запусками. Если вы собираете омные панели из секвенирования — это базовый инструмент. Куда поступить с ЕГЭ по биологии и химии? — этот материал поможет выбрать вуз с сильной подготовкой по биоинформатике.
Второй кит — контейнеризация (Docker / Singularity). Платформа Docker и платформа Singularity упаковывают исполняемую среду со всеми зависимостями. В биомедицине часто нельзя обновить системы на кластере без согласования, а проекты живут годами — контейнеры решают обе задачи. Для воспроизводимости в публикациях это уже стандарт.
Docker широко используется в облачных вычислениях и микросервисной архитектуре. Singularity разработан специально для научных и высокопроизводительных вычислительных сред (HPC), где требуются строгие разрешения безопасности и воспроизводимость. Важно отметить, что Singularity может запускать образы Docker, что делает его гибким инструментом для научных исследований.
Третий кит — высокопроизводительные вычисления. Очереди задач на кластере, распределение по узлам, учёт ресурсов — без этой рутины большие наборы OMICS-данных (геномика, протеомика, метаболомика) попросту не успевают обрабатываться. Кластер из нескольких десятков узлов способен «переварить» десятки терабайт за ночь, если у вас конвейер на Nextflow или Snakemake, контейнеризация и грамотные профили. Это та инженерия, которую ценят работодатели сильнее, чем «красивые» ноутбуки с разрозненными скриптами.
Мини-гайд по первому конвейеру:
- Возьмите публичные сырые чтения из архива (Sequence Read Archive), опишите шаги качества и сборки в Snakemake.
- Заверните всё в контейнер Singularity, запустите локально, затем перенесите на кластер с очередью Slurm.
- Добавьте отчётность: одну информационную панель и журнал версий.
Совет: храните версии конвейера в публичном репозитории — это усилит ваш профиль и покажет, что вы мыслите как инженер. И не забывайте про облачные платформы для биотехнологии: иногда выгоднее прогнать тяжёлую часть в облаке.
Цифровое здоровье: цифровые двойники пациента и OMICS-материалы
Цифровое здоровье (HealthTech) связало генетику, клинические записи и моделирование: цифровые двойники пациента / клетки (Digital Twins) питаются OMICS-данными и живут по правилам приватности и регуляций. Биотехнология: твой билет в профессию будущего — ещё один материал, который поможет понять, как естествознание встречается с технологиями.
Смысл цифровой модели пациента или клетки — быстро проверять гипотезы без риска для человека. Такой двойник собирает в себе генотип, исследования, изображения, иногда — носимые датчики. На этом фоне растут проекты, где кластеры и облачные платформы для биотехнологии обрабатывают потоки, а врачи получают подсказки по терапии. Журнал npj Digital Medicine подчёркивает, что цифровые двойники пациента / клетки (Digital Twins) уже применяют для планирования операций на сердце и персонализации дозировки лекарств [npj Digital Medicine, 2024].
Сырая энергия здесь — OMICS-данные (геномика, протеомика, метаболомика). Они наполняют двойники фактами: мутации, уровни белков, метаболиты. В ход идёт язык R для изучения микробиомов, когда мы отслеживаем состав микробных сообществ и видим сдвиги на фоне лечения. Для массовых панелей полезно машинное обучение в протеомике — оно помогает распознавать и количественно оценивать сигналы белков. А если строите модель метаболизма для цифрового органоида — пригодится разработка симуляторов метаболических путей: уравнения, константы, сценарии «что, если».
Что такое протеомика? Это крупномасштабное изучение белков, их структур и функций. Машинное обучение в протеомике помогает исследовать материалы масс-спектрометрии, предсказывать посттрансляционные модификации и идентифицировать биомаркеры заболеваний. А метаболомика — это изучение малых молекул (метаболитов) в биообразцах. Её показатели помогают понять, как организм реагирует на лекарства или изменения в питании, и тесно связаны с персонализированной медициной.
Правила игры, о которых нельзя забывать:
- Кибербезопасность медицинской информации (GDPR/HIPAA в контексте био-данных) требует маскировки и ограничений доступа. В Европе действует Общий регламент по защите (GDPR), в США — закон HIPAA.
- Цифровые двойники пациента / клетки (Digital Twins) работают только если у вас плотная валидация. Сначала ретроспектива на старых материалах, затем — проспективные испытания.
- Высокопроизводительные вычисления (HPC) и облачные платформы для биотехнологии перегоняют терабайты, а Nextflow и Snakemake держат конвейеры в узде.
Даже самый точный алгоритм ошибётся без чистых метаданных. На этом месте в проект заходит менеджер клинических материалах (clinical data manager) — человек, который организует протоколы ввода, контроль качества, доступы и сроки. И именно здесь пригодятся большие языковые модели (LLM): модель ускоряет извлечение показателей из сканов и помогает формировать словари.
Роли в информационных технологиях для биолога: химик-вычислитель, менеджер клинических данных, разработчик лабораторных информационных систем
Входных ролей много: от моделирования молекул до инженерии клинических баз и лабораторных систем. Выбирайте, исходя из того, что вас «зажигает» — молекулы, код или процессы. Почему за чиновниками от природы охотятся корпорации — эта статья показывает, как биология и экология встречаются с управлением, а навыки, описанные ниже, также востребованы в регуляторной сфере.
Роль 1 — химик-вычислитель (computational chemist). Вы работаете на стыке хемоинформатики и генеративного искусственного интеллекта в поиске лекарств (generative AI в Drug Discovery) : оценка сродства молекулы к белку, подбор химического ядра, фильтры Липинского, QSAR и докинг. Источники — базы химических соединений (PubChem, ChEMBL). Вы используете визуализацию трёхмерных структур белков (PyMOL, Chimera), чтобы разбирать активные центры, и пакеты наподобие Rosetta для улучшения посадок. Такая позиция любит разработку симуляторов метаболических путей, когда команда проверяет, как молекула «встроится» в клеточную химию, и информационные технологии в токсикологии для раннего отсечения плохих кандидатов.
Роль 2 — менеджер клинических показателей (clinical data manager). Это человек процесса. Он выстраивает ввод информации, проверки, права, готовит выгрузки для регуляторов и исследователей. Тут рулят наука о данных в клинических исследованиях (data science), умение читать протокол и держать в голове ограничения кибербезопасности (GDPR/HIPAA в контексте био-данных). Часто требуется знание языка программирования R для изучения микробиомов и отчётности, владение анализом геномных материалах (NGS pipelines) как потребителя, а ещё — установка и поддержка информационных панелей для врачей. Высокопроизводительные вычисления (HPC) для роли не обязательны, но понимание того, что «за кулисами» у биоинформатика, помогает принимать верные решения по срокам.
Роль 3 — разработчик лабораторных информационных систем (developer of LIMS). Лабораторные процессы сложны: логистика образцов, штрих-коды, очереди приборов, права доступа. Разработчик лабораторной информационной системы поднимает платформу, шлифует формы, вяжет её с аналитическими модулями и обвязкой — от Nextflow и Snakemake до модулей, где работает визуализация трёхмерных структур белков (PyMOL, Chimera) для научных отчётов. Контейнеризация (Docker / Singularity) — рутина роли; она ускоряет развёртывание и ставит конфигурации на рельсы.
Минимальный набор навыков для старта:
- язык Python для биологов (базовый синтаксис, библиотеки Pandas, построение графиков)
- знание языка структурированных запросов SQL (SELECT, JOIN, GROUP BY)
- основы операционной системы Linux (командная строка, управление файлами, права доступа)
- опыт с облачными платформами для биотехнологии (хотя бы на уровне бесплатного аккаунта AWS, Google Cloud или Yandex Cloud)
По сведениям открытых вакансий на сайте hh.ru в 2026 году, младший специалист по биоинформатике (junior-биоинформатик) в крупных городах видит вилки 90–150 тысяч рублей в месяц, химик-вычислитель (computational chemist) — 150–250 тысяч, менеджер клинических исследований (clinical data manager) — 110–190 тысяч, разработчик лабораторных информационных систем (developer of LIMS) — 140–230 тысяч [материалы сайта hh.ru, 2026]. Контраст «академия против индустрии»: в лаборатории ставка на публикации и долгие проекты; в компании — на сроки, воспроизводимость и промышленную эксплуатацию решений.
Независимо от роли, ценится предметная экспертиза (domain expertise): вы различаете загрязнение образца, понимаете, что такое контроль качества масс-спектра и почему клиника не может «подкрутить» сбор персональной информации. Это и есть domain expertise (предметная экспертиза как преимущество перед чистыми программистами) — она отличает сильного новичка от человека, который только учил синтаксис.
Где учиться на стыке биологии и информационных технологий: обзор университетов
В российских вузах есть гибкие связки дисциплин, где будущие биологи получают инженерные навыки и реальные кейсы. Работают разные модели: от дополнительных специализаций до модульных треков и совместных программ с ИТ-кафедрами. Ниже представлен подробный обзор конкретных университетов.
Что такое биоинформатика? Это наука, которая использует компьютерные технологии для сбора, хранения, изучения и распространения информации. Биоинформатики разрабатывают программное обеспечение и вычислительные методы для понимания процессов, исследования геномов и предсказания структуры белков. Именно этот навык — ключевой для входа в ИТ.
Где искать подобные треки (бакалавриат и магистратура, очная форма, ориентировочная стоимость на 2025–2026 учебный год):
- Московский государственный университет им. М. В. Ломоносова (МГУ) — факультет биоинженерии и биоинформатики, сильнейшая фундаментальная база по молекулярной биологии и математике. Студенты с первого курса погружаются в программирование и геномику. Стоимость: от 512 000 до 547 000 рублей в год. Официальный сайт: msu.ru.
- Московский физико-технический институт (МФТИ) — модули по вычислительной биологии, проекты с реальными промышленными партнёрами (BIOCAD, Генериум). Сильная школа по машинному обучению и изучению информации. Стоимость: от 1 014 000 рублей в год. Официальный сайт: mipt.ru.
- Университет ИТМО — сильная школа по анализу информации в биомедицине, лаборатории биосенсоров и оптохимии. Здесь активно развиваются направления по вычислительной биологии и биоинформатике. Стоимость: от от 680 000 рублей в год. Официальный сайт: itmo.ru.
- Национальный исследовательский университет «Высшая школа экономики» (НИУ ВШЭ) — совместные курсы по биостатистике и изучению данных. Факультет компьютерных наук предлагает специализации по проверке медицинских сведений. Стоимость: около 400 000 - 470 000 рублей в год. Официальный сайт: hse.ru.
- Санкт-Петербургский государственный университет (СПбГУ) — магистратуры по биоинформатике, сильная подготовка по генетике и молекулярной биологии. Стоимость около 338 900 — 359 200 рублей в год (в зависимости от конкретной образовательной программы). Для иностранных граждан цены могут составлять от 385 000 до 410 000+ рублей. Официальный сайт: spbu.ru.
- Новосибирский государственный университет (НГУ) — сильная школа по геномике, уникальная близость к институтам Сибирского отделения Российской академии наук (Институт цитологии и генетики). Стоимость: около 250 000 рублей в год. Официальный сайт: nsu.ru.
- Сколковский институт науки и технологий (Сколтех) — проектные магистратуры по биоинженерии и искусственному интеллекту в биомедицине. Ориентация на прикладные исследования и стартапы. Стоимость уточняйте на официальном сайте: skoltech.ru.
- Первый Московский государственный медицинский университет им. И. М. Сеченова — интеграция с клиниками, работа с реальными медицинскими данными, программы по медицинской биоинформатике. Стоимость: от 300 000 рублей в год. Официальный сайт: sechenov.ru.
- Университет «Синергия» — программы на стыке биотехнологии и информационной безопасности. Ориентир на гибкость и переходный трейнинг «bio → ML», который позволяет студентам освоить языки программирования, машинное обучение в протеомике и работу с конвейерами анализа геномов (NGS pipelines). Стоимость: 180 000 - 300 000+ рублей в год. Официальный сайт: synergy.ru.
Важно: указанные суммы носят ознакомительный характер. Точные названия программ и стоимость обучения ежегодно уточняются приёмными комиссиями вузов. Актуальные данные рекомендуется проверять на официальных сайтах перед подачей документов. Бакалавриат длится 4 года, магистратура — 2 года. Бюджетные места распределяются по результатам единого государственного экзамена и дополнительных вступительных испытаний (например, профильное собеседование или внутреннее вступительное испытание).
Открытый код и Kaggle: как собрать портфолио
Сильное портфолио строится из открытых репозиториев и соревнований: открытый код в науке (open source в науке) и соревнования (Kaggle-соревнования по био-тематике) дают задачи, данные и обратную связь. Это особенно важно, если у вас пока нет коммерческого опыта работы.
Почему это работает. Открытый код в науке (open source в науке) — не про «бесплатность», а про проверяемость и прозрачность. Вы делитесь кодом конвейера, контейнером, описанием эксперимента — и получаете шанс на коллаборацию с исследователями из других городов и стран. Крупные проекты вроде ELIXIR (европейская инфраструктура биологических данных) учат той же культуре: стандарты метаданных, воспроизводимость и долгосрочная поддержка. Соревнования по био-тематике (Kaggle-соревнования) помогают «потрогать» чистые метрики: ваш код получает численный результат (score) — и никаких разговоров на уровне «кажется, это работает».
Идеи простых проектов для портфолио (выберите одну или две):
- Геномный проект: конвейер исследования геномных данных (NGS pipelines) на Nextflow или Snakemake для публичного набора из архива (Sequence Read Archive). Добавьте отчёт о качестве чтений и список выявленных вариантов.
- Белковый проект: набор примеров по визуализации трёхмерных структур белков (PyMOL, Chimera) с аннотацией активных центров и мутаций. Сравните дикую и мутантную формы.
- Микробиомный проект: набор тетрадей на языке программирования R для анализа 16S рибосомной рибонуклеиновой кислоты (рРНК) с ясными визуализациями (альфа- и бета-разнообразие, тепловые карты).
- Химический проект: набор вычислительных блокнотов (Jupyter Notebook) по информационным технологиям в токсикологии с построением модели QSAR (количественная связь «структура-активность») и проверкой качества на кросс-валидации.
- Клинический проект: шаблоны в помощь менеджеру клинических данных (clinical data manager) — валидация форм на языке Python, автоматические отчёты о пропущенных показателях, скрипты для анонимизации персональной информации.
План из пяти шагов для старта работы над портфолио:
- Выберите тему ближе к вам: белки, геномы, микробиомы или молекулы. Не пытайтесь объять всё сразу.
- Соберите открытый базу (например, из Kaggle, архива SRA, PDB). Убедитесь, что есть лицензия на использование.
- Опишите конвейер: Nextflow или Snakemake + контейнеризация (Docker / Singularity). Добавьте понятную инструкцию по запуску (README-файл).
- Сделайте короткую статью в репозитории: постановка задачи, использованные методы, полученные результаты и их ограничения. Это показывает ваше умение объяснять сложные вещи.
- Проверьте идею на соревнованиях (Kaggle-соревнования по био-тематике) — возьмите похожую задачу и сравните свои метрики с лидерами. Даже если не выиграете, вы получите ценный опыт.
Совет: чаще проговаривайте в описании проекта, где именно сработала ваша предметная экспертиза (domain expertise). Например: «я заметил, что часть данных выглядит как загрязнение образца (контаминация) на основе биологических критериев, отфильтровал их и сэкономил недели вычислений на ложных сигналах». Это важнейший маркер для работодателя и для академического наставника — он показывает, что вы не просто кодер, а специалист, который понимает смысл.
Стартовать с биологии — и выиграть гонку в ИТ
Это понятная и реальная стратегия: вы совмещаете предметную базу и инженерные практики. Дальше — проекты, конвейеры, участие в открытых инициативах и аккуратная сборка портфолио.
Куда делать первый шаг (конкретные действия):
- Берите язык программирования Python и язык R для исследования микробиомов. Пройдите бесплатные курсы на Stepik или Coursera.
- Осваивайте анализ геномов (NGS pipelines) на учебных примерах — например, на SARS-CoV-2 из открытых архивов.
- Попробуйте машинное обучение в протеомике на реальном наборе масс-спектров (есть открытые датасеты в Pride Archive).
Чем выделиться среди других кандидатов (даже младших специалистов):
- Покажите, что знаете облачные платформы для биотехнологии (хотя бы на уровне ученического проекта в Google Colab или бесплатном аккаунте AWS).
- Уверенно работаете с системами Nextflow или Snakemake. Это покажет, что вы понимаете принципы воспроизводимой науки.
- Умеете делать контейнеризацию (Docker / Singularity). Добавьте Dockerfile в свой проект на GitHub.
- Представляете, где нужны высокопроизводительные вычисления (HPC) и как писать скрипты для очереди задач (хотя бы на уровне Slurm).
О чём нельзя забывать: кибербезопасность медицинских показателей (GDPR/HIPAA в контексте био-данных) — не формальность, а требование законов Европы и США. Даже в учебном проекте используйте обезличенную информацию. Запишите понимание этих регуляций в резюме как отдельную строку навыков — это покажет вашу зрелость.
Зачем всё это: чтобы собрать карьеру на стыке. Химик-вычислитель (computational chemist), менеджер клинических сведений (clinical data manager) или разработчик лабораторных информационных систем (developer of LIMS) — все три дороги открыты тем, кто ценит предметную экспертизу (domain expertise как преимущество перед чистыми программистами) и держит фокус на реальной пользе, а не на абстрактных алгоритмах.
Где взять мотивацию: цифровые двойники пациента / клетки (Digital Twins), большие языковые модели (LLM) и генеративный искусственный интеллект в поиске лекарств — это уже происходит прямо сейчас, а не в отдалённом будущем. Ваша задача — оказаться внутри этого процесса, пока он только набирает обороты.
Контраст, который стоит запомнить: чисто «чистый» программист напишет код быстро, но может не заметить бессмысленный результат (например, ген, который «экспрессируется» там, где его быть не может). А вы, с вашей базой, заметите ошибку на этапе проверки показателей и спасёте проект от публикации ложных выводов. Это и есть ваше конкурентное преимущество.
Начните прямо сейчас: один небольшой конвейер, один репозиторий открытого кода в науке (open source в науке) и одно участие в соревнованиях Kaggle по био-тематике (Kaggle-соревнования по био-тематике) — этого достаточно, чтобы разговор о стажировке или первой работе шёл в конструктивном ключе. Переходный трейнинг «bio → ML» — это не «быстрый чит-код» и не волшебная таблетка, а грамотная, продуманная лестница. Поднимайтесь по ней спокойно, шаг за шагом, и вы обязательно добьётесь успеха.
Если вы ещё не определились с вузом, посмотрите наш материал о 10 профессий будущего для тех, кто сдаёт химию и биологию — он поможет понять, какие направления вообще существуют на стыке наук.