проблема контаминации данных встает все острее в наше время (не просто так мы с коллегами предложили бенчмарки DRAGOn и SWE-MERA соответственно)
независимая группа исследователей предложила остроумный экcперимент - они взяли англоязычные тексты до 1931 года (на сегодняшний день - это отсечка текстов, не охраняющихся авторским правом в США), пример текстов на первой картинке, и обучили на них языковые модели
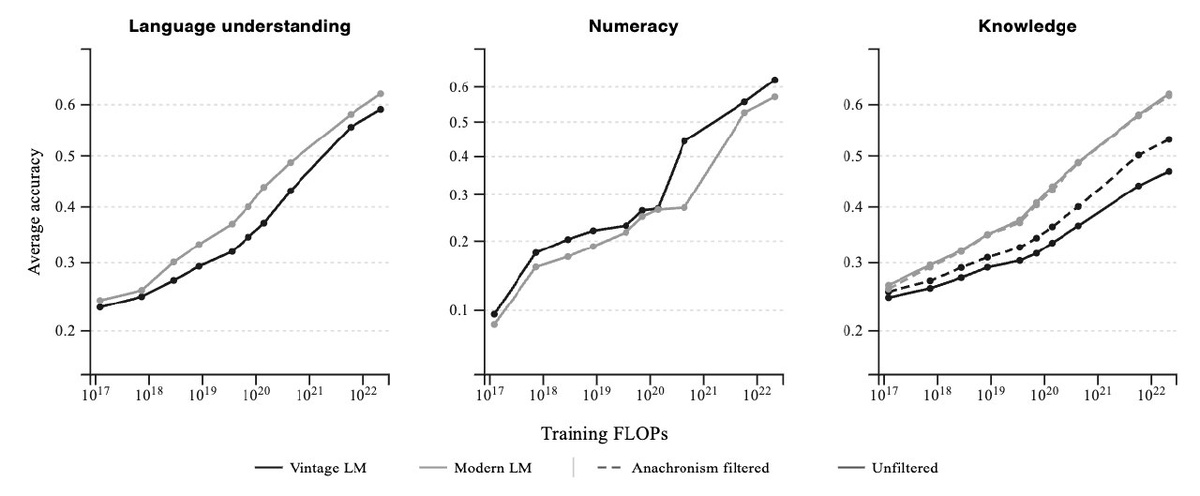
также они обучили аналогичные модели на FineWeb, и сравнились с ними; на 2 картинке видно, что по работе с языком модели почти не отличаются, по знаниям современные модели очевидно лучше; а вот по теме numeracy - чуть-чуть лучше получаются винтажные модели; что такое numeracy авторы не поясняют, я так понял это задания про работу с числами
второй интересный результат (3 картинка) - это то, что винтажные модели сильно хуже, но все-таки могут справиться с кое-чем на python (если им дать пример в контексте)