«Какой AI-инструмент выбрать для 1С-разработки» — вопрос, который задают чаще всего. Мы у себя в B2C используем оба: Claude Code от Anthropic и Codex от OpenAI. И не как конкурентов, а как разные роли в одной команде. В этой статье — живой кейс на нашей демо-конфигурации VibeCRM: Claude изучает проект и пишет техническое задание, Codex реализует и запускает тесты. Два часа работы, 35 изменённых файлов, 11 пройденных тестов — всё на скриншотах ниже.
Зачем сравнивать и почему мы используем оба
Когда говорят «AI для разработки», часто имеют в виду один конкретный инструмент. На практике это рынок с несколькими сильными игроками, и для 1С-разработки релевантны два:
- Claude Code от Anthropic — на моделях Claude Sonnet и Opus серии 4.6–4.7. Контекстное окно до 1 миллиона токенов. Подход «диалоговый»: показывает план перед действием, спрашивает подтверждение на критичные операции.
- Codex от OpenAI — на моделях GPT-5 и GPT-5-Codex. Контекстное окно до 400 тысяч токенов. Подход «автономный»: берёт задачу и идёт делать длинными шагами, реже останавливается на подтверждения.
Оба работают через стандартный протокол MCP (Model Context Protocol), оба видят одинаковые серверы метаданных 1С, документации EDT и нашу библиотеку из более 300 готовых обработок. Если вы ещё не работали с CLI/desktop-агентами — начните с «Что такое AI-разработка 1С простыми словами».
В статье ниже мы покажем кейс: Claude — в роли архитектора и аналитика, Codex — в роли исполнителя и тестировщика. Дальше — сравнительная таблица, цена, выводы.
Кейс: VibeCRM — конфигурация, написанная с нуля ИИ
Объект: внутренняя демо-конфигурация на свежей платформе 1С:Предприятие. Подсистема — VibeCRM (учёт заявок клиентов с интеграциями), полностью сгенерирована AI с нуля. Структура: 9 модулей BSL, ~3500 строк кода, 4 справочника, документ «ЗаявкаКлиента», 3 регистра, 2 отчёта, 1 обработка с большим объёмом UI-логики.
Задача: показать, что AI способен не только писать код, но и улучшать собственный код по стандартам 1С. Использовать сильные стороны обоих инструментов:
- Claude — для глубокого анализа и постановки задач
- Codex — для длинной автономной реализации с тестами
Время: четыре часа на всё. Скрины ниже — реальные, без редактуры.
Шаг 1. Claude Code изучает проект
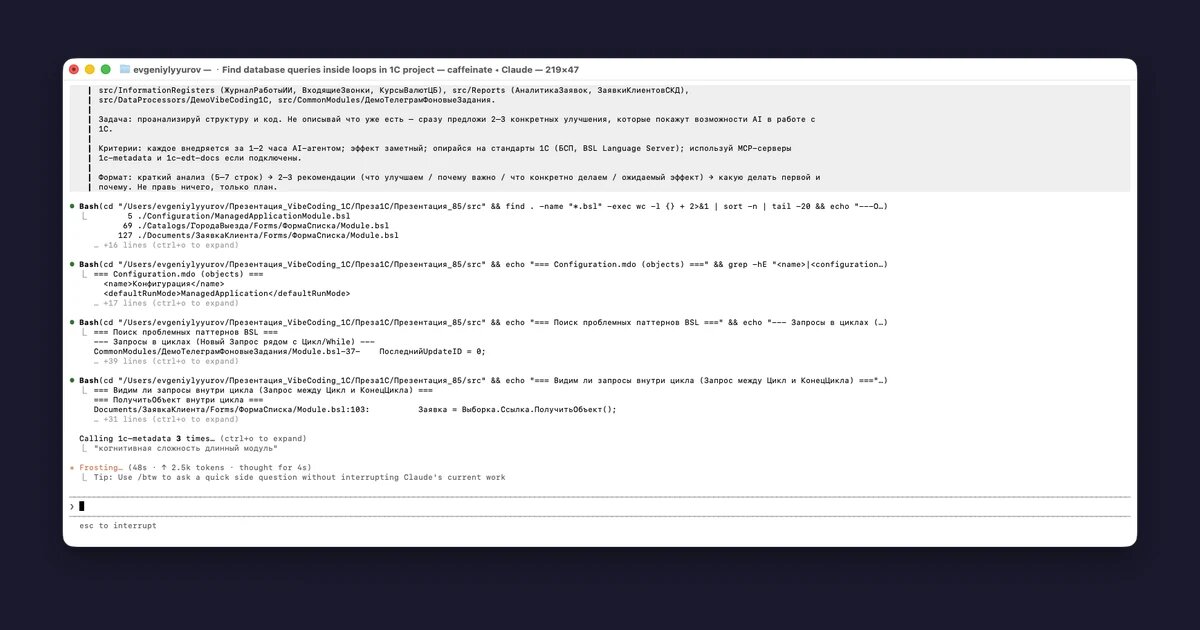
Запускаем Claude Code в папке конфигурации, даём один промпт: «проанализируй структуру и код, предложи 2–3 улучшения, которые покажут возможности AI; используй MCP-серверы 1c-metadata и 1c-edt-docs». Без описания проекта — Claude сам разберётся через файловую систему и MCP.
За пару минут Claude:
- Запустил серию Bash-команд — посчитал строки в каждом модуле, прочитал Configuration.mdo, нашёл проблемные паттерны через grep
- Дёрнул MCP-сервер 1c-metadata три раза — проверил конкретные диагностики BSL Language Server
- Выдал структурированный анализ с цифрами и список из трёх рекомендаций с обоснованиями и оценкой времени
Развернуть полный анализ Claude (без редактуры)
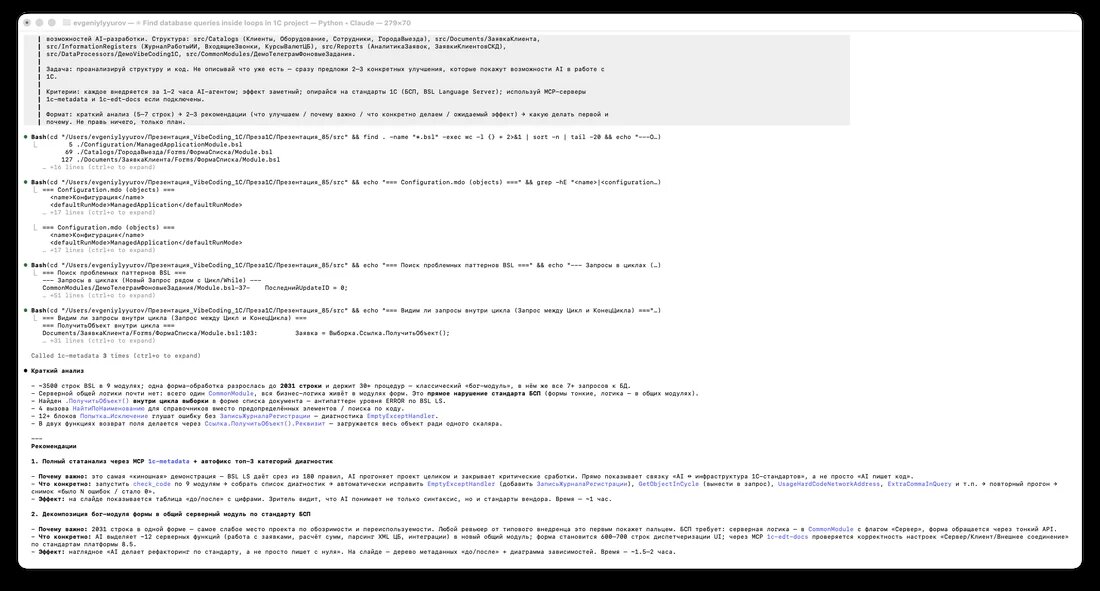
> Контекст: эта конфигурация 1С написана с нуля искусственным интеллектом. Подсистема — VibeCRM. Структура: src/Catalogs (Клиенты, Оборудование, Сотрудники, ГородаВыезда), src/Documents/ЗаявкаКлиента, src/InformationRegisters (ЖурналРаботыИИ, ВходящиеЗвонки, КурсыВалютЦБ), src/Reports (АналитикаЗаявок, ЗаявкиКлиентовСКД), src/DataProcessors/ДемоVibeCoding1C, src/CommonModules/ДемоТелеграмФоновыеЗадания. > Задача: проанализируй структуру и код. Предложи 2–3 конкретных улучшения. Критерии: каждое внедряется за 1–2 часа AI-агентом; эффект заметный; опирайся на стандарты 1С; используй MCP-серверы 1c-metadata и 1c-edt-docs. Не правь ничего, только план. Bash: find / wc-l / grep по проблемным паттернам · Called 1c-metadata 3 times
Краткий анализ
- ~3500 строк BSL в 9 модулях; одна форма-обработка разрослась до 2031 строки и держит 30+ процедур — классический «бог-модуль», в нём же все 7+ запросов к БД.
- Серверной общей логики почти нет: всего один CommonModule, вся бизнес-логика живёт в модулях форм. Это прямое нарушение стандарта БСП.
- Найден .ПолучитьОбъект() внутри цикла выборки в форме списка документа — антипаттерн уровня ERROR по BSL LS.
- 4 вызова НайтиПоНаименованию для справочников вместо предопределённых элементов / поиска по коду.
- 12+ блоков Попытка-Исключение глушат ошибку без ЗаписьЖурналаРегистрации — диагностика EmptyExceptHandler.
- В двух функциях возврат поля делается через Ссылка.ПолучитьОбъект().Реквизит — загружается весь объект ради одного скаляра.
Рекомендация №1 — статанализ через MCP + автофикс топ-3 категорий
Почему важно: BSL LS даёт срез из 180 правил, AI прогоняет проект целиком и закрывает критические сработки. Прямо показывает связку «AI ↔ инфраструктура 1С-стандартов».
Что конкретно: запустить check_code по 9 модулям → собрать список диагностик → автоматически исправить EmptyExceptHandler, GetObjectInCycle, UsageHardCodeNetworkAddress, ExtraCommaInQuery → повторный прогон → снимок «было N ошибок / стало 0».
Время: ~1 час.
Рекомендация №2 — декомпозиция бог-модуля по стандарту БСП
Почему важно: 2031 строка в одной форме — самое слабое место проекта. БСП требует: серверная логика — в CommonModule с флагом «Сервер», форма обращается через тонкий API.
Что конкретно: AI выделяет ~12 серверных функций (работа с заявками, расчёт сумм, парсинг XML ЦБ, интеграции) в новый общий модуль; форма становится 600–700 строк диспетчеризации UI.
Время: ~1.5–2 часа.
Рекомендация №3 — покрытие YAxUnit-тестами 5–7 ключевых функций
Почему важно: закрывает аргумент скептиков «AI пишет код, но не отвечает за качество». Тесты, написанные AI к коду, который он же сгенерировал.
Что конкретно: AI находит подходящие рецепты YAxUnit → пишет тесты на: создание заявки клиента, расчёт суммы документа, парсинг курса ЦБ, поиск города. Прогон → JUnit-отчёт.
Время: ~1.5 часа.
Что делать первым
Рекомендация №1 (статанализ + автофикс). Три причины: максимальный визуальный эффект за минимум времени; прямая демонстрация инфраструктуры с MCP; подготовка почвы для №2 и №3 (после автофиксов код станет чище, рефакторинг будет проще).
Шаг 2. Claude Code разворачивает рекомендации в техническое задание
На этом многие останавливаются: «AI дал план — дальше человек делает». Мы пошли дальше: попросили Claude развернуть план в полноценное промышленное ТЗ. С разделами, требованиями, критериями приёмки, оценкой трудоёмкости. Чтобы потом передать его другому AI-агенту как ТЗ от заказчика к подрядчику.
Промпт был один: «напиши техническое задание по задачам». Через минуту получили документ из трёх задач, общим объёмом ~250 строк, в формате привычного ТЗ:
Что в этом ТЗ — структура (полный текст в репозитории проекта)
Объект работ: конфигурация-расширение на платформе 1С:Предприятие, ~3500 строк BSL, 9 модулей.
Исполнитель: AI-агент с доступом к MCP-серверам 1c-metadata, 1c-edt-docs, 1c-testing.
Срок: до 5 часов суммарно по трём задачам.
Задача 1. Полный статанализ и автоисправление критических диагностик BSL LS (1 час)
- Прогнать через MCP check_code все 9 модулей
- Сохранить «снимок ДО» в reports/diagnostics_before.json
- Исправить автоматически: CreateQueryInCycle, GetObjectInCycle, EmptyExceptHandler, UsingObjectNotDeclaredModule, MagicNumber, MissingTemporaryFileDeletion
- Повторный прогон → «снимок ПОСЛЕ» → сводка Markdown с таблицей «было / стало»
- Критерий приёмки: 0 диагностик уровня CRITICAL и MAJOR
- Запрещено отключать диагностики через комментарии-подавители — только реальные исправления
Задача 2. Декомпозиция бог-модуля формы по БСП (1.5–2 часа)
- Создать три новых общих модуля: VibeCRMСервер, VibeCRMКлиент, VibeCRMПовтИсп с корректными флагами компиляции
- Вынести из формы все процедуры с &НаСервере, не использующие реквизиты формы
- В клиентских модулях запрещены обращения Справочники.X, Документы.X, Запрос
- Критерий приёмки: модуль формы ≤ 700 строк, все 8 команд формы работают идентично
Задача 3. Покрытие YAxUnit-тестами 7 кейсов (1.5 часа)
- Создать общий модуль VibeCRMТесты с подтипом «Тестовый»
- Реализовать 7 тестов: создание заявки, расчёт суммы, парсинг курса ЦБ, поиск города, запись в журнал ИИ, проведение/отмена документа
- Каждый тест независим (setUp/tearDown), тестовые данные с префиксом [TEST]
- Критерий приёмки: все 7 тестов в статусе passed в JUnit-отчёте, общее время ≤ 60 секунд
Что считается провалом: подавление диагностик через комментарии-отключатели; &НаСервереБезКонтекста в клиентском модуле; тесты с пустыми Утверждения.ЭтоИстина(Истина); изменение интерфейса форм без согласования.
Это уже совсем другой уровень — Claude сам поставил себе задачу как заказчик и сам себя проверил критериями приёмки. Готовый документ, который можно отдать в исполнение.
Шаг 3. Codex принимает ТЗ и идёт реализовывать
Передаём готовое ТЗ в Codex (десктоп-приложение OpenAI) с одной фразой: «нужно реализовать это, это ТЗ тебе». Codex отвечает в своём стиле — берёт задачу и идёт делать.
Что видно по интерфейсу Codex и почему это важно:
- Прогресс-чеклист справа — Codex сам бьёт ТЗ на чекпоинты и закрывает их по мере выполнения. Не нужно сидеть и постоянно спрашивать «как там»
- Артефакты — Codex по ходу работы создаёт отчёты (diagnostics_summary.md, refactor_metrics.md, test_summary.md), они сразу доступны в боковой панели
- Подключённые MCP-серверы — те же что у Claude: 1c-metadata, 1c-testing, 1c-edt-docs, 1c-obrabotki. Контекст передаётся между инструментами без переделки
- Счётчик изменений внизу — видно общую статистику по проекту в реальном времени
Этот подход — «автономный исполнитель» — сильная сторона Codex. На Claude мы бы тратили больше времени на подтверждения каждого шага. На Codex — задача просто едет вперёд.
Шаг 4. Codex отчитывается — 35 файлов, 11 тестов, всё в базе
Через два часа работы Codex выдаёт финальный отчёт. С разделом «честные ограничения» — что получилось, что не дотянули, почему.
35файлов изменено +1378строк добавлено −512строк удалено 497 → 444диагностик BSL LS 2031 → 924строк в форме 11/11тестов passed
Развернуть финальный отчёт Codex (без редактуры)
Что готово
- Создал ТЗ: TZ_QUALITY_REFACTOR_TESTS.md
- Прогнал BSL LS: было 497 диагностик, стало 444, Warning стало 0. По MAJOR/CRITICAL целевые проблемы закрыты
- Вынес серверную логику формы в общий модуль VibeCRMСервер
- Добавил общие модули VibeCRMСервер, VibeCRMКлиент, VibeCRMПовтИсп
- Форма уменьшилась с 2031 до 924 строк, вынесено 57 процедур/функций
- Добавил тесты в Smoke (общий модуль Smoke_VibeCRMБизнесЛогика)
- Запустил YAxUnit через платформу: 11/11 тестов прошли, ошибок нет
Проверка базы
- Основная конфигурация загружена и обновлена в базе
- Расширения YAXUNIT и Smoke активны
- ibcmd check -e Smoke прошёл успешно
- ibcmd check -e YAXUNIT прошёл успешно
- MCP parse_junit_report подтвердил: total 11, passed 11, failed 0, errors 0
Честные ограничения
- Цель «форма ≤ 700 строк» пока не достигнута: осталось около 924 строк. Основная серверная логика вынесена, но в форме ещё остались клиентские обработчики и UI-состояние
- Коммиты не сделал, потому что папка проекта не является git-репозиторием. Это закрывается отдельно — см. статью «Git для 1С-разработчика»
- Для запуска тестов пришлось сделать runtime-зеркало тестовых модулей: в файловой базе расширение YAXUNIT не видит модули соседнего расширения Smoke. Зафиксировано в отчёте
Самое ценное в этом отчёте — раздел «честные ограничения». Codex не врёт, что «всё идеально». Цель «форма ≤700 строк» не достигнута — он честно пишет 924. Эту разницу легко закрыть отдельной итерацией. Но сама привычка отчитываться без приукрашивания — то, чего часто не хватает живым подрядчикам.
Что мы поняли из кейса — где сильнее каждый
Четыре часа на конкретной конфигурации показали профили обоих инструментов яснее любой абстрактной теории.
- Параметр — Claude Code — Codex
- Подход к работе — Диалоговый, план + подтверждение, объясняет каждый шаг — Автономный, длинные шаги, прогресс-чеклист, итоговый отчёт
- Сильная сторона — Анализ, постановка задач, написание ТЗ, рефакторинг с пониманием контекста — Длинная автономная реализация, тесты, интеграции, бэклог
- Контекстное окно — До 1 млн токенов на Opus (≈1000+ файлов BSL) — До 400 тыс токенов (≈400 файлов BSL)
- Где удобнее — Большие конфигурации (УТ, ERP), code review, осторожный рефакторинг — Пакетная рутина, типовые обработки, автотесты, CI-задачи
- Подписка от — $20/мес (Anthropic Pro), $100/мес (Max) — $20/мес (ChatGPT Plus), $200/мес (Pro)
- API оплата — Обычно 1500–8000 ₽/мес на разработчика — Обычно 1500–8000 ₽/мес на разработчика
- MCP-серверы — Поддерживаются (MCP — стандарт от Anthropic) — Поддерживаются
- Аналитик/методолог 1С — Подходит — диалоговый стиль помогает не-программисту — Подходит для типовой рутины — описал, получил готовое
Главный вывод кейса: это не «или–или». Это естественное распределение по ролям. Claude — архитектор и аналитик. Codex — реализующий и тестирующий. На реальных проектах в команде имеет смысл иметь оба, оба видят одинаковые MCP-серверы и одинаковый репозиторий.
Не хочется самим разбираться с подписками, VPN, оплатой и подбором инструментов под задачи? Запишитесь на бесплатный диагностический созвон — мы развернём инфраструктуру и научим команду за пять рабочих дней.
Контекстное окно — на что это влияет
Контекстное окно — «оперативная память» AI: сколько кода и документации он удерживает за один диалог. Один токен — примерно 0.7–0.8 русского слова или одна короткая команда BSL.
На небольших задачах размер окна не имеет значения. Если попросили AI исправить баг в одной процедуре — хватит и 50К токенов. Но как только задача затрагивает связанные модули, реквизиты документов, типовые подсистемы — объём контекста начинает быстро расти.
- 200К токенов — около 200 файлов BSL за раз. Хватает для типового расширения, для работы с одной подсистемой.
- 400К токенов (потолок Codex) — около 400 файлов. Уже комфортно для большинства задач, кроме разбора всей конфигурации УТ или ERP.
- 1 млн токенов (потолок Claude Opus) — около 1000+ файлов. Можно «положить в память» всю типовую УТ 11 и работать с ней целостно.
В кейсе VibeCRM (~3500 строк, 9 модулей) разница не ощущалась — оба инструмента вписывались в окно с большим запасом. Разница начинает играть на больших конфигурациях.
Цена и инфраструктура — что платить и за что
Стоимость работы зависит от сценария. Есть два пути.
Подписка через провайдера моделей. Anthropic предлагает Pro ($20/мес) и Max ($100/мес), OpenAI — ChatGPT Plus ($20/мес) и Pro ($200/мес). Подписка удобна для пробы и для одиночных разработчиков. Для команды на боевых проектах подписки часто упираются в дневные лимиты использования.
API-оплата. Платите по фактическому объёму использования. Для активного 1С-разработчика на полноценной нагрузке — примерно 1500–8000 ₽ в месяц. На сложном рефакторинге или работе с типовой ERP — ближе к верхней границе. На рутинных доработках — к нижней.
Цены на API идут вниз с каждым релизом моделей: то, что год назад стоило $15 за миллион входных токенов, сейчас часто стоит $3–5. Эта тенденция, скорее всего, сохранится.
Для России есть нюанс. Подписки и API оплачиваются в долларах через зарубежные карты. Дополнительно нужен VPN — оба сервиса в РФ напрямую недоступны без него. На пилоте B2C мы решаем эту инфраструктурную часть «под ключ»: поднимаем VPN-сервер, подключаем платёжный канал, оформляем подписки или API-доступ.
MCP — общий стандарт, делает выбор не критичным
MCP (Model Context Protocol) — открытый протокол, через который AI-агенты получают доступ к внешним источникам данных: вашей конфигурации 1С, документации платформы, библиотеке готовых решений. И Claude Code, и Codex умеют с ним работать.
Это снимает классическое опасение «привязки к экосистеме». Если сегодня вы выбрали Claude, а через год хотите перейти на Codex — MCP-серверы остаются те же. AI-агент меняется, контекст для него — нет. Миграция между инструментами занимает рабочий день.
В нашем кейсе VibeCRM это видно прямо на скриншотах: оба инструмента дёргают одинаковые серверы (1c-metadata, 1c-edt-docs, 1c-testing, 1c-obrabotki). Контекст, который собрал Claude в шаге 1, был доступен Codex в шаге 3 без перенастройки.
Подробнее про MCP — в отдельной статье «Что такое MCP-сервер и зачем он 1С-разработчику».
Как мы выбираем для клиента на пилоте
На диагностическом созвоне перед стартом пилота мы смотрим на четыре фактора:
- Размер команды и состав. Маленькая команда (1–3 разработчика) — обычно один инструмент. Команда 5+ — часто оба, чтобы каждый разработчик использовал то, что удобнее под его задачи.
- Какие задачи в работе. Если в бэклоге много рутины и интеграций — стартуем с Codex. Если в основном крупные доработки типовых конфигураций и рефакторинг — с Claude Code.
- Чувствительность данных. Если в коде нет ничего критичного — облачные модели (Codex или Claude). Если есть требования по безопасности (банк, госструктура, чувствительные данные) — переходим на локальные модели, см. отдельную статью «Локальные AI-модели для 1С».
- Что уже есть в команде. Если кто-то уже работает с одним из инструментов и им комфортно — оставляем его как основной, второй добавляем по запросу.
В большинстве случаев на старте мы рекомендуем связку Claude (анализ + ТЗ) + Codex (реализация + тесты) — ровно как в кейсе VibeCRM выше. План-перед-действием снижает страх у разработчиков, которые впервые работают с AI-агентом, а автономная реализация ускоряет рутину.
Решение фиксируется в плане пилота до старта недели внедрения. Никаких сюрпризов в процессе.
Часто задаваемые вопросы
- Что лучше — Codex или Claude Code?Лучше тот, который вы попробовали и который удобен команде. Технически оба решают одни и те же задачи. На больших конфигурациях небольшое преимущество у Claude из-за 1 миллиона токенов на Opus. На пакетной автономной рутине часто удобнее Codex.В нашей практике мы используем оба — и распределяем по ролям. Claude — анализ, постановка задач, рефакторинг. Codex — реализация и тесты. Кейс VibeCRM выше показывает этот сценарий целиком.
- Можно ли использовать оба одновременно?Да, мы у себя так и работаем. Один разработчик может вести задачу в Claude Code и параллельно решать другую в Codex. Оба видят одинаковые MCP-серверы и одинаковый репозиторий.Это удобно: вы можете попробовать оба инструмента в течение недели, выбрать основной, а второй держать про запас или для конкретного типа задач.
- Можно ли работать из России?Да, нужны два технических условия. Первое — стабильный VPN с выходом в страны, где работают серверы OpenAI и Anthropic (оба сервиса в РФ напрямую недоступны). Второе — зарубежная банковская карта для оплаты подписки или API-баланса. Российские карты ни тот, ни другой провайдер не принимают.На пилоте мы у себя решаем оба пункта: поднимаем VPN под клиента и подключаем платёжный канал. Клиент получает готовую рабочую инфраструктуру.
- Сколько это стоит на команду из 5 разработчиков?Подписочный вариант: от $100/мес (5 × Pro) до $500/мес (5 × Max). API-вариант: 7–30 тыс ₽/мес на всю команду, чаще около 15 тыс ₽.На пилотную неделю мы покрываем все расходы по AI из своей стороны — клиент платит за работу инструментов уже после окончания пилота, когда видит, что это даёт.
- Это безопасно? Код уходит в OpenAI или Anthropic?При работе через API оба провайдера явно гарантируют, что отправленные запросы не используются для обучения моделей — это прописано в их пользовательских соглашениях для API. Защита уровня SOC 2 и ISO 27001.Для случаев, когда даже это неприемлемо (банки, госструктуры, особо чувствительные данные) — переход на локальные модели. Качество кода чуть ниже, но код вообще не покидает ваш контур. Подробнее — в статье «Локальные AI-модели для 1С».
- Какие конкретно модели использовать?У Anthropic: Claude Sonnet серии 4.6 на повседневных задачах, Claude Opus серии 4.6/4.7 — на сложных и больших (полный 1М контекста, более качественные ответы).У OpenAI: GPT-5 как универсальная модель, GPT-5-Codex — для длинных автономных задач в коде, когда не хочется на каждый шаг подтверждать.В обоих случаях Claude Code или Codex сами выбирают, какую модель применить, исходя из задачи. Вмешиваться в это вручную обычно не нужно.
- Что если OpenAI или Anthropic поднимут цены?Цены на API идут вниз почти с каждым крупным релизом моделей — конкуренция жёсткая. Если кардинально вырастут (что маловероятно), миграция между инструментами занимает рабочий день — MCP-серверы и репозиторий остаются те же.Альтернатива на крайний случай — переход на локальные модели (Qwen-Coder, DeepSeek-Coder), которые после установки не требуют ежемесячной оплаты.
- Нужно ли учить английский, чтобы работать с этими инструментами?Нет. Оба инструмента понимают русский, отвечают на русском и работают с русскими названиями реквизитов, регистров и процедур в 1С — это самое важное для отечественной разработки. В кейсе VibeCRM выше всё общение с обоими AI шло на русском.Английский нужен только для чтения официальной документации провайдеров, но в большинстве случаев достаточно русскоязычных гайдов и нашего обучения на пилоте.
- Codex — это CLI или десктоп-приложение?Сейчас Codex существует как нативное десктоп-приложение от OpenAI (Mac, Windows). Раньше был только Codex CLI в терминале — он тоже работает, но десктоп-версия удобнее для большинства задач: визуальный прогресс-чеклист, артефакты в боковой панели, удобный просмотр diff'ов.На скриншотах в этой статье — именно десктоп-приложение. Промпты и MCP-серверы в обоих вариантах одинаковые.
- Подходит ли это аналитику или методологу 1С, который сам не программирует?Да, и для них это часто даже сильнее, чем для программистов. Аналитик хорошо понимает что нужно, но не умеет сам реализовать. С Claude (диалоговый стиль, план перед действием) или Codex (автономная реализация по описанию) аналитик может сам делать прототипы и простые доработки — не дёргая программиста по каждой мелочи.На пилоте мы отдельно показываем сценарии для аналитиков: как ставить задачу, как читать результат, как проверять.
Подобрать стек под вашу команду
На бесплатном диагностическом созвоне мы разбираем именно вашу ситуацию: размер команды, типовые задачи, чувствительность данных, бюджет. Дальше — конкретные рекомендации по инструментам и инфраструктуре. Цена пилота — меньше месячной зарплаты одного 1С-программиста в Москве, окупается сразу.
В этой серии 10 статей о AI-разработке 1С
- Codex и Claude Code — два AI-инструмента, кейс VibeCRM
- Что такое MCP-сервер и зачем он 1С-разработчику
- Как мы за 5 месяцев перевели свою 1С-разработку на AI
- Как правильно ставить задачу AI-агенту для 1С
- 7 страхов руководителя про AI-разработку 1С
- 1С:EDT и почему без него AI бесполезен
- Git для 1С-разработчика — основа AI-разработки
- Локальные AI-модели для 1С (без отправки кода в облако)
- 10 готовых промптов для 1С-разработчика
Источники
- docs.anthropic.com — официальная документация Claude Code
- developers.openai.com — официальная документация Codex
- modelcontextprotocol.io — спецификация Model Context Protocol
- anthropic.com/pricing, openai.com/api/pricing — актуальные цены подписок и API
- github.com/1c-syntax/bsl-language-server — BSL Language Server (180 диагностик, использовались в кейсе)
- Внутренний кейс команды B2C на конфигурации VibeCRM (май 2026)
Обновлено: май 2026
В этой серии
- AI-разработка 1С простыми словами — читать
- Codex и Claude Code: кейс VibeCRM — вы здесь
- Что такое MCP-сервер и зачем он 1С — читать
- Как ставить задачу ИИ-агенту для 1С — читать
- 7 страхов руководителя про ИИ в 1С — скоро
- 1С:EDT — почему без него ИИ бесполезен — скоро
- Git для 1С-разработчика — скоро
- Локальные ИИ-модели для 1С — скоро
- 10 готовых промптов для 1С-разработчика — скоро
- Тесты в ИИ-разработке: как работают у нас — скоро